This commit is contained in:
@@ -247,19 +247,55 @@ async def register_user(user_create: UserCreate, request: Request):
|
|||||||
@app.post("/api/v1/auth/login", response_model=Token, tags=["Authentication"], summary="Login user")
|
@app.post("/api/v1/auth/login", response_model=Token, tags=["Authentication"], summary="Login user")
|
||||||
async def login_user(user_login: UserLogin, request: Request):
|
async def login_user(user_login: UserLogin, request: Request):
|
||||||
"""Login user"""
|
"""Login user"""
|
||||||
|
client_ip = get_client_ip(request)
|
||||||
|
print(f"Login request from {client_ip}: {user_login.model_dump(exclude={'password'})}")
|
||||||
|
|
||||||
async with httpx.AsyncClient(timeout=30.0) as client:
|
async with httpx.AsyncClient(timeout=30.0) as client:
|
||||||
try:
|
try:
|
||||||
|
login_data = user_login.model_dump()
|
||||||
|
print(f"Sending login data to user service: {login_data}")
|
||||||
|
|
||||||
response = await client.post(
|
response = await client.post(
|
||||||
f"{SERVICES['users']}/api/v1/auth/login",
|
f"{SERVICES['users']}/api/v1/auth/login",
|
||||||
json=user_login.model_dump(),
|
json=login_data,
|
||||||
headers={
|
headers={
|
||||||
"Content-Type": "application/json",
|
"Content-Type": "application/json",
|
||||||
"Accept": "application/json"
|
"Accept": "application/json"
|
||||||
}
|
}
|
||||||
)
|
)
|
||||||
|
|
||||||
|
print(f"User service response: status={response.status_code}")
|
||||||
|
if response.status_code >= 400:
|
||||||
|
print(f"Error response body: {response.text}")
|
||||||
|
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
return response.json()
|
return response.json()
|
||||||
|
elif response.status_code == 422:
|
||||||
|
# Detailed handling for validation errors
|
||||||
|
try:
|
||||||
|
error_json = response.json()
|
||||||
|
print(f"Validation error details: {error_json}")
|
||||||
|
# Return more detailed validation errors
|
||||||
|
if "detail" in error_json:
|
||||||
|
detail = error_json["detail"]
|
||||||
|
if isinstance(detail, list):
|
||||||
|
# FastAPI validation errors
|
||||||
|
formatted_errors = []
|
||||||
|
for error in detail:
|
||||||
|
field = error.get("loc", ["unknown"])[-1]
|
||||||
|
msg = error.get("msg", "Invalid value")
|
||||||
|
formatted_errors.append(f"{field}: {msg}")
|
||||||
|
raise HTTPException(
|
||||||
|
status_code=422,
|
||||||
|
detail=f"Validation errors: {'; '.join(formatted_errors)}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise HTTPException(status_code=422, detail=detail)
|
||||||
|
else:
|
||||||
|
raise HTTPException(status_code=422, detail="Invalid input data")
|
||||||
|
except ValueError as ve:
|
||||||
|
print(f"JSON parse error: {ve}")
|
||||||
|
raise HTTPException(status_code=422, detail="Invalid request format")
|
||||||
else:
|
else:
|
||||||
error_detail = response.text
|
error_detail = response.text
|
||||||
try:
|
try:
|
||||||
@@ -272,6 +308,7 @@ async def login_user(user_login: UserLogin, request: Request):
|
|||||||
except HTTPException:
|
except HTTPException:
|
||||||
raise
|
raise
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
|
print(f"Login service error: {str(e)}")
|
||||||
raise HTTPException(status_code=500, detail=f"Login error: {str(e)}")
|
raise HTTPException(status_code=500, detail=f"Login error: {str(e)}")
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@@ -134,36 +134,65 @@ async def register_user(user_data: UserCreate, db: AsyncSession = Depends(get_db
|
|||||||
@app.post("/api/v1/auth/login", response_model=Token)
|
@app.post("/api/v1/auth/login", response_model=Token)
|
||||||
async def login(user_credentials: UserLogin, db: AsyncSession = Depends(get_db)):
|
async def login(user_credentials: UserLogin, db: AsyncSession = Depends(get_db)):
|
||||||
"""Authenticate user and return token"""
|
"""Authenticate user and return token"""
|
||||||
|
print(f"Login attempt: email={user_credentials.email}, username={user_credentials.username}")
|
||||||
|
|
||||||
|
# Проверка валидности входных данных
|
||||||
|
if not user_credentials.email and not user_credentials.username:
|
||||||
|
print("Error: Neither email nor username provided")
|
||||||
|
raise HTTPException(
|
||||||
|
status_code=status.HTTP_422_UNPROCESSABLE_ENTITY,
|
||||||
|
detail="Either email or username must be provided",
|
||||||
|
)
|
||||||
|
|
||||||
|
if not user_credentials.password:
|
||||||
|
print("Error: Password not provided")
|
||||||
|
raise HTTPException(
|
||||||
|
status_code=status.HTTP_422_UNPROCESSABLE_ENTITY,
|
||||||
|
detail="Password is required",
|
||||||
|
)
|
||||||
|
|
||||||
# Определяем, по какому полю ищем пользователя
|
# Определяем, по какому полю ищем пользователя
|
||||||
user = None
|
user = None
|
||||||
if user_credentials.email:
|
try:
|
||||||
result = await db.execute(select(User).filter(User.email == user_credentials.email))
|
if user_credentials.email:
|
||||||
user = result.scalars().first()
|
print(f"Looking up user by email: {user_credentials.email}")
|
||||||
elif user_credentials.username:
|
result = await db.execute(select(User).filter(User.email == user_credentials.email))
|
||||||
result = await db.execute(select(User).filter(User.username == user_credentials.username))
|
user = result.scalars().first()
|
||||||
user = result.scalars().first()
|
elif user_credentials.username:
|
||||||
else:
|
print(f"Looking up user by username: {user_credentials.username}")
|
||||||
|
result = await db.execute(select(User).filter(User.username == user_credentials.username))
|
||||||
|
user = result.scalars().first()
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Database error during user lookup: {str(e)}")
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_400_BAD_REQUEST,
|
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
|
||||||
detail="Either email or username must be provided",
|
detail="Database error during authentication",
|
||||||
)
|
)
|
||||||
|
|
||||||
# Проверяем наличие пользователя и правильность пароля
|
# Проверяем наличие пользователя и правильность пароля
|
||||||
if not user:
|
if not user:
|
||||||
|
print(f"User not found: email={user_credentials.email}, username={user_credentials.username}")
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_401_UNAUTHORIZED,
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
detail="Incorrect email or password",
|
detail="Incorrect email or password",
|
||||||
)
|
)
|
||||||
|
|
||||||
|
print(f"User found: id={user.id}, email={user.email}")
|
||||||
|
|
||||||
# Проверка пароля
|
# Проверка пароля
|
||||||
try:
|
try:
|
||||||
if not verify_password(user_credentials.password, str(user.password_hash)):
|
password_valid = verify_password(user_credentials.password, str(user.password_hash))
|
||||||
|
print(f"Password verification result: {password_valid}")
|
||||||
|
if not password_valid:
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_401_UNAUTHORIZED,
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
detail="Incorrect email or password",
|
detail="Incorrect email or password",
|
||||||
)
|
)
|
||||||
except Exception:
|
except HTTPException:
|
||||||
|
raise
|
||||||
|
except Exception as e:
|
||||||
# Если произошла ошибка при проверке пароля, то считаем, что пароль неверный
|
# Если произошла ошибка при проверке пароля, то считаем, что пароль неверный
|
||||||
|
print(f"Password verification error: {str(e)}")
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_401_UNAUTHORIZED,
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
detail="Incorrect email or password",
|
detail="Incorrect email or password",
|
||||||
@@ -172,21 +201,25 @@ async def login(user_credentials: UserLogin, db: AsyncSession = Depends(get_db))
|
|||||||
# Проверка активности аккаунта
|
# Проверка активности аккаунта
|
||||||
try:
|
try:
|
||||||
is_active = bool(user.is_active)
|
is_active = bool(user.is_active)
|
||||||
|
print(f"User active status: {is_active}")
|
||||||
if not is_active:
|
if not is_active:
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_401_UNAUTHORIZED,
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
detail="Account is inactive",
|
detail="Account is inactive",
|
||||||
)
|
)
|
||||||
except Exception:
|
except Exception as e:
|
||||||
# Если произошла ошибка при проверке активности, считаем аккаунт активным
|
# Если произошла ошибка при проверке активности, считаем аккаунт активным
|
||||||
|
print(f"Error checking user active status: {str(e)}")
|
||||||
pass
|
pass
|
||||||
|
|
||||||
|
print("Creating access token...")
|
||||||
access_token_expires = timedelta(minutes=settings.ACCESS_TOKEN_EXPIRE_MINUTES)
|
access_token_expires = timedelta(minutes=settings.ACCESS_TOKEN_EXPIRE_MINUTES)
|
||||||
access_token = create_access_token(
|
access_token = create_access_token(
|
||||||
data={"sub": str(user.id), "email": user.email},
|
data={"sub": str(user.id), "email": user.email},
|
||||||
expires_delta=access_token_expires,
|
expires_delta=access_token_expires,
|
||||||
)
|
)
|
||||||
|
|
||||||
|
print("Login successful")
|
||||||
return {"access_token": access_token, "token_type": "bearer"}
|
return {"access_token": access_token, "token_type": "bearer"}
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@@ -108,11 +108,22 @@ class UserLogin(BaseModel):
|
|||||||
@classmethod
|
@classmethod
|
||||||
def validate_password_bytes(cls, v):
|
def validate_password_bytes(cls, v):
|
||||||
"""Ensure password doesn't exceed bcrypt's 72-byte limit."""
|
"""Ensure password doesn't exceed bcrypt's 72-byte limit."""
|
||||||
|
if not v or len(v.strip()) == 0:
|
||||||
|
raise ValueError("Password cannot be empty")
|
||||||
password_bytes = v.encode('utf-8')
|
password_bytes = v.encode('utf-8')
|
||||||
if len(password_bytes) > 72:
|
if len(password_bytes) > 72:
|
||||||
raise ValueError("Password is too long when encoded as UTF-8 (max 72 bytes for bcrypt)")
|
raise ValueError("Password is too long when encoded as UTF-8 (max 72 bytes for bcrypt)")
|
||||||
return v
|
return v
|
||||||
|
|
||||||
|
@field_validator("username")
|
||||||
|
@classmethod
|
||||||
|
def validate_login_fields(cls, v, info):
|
||||||
|
"""Ensure at least email or username is provided."""
|
||||||
|
email = info.data.get('email')
|
||||||
|
if not email and not v:
|
||||||
|
raise ValueError("Either email or username must be provided")
|
||||||
|
return v
|
||||||
|
|
||||||
|
|
||||||
class Token(BaseModel):
|
class Token(BaseModel):
|
||||||
access_token: str
|
access_token: str
|
||||||
|
|||||||
118
test_auth_flow.py
Normal file
118
test_auth_flow.py
Normal file
@@ -0,0 +1,118 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
|
||||||
|
import json
|
||||||
|
import requests
|
||||||
|
import time
|
||||||
|
|
||||||
|
def test_registration_and_login():
|
||||||
|
"""Test registration and login flow"""
|
||||||
|
base_url = "http://localhost:8000"
|
||||||
|
|
||||||
|
# Test user data
|
||||||
|
test_user = {
|
||||||
|
"email": "testuser@example.com",
|
||||||
|
"username": "testuser123",
|
||||||
|
"password": "SecurePass123",
|
||||||
|
"first_name": "Test",
|
||||||
|
"last_name": "User"
|
||||||
|
}
|
||||||
|
|
||||||
|
print("🔧 Creating test user")
|
||||||
|
print("=" * 50)
|
||||||
|
|
||||||
|
# Try to register the user
|
||||||
|
try:
|
||||||
|
headers = {
|
||||||
|
"Content-Type": "application/json",
|
||||||
|
"Accept": "application/json"
|
||||||
|
}
|
||||||
|
|
||||||
|
print(f"Registering user: {test_user['email']}")
|
||||||
|
|
||||||
|
registration_response = requests.post(
|
||||||
|
f"{base_url}/api/v1/auth/register",
|
||||||
|
json=test_user,
|
||||||
|
headers=headers,
|
||||||
|
timeout=10
|
||||||
|
)
|
||||||
|
|
||||||
|
print(f"Registration Status: {registration_response.status_code}")
|
||||||
|
print(f"Registration Response: {registration_response.text}")
|
||||||
|
|
||||||
|
if registration_response.status_code == 200:
|
||||||
|
print("✅ User registered successfully")
|
||||||
|
elif registration_response.status_code == 400:
|
||||||
|
if "already registered" in registration_response.text.lower():
|
||||||
|
print("ℹ️ User already exists, proceeding with login test")
|
||||||
|
else:
|
||||||
|
print(f"❌ Registration failed: {registration_response.text}")
|
||||||
|
return
|
||||||
|
else:
|
||||||
|
print(f"❌ Registration failed with status: {registration_response.status_code}")
|
||||||
|
return
|
||||||
|
|
||||||
|
time.sleep(1)
|
||||||
|
|
||||||
|
# Test login scenarios
|
||||||
|
login_tests = [
|
||||||
|
{
|
||||||
|
"name": "Login with email",
|
||||||
|
"data": {
|
||||||
|
"email": test_user["email"],
|
||||||
|
"password": test_user["password"]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "Login with username",
|
||||||
|
"data": {
|
||||||
|
"username": test_user["username"],
|
||||||
|
"password": test_user["password"]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "Login with wrong password",
|
||||||
|
"data": {
|
||||||
|
"email": test_user["email"],
|
||||||
|
"password": "wrongpassword"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
|
||||||
|
for test in login_tests:
|
||||||
|
print(f"\n🧪 Testing: {test['name']}")
|
||||||
|
print("=" * 50)
|
||||||
|
|
||||||
|
try:
|
||||||
|
print(f"Login data: {json.dumps(test['data'], indent=2)}")
|
||||||
|
|
||||||
|
login_response = requests.post(
|
||||||
|
f"{base_url}/api/v1/auth/login",
|
||||||
|
json=test["data"],
|
||||||
|
headers=headers,
|
||||||
|
timeout=10
|
||||||
|
)
|
||||||
|
|
||||||
|
print(f"Login Status: {login_response.status_code}")
|
||||||
|
print(f"Login Response: {login_response.text}")
|
||||||
|
|
||||||
|
if login_response.status_code == 200:
|
||||||
|
try:
|
||||||
|
token_data = login_response.json()
|
||||||
|
print(f"✅ Login successful! Token type: {token_data.get('token_type')}")
|
||||||
|
print(f"Access token (first 20 chars): {token_data.get('access_token', '')[:20]}...")
|
||||||
|
except:
|
||||||
|
print("✅ Login successful but response parsing failed")
|
||||||
|
else:
|
||||||
|
print(f"❌ Login failed")
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Login error: {str(e)}")
|
||||||
|
|
||||||
|
time.sleep(1)
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Test error: {str(e)}")
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
print("🔍 Testing registration and login flow")
|
||||||
|
test_registration_and_login()
|
||||||
83
test_login.py
Executable file
83
test_login.py
Executable file
@@ -0,0 +1,83 @@
|
|||||||
|
#!/usr/bin/env python3
|
||||||
|
|
||||||
|
import json
|
||||||
|
import requests
|
||||||
|
import time
|
||||||
|
|
||||||
|
# Test login endpoint with detailed logging
|
||||||
|
def test_login():
|
||||||
|
"""Test login with various scenarios"""
|
||||||
|
base_url = "http://localhost:8000"
|
||||||
|
|
||||||
|
# Test cases
|
||||||
|
test_cases = [
|
||||||
|
{
|
||||||
|
"name": "Empty request",
|
||||||
|
"data": {}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "Only password",
|
||||||
|
"data": {"password": "testpass123"}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "Only email",
|
||||||
|
"data": {"email": "test@example.com"}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "Valid email and password",
|
||||||
|
"data": {
|
||||||
|
"email": "test@example.com",
|
||||||
|
"password": "testpass123"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "Valid username and password",
|
||||||
|
"data": {
|
||||||
|
"username": "testuser",
|
||||||
|
"password": "testpass123"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "Invalid JSON format",
|
||||||
|
"data": "invalid json",
|
||||||
|
"content_type": "text/plain"
|
||||||
|
}
|
||||||
|
]
|
||||||
|
|
||||||
|
for test_case in test_cases:
|
||||||
|
print(f"\n🧪 Testing: {test_case['name']}")
|
||||||
|
print("=" * 50)
|
||||||
|
|
||||||
|
try:
|
||||||
|
headers = {
|
||||||
|
"Content-Type": test_case.get("content_type", "application/json"),
|
||||||
|
"Accept": "application/json"
|
||||||
|
}
|
||||||
|
|
||||||
|
if isinstance(test_case["data"], dict):
|
||||||
|
data = json.dumps(test_case["data"])
|
||||||
|
print(f"Request data: {data}")
|
||||||
|
else:
|
||||||
|
data = test_case["data"]
|
||||||
|
print(f"Request data (raw): {data}")
|
||||||
|
|
||||||
|
response = requests.post(
|
||||||
|
f"{base_url}/api/v1/auth/login",
|
||||||
|
data=data,
|
||||||
|
headers=headers,
|
||||||
|
timeout=10
|
||||||
|
)
|
||||||
|
|
||||||
|
print(f"Status Code: {response.status_code}")
|
||||||
|
print(f"Headers: {dict(response.headers)}")
|
||||||
|
print(f"Response: {response.text}")
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Error: {str(e)}")
|
||||||
|
|
||||||
|
time.sleep(1) # Wait between requests
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
print("🔍 Testing login endpoint with detailed logging")
|
||||||
|
print("Make sure to check the server logs for debugging info")
|
||||||
|
test_login()
|
||||||
8
venv/bin/normalizer
Executable file
8
venv/bin/normalizer
Executable file
@@ -0,0 +1,8 @@
|
|||||||
|
#!/home/trevor/dev/chat/venv/bin/python
|
||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
import re
|
||||||
|
import sys
|
||||||
|
from charset_normalizer.cli import cli_detect
|
||||||
|
if __name__ == '__main__':
|
||||||
|
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
|
||||||
|
sys.exit(cli_detect())
|
||||||
@@ -0,0 +1 @@
|
|||||||
|
pip
|
||||||
@@ -0,0 +1,750 @@
|
|||||||
|
Metadata-Version: 2.4
|
||||||
|
Name: charset-normalizer
|
||||||
|
Version: 3.4.3
|
||||||
|
Summary: The Real First Universal Charset Detector. Open, modern and actively maintained alternative to Chardet.
|
||||||
|
Author-email: "Ahmed R. TAHRI" <tahri.ahmed@proton.me>
|
||||||
|
Maintainer-email: "Ahmed R. TAHRI" <tahri.ahmed@proton.me>
|
||||||
|
License: MIT
|
||||||
|
Project-URL: Changelog, https://github.com/jawah/charset_normalizer/blob/master/CHANGELOG.md
|
||||||
|
Project-URL: Documentation, https://charset-normalizer.readthedocs.io/
|
||||||
|
Project-URL: Code, https://github.com/jawah/charset_normalizer
|
||||||
|
Project-URL: Issue tracker, https://github.com/jawah/charset_normalizer/issues
|
||||||
|
Keywords: encoding,charset,charset-detector,detector,normalization,unicode,chardet,detect
|
||||||
|
Classifier: Development Status :: 5 - Production/Stable
|
||||||
|
Classifier: Intended Audience :: Developers
|
||||||
|
Classifier: Operating System :: OS Independent
|
||||||
|
Classifier: Programming Language :: Python
|
||||||
|
Classifier: Programming Language :: Python :: 3
|
||||||
|
Classifier: Programming Language :: Python :: 3.7
|
||||||
|
Classifier: Programming Language :: Python :: 3.8
|
||||||
|
Classifier: Programming Language :: Python :: 3.9
|
||||||
|
Classifier: Programming Language :: Python :: 3.10
|
||||||
|
Classifier: Programming Language :: Python :: 3.11
|
||||||
|
Classifier: Programming Language :: Python :: 3.12
|
||||||
|
Classifier: Programming Language :: Python :: 3.13
|
||||||
|
Classifier: Programming Language :: Python :: 3.14
|
||||||
|
Classifier: Programming Language :: Python :: 3 :: Only
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: CPython
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
||||||
|
Classifier: Topic :: Text Processing :: Linguistic
|
||||||
|
Classifier: Topic :: Utilities
|
||||||
|
Classifier: Typing :: Typed
|
||||||
|
Requires-Python: >=3.7
|
||||||
|
Description-Content-Type: text/markdown
|
||||||
|
License-File: LICENSE
|
||||||
|
Provides-Extra: unicode-backport
|
||||||
|
Dynamic: license-file
|
||||||
|
|
||||||
|
<h1 align="center">Charset Detection, for Everyone 👋</h1>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<sup>The Real First Universal Charset Detector</sup><br>
|
||||||
|
<a href="https://pypi.org/project/charset-normalizer">
|
||||||
|
<img src="https://img.shields.io/pypi/pyversions/charset_normalizer.svg?orange=blue" />
|
||||||
|
</a>
|
||||||
|
<a href="https://pepy.tech/project/charset-normalizer/">
|
||||||
|
<img alt="Download Count Total" src="https://static.pepy.tech/badge/charset-normalizer/month" />
|
||||||
|
</a>
|
||||||
|
<a href="https://bestpractices.coreinfrastructure.org/projects/7297">
|
||||||
|
<img src="https://bestpractices.coreinfrastructure.org/projects/7297/badge">
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
<p align="center">
|
||||||
|
<sup><i>Featured Packages</i></sup><br>
|
||||||
|
<a href="https://github.com/jawah/niquests">
|
||||||
|
<img alt="Static Badge" src="https://img.shields.io/badge/Niquests-Most_Advanced_HTTP_Client-cyan">
|
||||||
|
</a>
|
||||||
|
<a href="https://github.com/jawah/wassima">
|
||||||
|
<img alt="Static Badge" src="https://img.shields.io/badge/Wassima-Certifi_Replacement-cyan">
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
<p align="center">
|
||||||
|
<sup><i>In other language (unofficial port - by the community)</i></sup><br>
|
||||||
|
<a href="https://github.com/nickspring/charset-normalizer-rs">
|
||||||
|
<img alt="Static Badge" src="https://img.shields.io/badge/Rust-red">
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
> A library that helps you read text from an unknown charset encoding.<br /> Motivated by `chardet`,
|
||||||
|
> I'm trying to resolve the issue by taking a new approach.
|
||||||
|
> All IANA character set names for which the Python core library provides codecs are supported.
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
>>>>> <a href="https://charsetnormalizerweb.ousret.now.sh" target="_blank">👉 Try Me Online Now, Then Adopt Me 👈 </a> <<<<<
|
||||||
|
</p>
|
||||||
|
|
||||||
|
This project offers you an alternative to **Universal Charset Encoding Detector**, also known as **Chardet**.
|
||||||
|
|
||||||
|
| Feature | [Chardet](https://github.com/chardet/chardet) | Charset Normalizer | [cChardet](https://github.com/PyYoshi/cChardet) |
|
||||||
|
|--------------------------------------------------|:---------------------------------------------:|:--------------------------------------------------------------------------------------------------:|:-----------------------------------------------:|
|
||||||
|
| `Fast` | ❌ | ✅ | ✅ |
|
||||||
|
| `Universal**` | ❌ | ✅ | ❌ |
|
||||||
|
| `Reliable` **without** distinguishable standards | ❌ | ✅ | ✅ |
|
||||||
|
| `Reliable` **with** distinguishable standards | ✅ | ✅ | ✅ |
|
||||||
|
| `License` | LGPL-2.1<br>_restrictive_ | MIT | MPL-1.1<br>_restrictive_ |
|
||||||
|
| `Native Python` | ✅ | ✅ | ❌ |
|
||||||
|
| `Detect spoken language` | ❌ | ✅ | N/A |
|
||||||
|
| `UnicodeDecodeError Safety` | ❌ | ✅ | ❌ |
|
||||||
|
| `Whl Size (min)` | 193.6 kB | 42 kB | ~200 kB |
|
||||||
|
| `Supported Encoding` | 33 | 🎉 [99](https://charset-normalizer.readthedocs.io/en/latest/user/support.html#supported-encodings) | 40 |
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://i.imgflip.com/373iay.gif" alt="Reading Normalized Text" width="226"/><img src="https://media.tenor.com/images/c0180f70732a18b4965448d33adba3d0/tenor.gif" alt="Cat Reading Text" width="200"/>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
*\*\* : They are clearly using specific code for a specific encoding even if covering most of used one*<br>
|
||||||
|
|
||||||
|
## ⚡ Performance
|
||||||
|
|
||||||
|
This package offer better performance than its counterpart Chardet. Here are some numbers.
|
||||||
|
|
||||||
|
| Package | Accuracy | Mean per file (ms) | File per sec (est) |
|
||||||
|
|-----------------------------------------------|:--------:|:------------------:|:------------------:|
|
||||||
|
| [chardet](https://github.com/chardet/chardet) | 86 % | 63 ms | 16 file/sec |
|
||||||
|
| charset-normalizer | **98 %** | **10 ms** | 100 file/sec |
|
||||||
|
|
||||||
|
| Package | 99th percentile | 95th percentile | 50th percentile |
|
||||||
|
|-----------------------------------------------|:---------------:|:---------------:|:---------------:|
|
||||||
|
| [chardet](https://github.com/chardet/chardet) | 265 ms | 71 ms | 7 ms |
|
||||||
|
| charset-normalizer | 100 ms | 50 ms | 5 ms |
|
||||||
|
|
||||||
|
_updated as of december 2024 using CPython 3.12_
|
||||||
|
|
||||||
|
Chardet's performance on larger file (1MB+) are very poor. Expect huge difference on large payload.
|
||||||
|
|
||||||
|
> Stats are generated using 400+ files using default parameters. More details on used files, see GHA workflows.
|
||||||
|
> And yes, these results might change at any time. The dataset can be updated to include more files.
|
||||||
|
> The actual delays heavily depends on your CPU capabilities. The factors should remain the same.
|
||||||
|
> Keep in mind that the stats are generous and that Chardet accuracy vs our is measured using Chardet initial capability
|
||||||
|
> (e.g. Supported Encoding) Challenge-them if you want.
|
||||||
|
|
||||||
|
## ✨ Installation
|
||||||
|
|
||||||
|
Using pip:
|
||||||
|
|
||||||
|
```sh
|
||||||
|
pip install charset-normalizer -U
|
||||||
|
```
|
||||||
|
|
||||||
|
## 🚀 Basic Usage
|
||||||
|
|
||||||
|
### CLI
|
||||||
|
This package comes with a CLI.
|
||||||
|
|
||||||
|
```
|
||||||
|
usage: normalizer [-h] [-v] [-a] [-n] [-m] [-r] [-f] [-t THRESHOLD]
|
||||||
|
file [file ...]
|
||||||
|
|
||||||
|
The Real First Universal Charset Detector. Discover originating encoding used
|
||||||
|
on text file. Normalize text to unicode.
|
||||||
|
|
||||||
|
positional arguments:
|
||||||
|
files File(s) to be analysed
|
||||||
|
|
||||||
|
optional arguments:
|
||||||
|
-h, --help show this help message and exit
|
||||||
|
-v, --verbose Display complementary information about file if any.
|
||||||
|
Stdout will contain logs about the detection process.
|
||||||
|
-a, --with-alternative
|
||||||
|
Output complementary possibilities if any. Top-level
|
||||||
|
JSON WILL be a list.
|
||||||
|
-n, --normalize Permit to normalize input file. If not set, program
|
||||||
|
does not write anything.
|
||||||
|
-m, --minimal Only output the charset detected to STDOUT. Disabling
|
||||||
|
JSON output.
|
||||||
|
-r, --replace Replace file when trying to normalize it instead of
|
||||||
|
creating a new one.
|
||||||
|
-f, --force Replace file without asking if you are sure, use this
|
||||||
|
flag with caution.
|
||||||
|
-t THRESHOLD, --threshold THRESHOLD
|
||||||
|
Define a custom maximum amount of chaos allowed in
|
||||||
|
decoded content. 0. <= chaos <= 1.
|
||||||
|
--version Show version information and exit.
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
normalizer ./data/sample.1.fr.srt
|
||||||
|
```
|
||||||
|
|
||||||
|
or
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python -m charset_normalizer ./data/sample.1.fr.srt
|
||||||
|
```
|
||||||
|
|
||||||
|
🎉 Since version 1.4.0 the CLI produce easily usable stdout result in JSON format.
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"path": "/home/default/projects/charset_normalizer/data/sample.1.fr.srt",
|
||||||
|
"encoding": "cp1252",
|
||||||
|
"encoding_aliases": [
|
||||||
|
"1252",
|
||||||
|
"windows_1252"
|
||||||
|
],
|
||||||
|
"alternative_encodings": [
|
||||||
|
"cp1254",
|
||||||
|
"cp1256",
|
||||||
|
"cp1258",
|
||||||
|
"iso8859_14",
|
||||||
|
"iso8859_15",
|
||||||
|
"iso8859_16",
|
||||||
|
"iso8859_3",
|
||||||
|
"iso8859_9",
|
||||||
|
"latin_1",
|
||||||
|
"mbcs"
|
||||||
|
],
|
||||||
|
"language": "French",
|
||||||
|
"alphabets": [
|
||||||
|
"Basic Latin",
|
||||||
|
"Latin-1 Supplement"
|
||||||
|
],
|
||||||
|
"has_sig_or_bom": false,
|
||||||
|
"chaos": 0.149,
|
||||||
|
"coherence": 97.152,
|
||||||
|
"unicode_path": null,
|
||||||
|
"is_preferred": true
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### Python
|
||||||
|
*Just print out normalized text*
|
||||||
|
```python
|
||||||
|
from charset_normalizer import from_path
|
||||||
|
|
||||||
|
results = from_path('./my_subtitle.srt')
|
||||||
|
|
||||||
|
print(str(results.best()))
|
||||||
|
```
|
||||||
|
|
||||||
|
*Upgrade your code without effort*
|
||||||
|
```python
|
||||||
|
from charset_normalizer import detect
|
||||||
|
```
|
||||||
|
|
||||||
|
The above code will behave the same as **chardet**. We ensure that we offer the best (reasonable) BC result possible.
|
||||||
|
|
||||||
|
See the docs for advanced usage : [readthedocs.io](https://charset-normalizer.readthedocs.io/en/latest/)
|
||||||
|
|
||||||
|
## 😇 Why
|
||||||
|
|
||||||
|
When I started using Chardet, I noticed that it was not suited to my expectations, and I wanted to propose a
|
||||||
|
reliable alternative using a completely different method. Also! I never back down on a good challenge!
|
||||||
|
|
||||||
|
I **don't care** about the **originating charset** encoding, because **two different tables** can
|
||||||
|
produce **two identical rendered string.**
|
||||||
|
What I want is to get readable text, the best I can.
|
||||||
|
|
||||||
|
In a way, **I'm brute forcing text decoding.** How cool is that ? 😎
|
||||||
|
|
||||||
|
Don't confuse package **ftfy** with charset-normalizer or chardet. ftfy goal is to repair Unicode string whereas charset-normalizer to convert raw file in unknown encoding to unicode.
|
||||||
|
|
||||||
|
## 🍰 How
|
||||||
|
|
||||||
|
- Discard all charset encoding table that could not fit the binary content.
|
||||||
|
- Measure noise, or the mess once opened (by chunks) with a corresponding charset encoding.
|
||||||
|
- Extract matches with the lowest mess detected.
|
||||||
|
- Additionally, we measure coherence / probe for a language.
|
||||||
|
|
||||||
|
**Wait a minute**, what is noise/mess and coherence according to **YOU ?**
|
||||||
|
|
||||||
|
*Noise :* I opened hundred of text files, **written by humans**, with the wrong encoding table. **I observed**, then
|
||||||
|
**I established** some ground rules about **what is obvious** when **it seems like** a mess (aka. defining noise in rendered text).
|
||||||
|
I know that my interpretation of what is noise is probably incomplete, feel free to contribute in order to
|
||||||
|
improve or rewrite it.
|
||||||
|
|
||||||
|
*Coherence :* For each language there is on earth, we have computed ranked letter appearance occurrences (the best we can). So I thought
|
||||||
|
that intel is worth something here. So I use those records against decoded text to check if I can detect intelligent design.
|
||||||
|
|
||||||
|
## ⚡ Known limitations
|
||||||
|
|
||||||
|
- Language detection is unreliable when text contains two or more languages sharing identical letters. (eg. HTML (english tags) + Turkish content (Sharing Latin characters))
|
||||||
|
- Every charset detector heavily depends on sufficient content. In common cases, do not bother run detection on very tiny content.
|
||||||
|
|
||||||
|
## ⚠️ About Python EOLs
|
||||||
|
|
||||||
|
**If you are running:**
|
||||||
|
|
||||||
|
- Python >=2.7,<3.5: Unsupported
|
||||||
|
- Python 3.5: charset-normalizer < 2.1
|
||||||
|
- Python 3.6: charset-normalizer < 3.1
|
||||||
|
- Python 3.7: charset-normalizer < 4.0
|
||||||
|
|
||||||
|
Upgrade your Python interpreter as soon as possible.
|
||||||
|
|
||||||
|
## 👤 Contributing
|
||||||
|
|
||||||
|
Contributions, issues and feature requests are very much welcome.<br />
|
||||||
|
Feel free to check [issues page](https://github.com/ousret/charset_normalizer/issues) if you want to contribute.
|
||||||
|
|
||||||
|
## 📝 License
|
||||||
|
|
||||||
|
Copyright © [Ahmed TAHRI @Ousret](https://github.com/Ousret).<br />
|
||||||
|
This project is [MIT](https://github.com/Ousret/charset_normalizer/blob/master/LICENSE) licensed.
|
||||||
|
|
||||||
|
Characters frequencies used in this project © 2012 [Denny Vrandečić](http://simia.net/letters/)
|
||||||
|
|
||||||
|
## 💼 For Enterprise
|
||||||
|
|
||||||
|
Professional support for charset-normalizer is available as part of the [Tidelift
|
||||||
|
Subscription][1]. Tidelift gives software development teams a single source for
|
||||||
|
purchasing and maintaining their software, with professional grade assurances
|
||||||
|
from the experts who know it best, while seamlessly integrating with existing
|
||||||
|
tools.
|
||||||
|
|
||||||
|
[1]: https://tidelift.com/subscription/pkg/pypi-charset-normalizer?utm_source=pypi-charset-normalizer&utm_medium=readme
|
||||||
|
|
||||||
|
[](https://www.bestpractices.dev/projects/7297)
|
||||||
|
|
||||||
|
# Changelog
|
||||||
|
All notable changes to charset-normalizer will be documented in this file. This project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
|
||||||
|
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/).
|
||||||
|
|
||||||
|
## [3.4.3](https://github.com/Ousret/charset_normalizer/compare/3.4.2...3.4.3) (2025-08-09)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- mypy(c) is no longer a required dependency at build time if `CHARSET_NORMALIZER_USE_MYPYC` isn't set to `1`. (#595) (#583)
|
||||||
|
- automatically lower confidence on small bytes samples that are not Unicode in `detect` output legacy function. (#391)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Custom build backend to overcome inability to mark mypy as an optional dependency in the build phase.
|
||||||
|
- Support for Python 3.14
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- sdist archive contained useless directories.
|
||||||
|
- automatically fallback on valid UTF-16 or UTF-32 even if the md says it's noisy. (#633)
|
||||||
|
|
||||||
|
### Misc
|
||||||
|
- SBOM are automatically published to the relevant GitHub release to comply with regulatory changes.
|
||||||
|
Each published wheel comes with its SBOM. We choose CycloneDX as the format.
|
||||||
|
- Prebuilt optimized wheel are no longer distributed by default for CPython 3.7 due to a change in cibuildwheel.
|
||||||
|
|
||||||
|
## [3.4.2](https://github.com/Ousret/charset_normalizer/compare/3.4.1...3.4.2) (2025-05-02)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Addressed the DeprecationWarning in our CLI regarding `argparse.FileType` by backporting the target class into the package. (#591)
|
||||||
|
- Improved the overall reliability of the detector with CJK Ideographs. (#605) (#587)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Optional mypyc compilation upgraded to version 1.15 for Python >= 3.8
|
||||||
|
|
||||||
|
## [3.4.1](https://github.com/Ousret/charset_normalizer/compare/3.4.0...3.4.1) (2024-12-24)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Project metadata are now stored using `pyproject.toml` instead of `setup.cfg` using setuptools as the build backend.
|
||||||
|
- Enforce annotation delayed loading for a simpler and consistent types in the project.
|
||||||
|
- Optional mypyc compilation upgraded to version 1.14 for Python >= 3.8
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- pre-commit configuration.
|
||||||
|
- noxfile.
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- `build-requirements.txt` as per using `pyproject.toml` native build configuration.
|
||||||
|
- `bin/integration.py` and `bin/serve.py` in favor of downstream integration test (see noxfile).
|
||||||
|
- `setup.cfg` in favor of `pyproject.toml` metadata configuration.
|
||||||
|
- Unused `utils.range_scan` function.
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Converting content to Unicode bytes may insert `utf_8` instead of preferred `utf-8`. (#572)
|
||||||
|
- Deprecation warning "'count' is passed as positional argument" when converting to Unicode bytes on Python 3.13+
|
||||||
|
|
||||||
|
## [3.4.0](https://github.com/Ousret/charset_normalizer/compare/3.3.2...3.4.0) (2024-10-08)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Argument `--no-preemptive` in the CLI to prevent the detector to search for hints.
|
||||||
|
- Support for Python 3.13 (#512)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Relax the TypeError exception thrown when trying to compare a CharsetMatch with anything else than a CharsetMatch.
|
||||||
|
- Improved the general reliability of the detector based on user feedbacks. (#520) (#509) (#498) (#407) (#537)
|
||||||
|
- Declared charset in content (preemptive detection) not changed when converting to utf-8 bytes. (#381)
|
||||||
|
|
||||||
|
## [3.3.2](https://github.com/Ousret/charset_normalizer/compare/3.3.1...3.3.2) (2023-10-31)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Unintentional memory usage regression when using large payload that match several encoding (#376)
|
||||||
|
- Regression on some detection case showcased in the documentation (#371)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Noise (md) probe that identify malformed arabic representation due to the presence of letters in isolated form (credit to my wife)
|
||||||
|
|
||||||
|
## [3.3.1](https://github.com/Ousret/charset_normalizer/compare/3.3.0...3.3.1) (2023-10-22)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Optional mypyc compilation upgraded to version 1.6.1 for Python >= 3.8
|
||||||
|
- Improved the general detection reliability based on reports from the community
|
||||||
|
|
||||||
|
## [3.3.0](https://github.com/Ousret/charset_normalizer/compare/3.2.0...3.3.0) (2023-09-30)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Allow to execute the CLI (e.g. normalizer) through `python -m charset_normalizer.cli` or `python -m charset_normalizer`
|
||||||
|
- Support for 9 forgotten encoding that are supported by Python but unlisted in `encoding.aliases` as they have no alias (#323)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- (internal) Redundant utils.is_ascii function and unused function is_private_use_only
|
||||||
|
- (internal) charset_normalizer.assets is moved inside charset_normalizer.constant
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- (internal) Unicode code blocks in constants are updated using the latest v15.0.0 definition to improve detection
|
||||||
|
- Optional mypyc compilation upgraded to version 1.5.1 for Python >= 3.8
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Unable to properly sort CharsetMatch when both chaos/noise and coherence were close due to an unreachable condition in \_\_lt\_\_ (#350)
|
||||||
|
|
||||||
|
## [3.2.0](https://github.com/Ousret/charset_normalizer/compare/3.1.0...3.2.0) (2023-06-07)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Typehint for function `from_path` no longer enforce `PathLike` as its first argument
|
||||||
|
- Minor improvement over the global detection reliability
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Introduce function `is_binary` that relies on main capabilities, and optimized to detect binaries
|
||||||
|
- Propagate `enable_fallback` argument throughout `from_bytes`, `from_path`, and `from_fp` that allow a deeper control over the detection (default True)
|
||||||
|
- Explicit support for Python 3.12
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Edge case detection failure where a file would contain 'very-long' camel cased word (Issue #289)
|
||||||
|
|
||||||
|
## [3.1.0](https://github.com/Ousret/charset_normalizer/compare/3.0.1...3.1.0) (2023-03-06)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Argument `should_rename_legacy` for legacy function `detect` and disregard any new arguments without errors (PR #262)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Support for Python 3.6 (PR #260)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Optional speedup provided by mypy/c 1.0.1
|
||||||
|
|
||||||
|
## [3.0.1](https://github.com/Ousret/charset_normalizer/compare/3.0.0...3.0.1) (2022-11-18)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Multi-bytes cutter/chunk generator did not always cut correctly (PR #233)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Speedup provided by mypy/c 0.990 on Python >= 3.7
|
||||||
|
|
||||||
|
## [3.0.0](https://github.com/Ousret/charset_normalizer/compare/2.1.1...3.0.0) (2022-10-20)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Extend the capability of explain=True when cp_isolation contains at most two entries (min one), will log in details of the Mess-detector results
|
||||||
|
- Support for alternative language frequency set in charset_normalizer.assets.FREQUENCIES
|
||||||
|
- Add parameter `language_threshold` in `from_bytes`, `from_path` and `from_fp` to adjust the minimum expected coherence ratio
|
||||||
|
- `normalizer --version` now specify if current version provide extra speedup (meaning mypyc compilation whl)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Build with static metadata using 'build' frontend
|
||||||
|
- Make the language detection stricter
|
||||||
|
- Optional: Module `md.py` can be compiled using Mypyc to provide an extra speedup up to 4x faster than v2.1
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- CLI with opt --normalize fail when using full path for files
|
||||||
|
- TooManyAccentuatedPlugin induce false positive on the mess detection when too few alpha character have been fed to it
|
||||||
|
- Sphinx warnings when generating the documentation
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Coherence detector no longer return 'Simple English' instead return 'English'
|
||||||
|
- Coherence detector no longer return 'Classical Chinese' instead return 'Chinese'
|
||||||
|
- Breaking: Method `first()` and `best()` from CharsetMatch
|
||||||
|
- UTF-7 will no longer appear as "detected" without a recognized SIG/mark (is unreliable/conflict with ASCII)
|
||||||
|
- Breaking: Class aliases CharsetDetector, CharsetDoctor, CharsetNormalizerMatch and CharsetNormalizerMatches
|
||||||
|
- Breaking: Top-level function `normalize`
|
||||||
|
- Breaking: Properties `chaos_secondary_pass`, `coherence_non_latin` and `w_counter` from CharsetMatch
|
||||||
|
- Support for the backport `unicodedata2`
|
||||||
|
|
||||||
|
## [3.0.0rc1](https://github.com/Ousret/charset_normalizer/compare/3.0.0b2...3.0.0rc1) (2022-10-18)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Extend the capability of explain=True when cp_isolation contains at most two entries (min one), will log in details of the Mess-detector results
|
||||||
|
- Support for alternative language frequency set in charset_normalizer.assets.FREQUENCIES
|
||||||
|
- Add parameter `language_threshold` in `from_bytes`, `from_path` and `from_fp` to adjust the minimum expected coherence ratio
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Build with static metadata using 'build' frontend
|
||||||
|
- Make the language detection stricter
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- CLI with opt --normalize fail when using full path for files
|
||||||
|
- TooManyAccentuatedPlugin induce false positive on the mess detection when too few alpha character have been fed to it
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Coherence detector no longer return 'Simple English' instead return 'English'
|
||||||
|
- Coherence detector no longer return 'Classical Chinese' instead return 'Chinese'
|
||||||
|
|
||||||
|
## [3.0.0b2](https://github.com/Ousret/charset_normalizer/compare/3.0.0b1...3.0.0b2) (2022-08-21)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- `normalizer --version` now specify if current version provide extra speedup (meaning mypyc compilation whl)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Breaking: Method `first()` and `best()` from CharsetMatch
|
||||||
|
- UTF-7 will no longer appear as "detected" without a recognized SIG/mark (is unreliable/conflict with ASCII)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Sphinx warnings when generating the documentation
|
||||||
|
|
||||||
|
## [3.0.0b1](https://github.com/Ousret/charset_normalizer/compare/2.1.0...3.0.0b1) (2022-08-15)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Optional: Module `md.py` can be compiled using Mypyc to provide an extra speedup up to 4x faster than v2.1
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Breaking: Class aliases CharsetDetector, CharsetDoctor, CharsetNormalizerMatch and CharsetNormalizerMatches
|
||||||
|
- Breaking: Top-level function `normalize`
|
||||||
|
- Breaking: Properties `chaos_secondary_pass`, `coherence_non_latin` and `w_counter` from CharsetMatch
|
||||||
|
- Support for the backport `unicodedata2`
|
||||||
|
|
||||||
|
## [2.1.1](https://github.com/Ousret/charset_normalizer/compare/2.1.0...2.1.1) (2022-08-19)
|
||||||
|
|
||||||
|
### Deprecated
|
||||||
|
- Function `normalize` scheduled for removal in 3.0
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Removed useless call to decode in fn is_unprintable (#206)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Third-party library (i18n xgettext) crashing not recognizing utf_8 (PEP 263) with underscore from [@aleksandernovikov](https://github.com/aleksandernovikov) (#204)
|
||||||
|
|
||||||
|
## [2.1.0](https://github.com/Ousret/charset_normalizer/compare/2.0.12...2.1.0) (2022-06-19)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Output the Unicode table version when running the CLI with `--version` (PR #194)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Re-use decoded buffer for single byte character sets from [@nijel](https://github.com/nijel) (PR #175)
|
||||||
|
- Fixing some performance bottlenecks from [@deedy5](https://github.com/deedy5) (PR #183)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Workaround potential bug in cpython with Zero Width No-Break Space located in Arabic Presentation Forms-B, Unicode 1.1 not acknowledged as space (PR #175)
|
||||||
|
- CLI default threshold aligned with the API threshold from [@oleksandr-kuzmenko](https://github.com/oleksandr-kuzmenko) (PR #181)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Support for Python 3.5 (PR #192)
|
||||||
|
|
||||||
|
### Deprecated
|
||||||
|
- Use of backport unicodedata from `unicodedata2` as Python is quickly catching up, scheduled for removal in 3.0 (PR #194)
|
||||||
|
|
||||||
|
## [2.0.12](https://github.com/Ousret/charset_normalizer/compare/2.0.11...2.0.12) (2022-02-12)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- ASCII miss-detection on rare cases (PR #170)
|
||||||
|
|
||||||
|
## [2.0.11](https://github.com/Ousret/charset_normalizer/compare/2.0.10...2.0.11) (2022-01-30)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Explicit support for Python 3.11 (PR #164)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- The logging behavior have been completely reviewed, now using only TRACE and DEBUG levels (PR #163 #165)
|
||||||
|
|
||||||
|
## [2.0.10](https://github.com/Ousret/charset_normalizer/compare/2.0.9...2.0.10) (2022-01-04)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fallback match entries might lead to UnicodeDecodeError for large bytes sequence (PR #154)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Skipping the language-detection (CD) on ASCII (PR #155)
|
||||||
|
|
||||||
|
## [2.0.9](https://github.com/Ousret/charset_normalizer/compare/2.0.8...2.0.9) (2021-12-03)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Moderating the logging impact (since 2.0.8) for specific environments (PR #147)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Wrong logging level applied when setting kwarg `explain` to True (PR #146)
|
||||||
|
|
||||||
|
## [2.0.8](https://github.com/Ousret/charset_normalizer/compare/2.0.7...2.0.8) (2021-11-24)
|
||||||
|
### Changed
|
||||||
|
- Improvement over Vietnamese detection (PR #126)
|
||||||
|
- MD improvement on trailing data and long foreign (non-pure latin) data (PR #124)
|
||||||
|
- Efficiency improvements in cd/alphabet_languages from [@adbar](https://github.com/adbar) (PR #122)
|
||||||
|
- call sum() without an intermediary list following PEP 289 recommendations from [@adbar](https://github.com/adbar) (PR #129)
|
||||||
|
- Code style as refactored by Sourcery-AI (PR #131)
|
||||||
|
- Minor adjustment on the MD around european words (PR #133)
|
||||||
|
- Remove and replace SRTs from assets / tests (PR #139)
|
||||||
|
- Initialize the library logger with a `NullHandler` by default from [@nmaynes](https://github.com/nmaynes) (PR #135)
|
||||||
|
- Setting kwarg `explain` to True will add provisionally (bounded to function lifespan) a specific stream handler (PR #135)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fix large (misleading) sequence giving UnicodeDecodeError (PR #137)
|
||||||
|
- Avoid using too insignificant chunk (PR #137)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Add and expose function `set_logging_handler` to configure a specific StreamHandler from [@nmaynes](https://github.com/nmaynes) (PR #135)
|
||||||
|
- Add `CHANGELOG.md` entries, format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/) (PR #141)
|
||||||
|
|
||||||
|
## [2.0.7](https://github.com/Ousret/charset_normalizer/compare/2.0.6...2.0.7) (2021-10-11)
|
||||||
|
### Added
|
||||||
|
- Add support for Kazakh (Cyrillic) language detection (PR #109)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Further, improve inferring the language from a given single-byte code page (PR #112)
|
||||||
|
- Vainly trying to leverage PEP263 when PEP3120 is not supported (PR #116)
|
||||||
|
- Refactoring for potential performance improvements in loops from [@adbar](https://github.com/adbar) (PR #113)
|
||||||
|
- Various detection improvement (MD+CD) (PR #117)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- Remove redundant logging entry about detected language(s) (PR #115)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fix a minor inconsistency between Python 3.5 and other versions regarding language detection (PR #117 #102)
|
||||||
|
|
||||||
|
## [2.0.6](https://github.com/Ousret/charset_normalizer/compare/2.0.5...2.0.6) (2021-09-18)
|
||||||
|
### Fixed
|
||||||
|
- Unforeseen regression with the loss of the backward-compatibility with some older minor of Python 3.5.x (PR #100)
|
||||||
|
- Fix CLI crash when using --minimal output in certain cases (PR #103)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Minor improvement to the detection efficiency (less than 1%) (PR #106 #101)
|
||||||
|
|
||||||
|
## [2.0.5](https://github.com/Ousret/charset_normalizer/compare/2.0.4...2.0.5) (2021-09-14)
|
||||||
|
### Changed
|
||||||
|
- The project now comply with: flake8, mypy, isort and black to ensure a better overall quality (PR #81)
|
||||||
|
- The BC-support with v1.x was improved, the old staticmethods are restored (PR #82)
|
||||||
|
- The Unicode detection is slightly improved (PR #93)
|
||||||
|
- Add syntax sugar \_\_bool\_\_ for results CharsetMatches list-container (PR #91)
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- The project no longer raise warning on tiny content given for detection, will be simply logged as warning instead (PR #92)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- In some rare case, the chunks extractor could cut in the middle of a multi-byte character and could mislead the mess detection (PR #95)
|
||||||
|
- Some rare 'space' characters could trip up the UnprintablePlugin/Mess detection (PR #96)
|
||||||
|
- The MANIFEST.in was not exhaustive (PR #78)
|
||||||
|
|
||||||
|
## [2.0.4](https://github.com/Ousret/charset_normalizer/compare/2.0.3...2.0.4) (2021-07-30)
|
||||||
|
### Fixed
|
||||||
|
- The CLI no longer raise an unexpected exception when no encoding has been found (PR #70)
|
||||||
|
- Fix accessing the 'alphabets' property when the payload contains surrogate characters (PR #68)
|
||||||
|
- The logger could mislead (explain=True) on detected languages and the impact of one MBCS match (PR #72)
|
||||||
|
- Submatch factoring could be wrong in rare edge cases (PR #72)
|
||||||
|
- Multiple files given to the CLI were ignored when publishing results to STDOUT. (After the first path) (PR #72)
|
||||||
|
- Fix line endings from CRLF to LF for certain project files (PR #67)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Adjust the MD to lower the sensitivity, thus improving the global detection reliability (PR #69 #76)
|
||||||
|
- Allow fallback on specified encoding if any (PR #71)
|
||||||
|
|
||||||
|
## [2.0.3](https://github.com/Ousret/charset_normalizer/compare/2.0.2...2.0.3) (2021-07-16)
|
||||||
|
### Changed
|
||||||
|
- Part of the detection mechanism has been improved to be less sensitive, resulting in more accurate detection results. Especially ASCII. (PR #63)
|
||||||
|
- According to the community wishes, the detection will fall back on ASCII or UTF-8 in a last-resort case. (PR #64)
|
||||||
|
|
||||||
|
## [2.0.2](https://github.com/Ousret/charset_normalizer/compare/2.0.1...2.0.2) (2021-07-15)
|
||||||
|
### Fixed
|
||||||
|
- Empty/Too small JSON payload miss-detection fixed. Report from [@tseaver](https://github.com/tseaver) (PR #59)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Don't inject unicodedata2 into sys.modules from [@akx](https://github.com/akx) (PR #57)
|
||||||
|
|
||||||
|
## [2.0.1](https://github.com/Ousret/charset_normalizer/compare/2.0.0...2.0.1) (2021-07-13)
|
||||||
|
### Fixed
|
||||||
|
- Make it work where there isn't a filesystem available, dropping assets frequencies.json. Report from [@sethmlarson](https://github.com/sethmlarson). (PR #55)
|
||||||
|
- Using explain=False permanently disable the verbose output in the current runtime (PR #47)
|
||||||
|
- One log entry (language target preemptive) was not show in logs when using explain=True (PR #47)
|
||||||
|
- Fix undesired exception (ValueError) on getitem of instance CharsetMatches (PR #52)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Public function normalize default args values were not aligned with from_bytes (PR #53)
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- You may now use charset aliases in cp_isolation and cp_exclusion arguments (PR #47)
|
||||||
|
|
||||||
|
## [2.0.0](https://github.com/Ousret/charset_normalizer/compare/1.4.1...2.0.0) (2021-07-02)
|
||||||
|
### Changed
|
||||||
|
- 4x to 5 times faster than the previous 1.4.0 release. At least 2x faster than Chardet.
|
||||||
|
- Accent has been made on UTF-8 detection, should perform rather instantaneous.
|
||||||
|
- The backward compatibility with Chardet has been greatly improved. The legacy detect function returns an identical charset name whenever possible.
|
||||||
|
- The detection mechanism has been slightly improved, now Turkish content is detected correctly (most of the time)
|
||||||
|
- The program has been rewritten to ease the readability and maintainability. (+Using static typing)+
|
||||||
|
- utf_7 detection has been reinstated.
|
||||||
|
|
||||||
|
### Removed
|
||||||
|
- This package no longer require anything when used with Python 3.5 (Dropped cached_property)
|
||||||
|
- Removed support for these languages: Catalan, Esperanto, Kazakh, Baque, Volapük, Azeri, Galician, Nynorsk, Macedonian, and Serbocroatian.
|
||||||
|
- The exception hook on UnicodeDecodeError has been removed.
|
||||||
|
|
||||||
|
### Deprecated
|
||||||
|
- Methods coherence_non_latin, w_counter, chaos_secondary_pass of the class CharsetMatch are now deprecated and scheduled for removal in v3.0
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- The CLI output used the relative path of the file(s). Should be absolute.
|
||||||
|
|
||||||
|
## [1.4.1](https://github.com/Ousret/charset_normalizer/compare/1.4.0...1.4.1) (2021-05-28)
|
||||||
|
### Fixed
|
||||||
|
- Logger configuration/usage no longer conflict with others (PR #44)
|
||||||
|
|
||||||
|
## [1.4.0](https://github.com/Ousret/charset_normalizer/compare/1.3.9...1.4.0) (2021-05-21)
|
||||||
|
### Removed
|
||||||
|
- Using standard logging instead of using the package loguru.
|
||||||
|
- Dropping nose test framework in favor of the maintained pytest.
|
||||||
|
- Choose to not use dragonmapper package to help with gibberish Chinese/CJK text.
|
||||||
|
- Require cached_property only for Python 3.5 due to constraint. Dropping for every other interpreter version.
|
||||||
|
- Stop support for UTF-7 that does not contain a SIG.
|
||||||
|
- Dropping PrettyTable, replaced with pure JSON output in CLI.
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- BOM marker in a CharsetNormalizerMatch instance could be False in rare cases even if obviously present. Due to the sub-match factoring process.
|
||||||
|
- Not searching properly for the BOM when trying utf32/16 parent codec.
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Improving the package final size by compressing frequencies.json.
|
||||||
|
- Huge improvement over the larges payload.
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- CLI now produces JSON consumable output.
|
||||||
|
- Return ASCII if given sequences fit. Given reasonable confidence.
|
||||||
|
|
||||||
|
## [1.3.9](https://github.com/Ousret/charset_normalizer/compare/1.3.8...1.3.9) (2021-05-13)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- In some very rare cases, you may end up getting encode/decode errors due to a bad bytes payload (PR #40)
|
||||||
|
|
||||||
|
## [1.3.8](https://github.com/Ousret/charset_normalizer/compare/1.3.7...1.3.8) (2021-05-12)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Empty given payload for detection may cause an exception if trying to access the `alphabets` property. (PR #39)
|
||||||
|
|
||||||
|
## [1.3.7](https://github.com/Ousret/charset_normalizer/compare/1.3.6...1.3.7) (2021-05-12)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- The legacy detect function should return UTF-8-SIG if sig is present in the payload. (PR #38)
|
||||||
|
|
||||||
|
## [1.3.6](https://github.com/Ousret/charset_normalizer/compare/1.3.5...1.3.6) (2021-02-09)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Amend the previous release to allow prettytable 2.0 (PR #35)
|
||||||
|
|
||||||
|
## [1.3.5](https://github.com/Ousret/charset_normalizer/compare/1.3.4...1.3.5) (2021-02-08)
|
||||||
|
|
||||||
|
### Fixed
|
||||||
|
- Fix error while using the package with a python pre-release interpreter (PR #33)
|
||||||
|
|
||||||
|
### Changed
|
||||||
|
- Dependencies refactoring, constraints revised.
|
||||||
|
|
||||||
|
### Added
|
||||||
|
- Add python 3.9 and 3.10 to the supported interpreters
|
||||||
|
|
||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2025 TAHRI Ahmed R.
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
@@ -0,0 +1,35 @@
|
|||||||
|
../../../bin/normalizer,sha256=ezCIXGT5rnoJrfVhJ8DjH9QciCCjdjmtIH6AACYQ5d4,254
|
||||||
|
charset_normalizer-3.4.3.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
||||||
|
charset_normalizer-3.4.3.dist-info/METADATA,sha256=nBNOskPUtcqHtaSPPaJafjXrlicPcPIgLFzpJQTgvaA,36700
|
||||||
|
charset_normalizer-3.4.3.dist-info/RECORD,,
|
||||||
|
charset_normalizer-3.4.3.dist-info/WHEEL,sha256=DxRnWQz-Kp9-4a4hdDHsSv0KUC3H7sN9Nbef3-8RjXU,190
|
||||||
|
charset_normalizer-3.4.3.dist-info/entry_points.txt,sha256=ADSTKrkXZ3hhdOVFi6DcUEHQRS0xfxDIE_pEz4wLIXA,65
|
||||||
|
charset_normalizer-3.4.3.dist-info/licenses/LICENSE,sha256=bQ1Bv-FwrGx9wkjJpj4lTQ-0WmDVCoJX0K-SxuJJuIc,1071
|
||||||
|
charset_normalizer-3.4.3.dist-info/top_level.txt,sha256=7ASyzePr8_xuZWJsnqJjIBtyV8vhEo0wBCv1MPRRi3Q,19
|
||||||
|
charset_normalizer/__init__.py,sha256=OKRxRv2Zhnqk00tqkN0c1BtJjm165fWXLydE52IKuHc,1590
|
||||||
|
charset_normalizer/__main__.py,sha256=yzYxMR-IhKRHYwcSlavEv8oGdwxsR89mr2X09qXGdps,109
|
||||||
|
charset_normalizer/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/__main__.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/api.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/cd.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/constant.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/legacy.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/md.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/models.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/utils.cpython-312.pyc,,
|
||||||
|
charset_normalizer/__pycache__/version.cpython-312.pyc,,
|
||||||
|
charset_normalizer/api.py,sha256=V07i8aVeCD8T2fSia3C-fn0i9t8qQguEBhsqszg32Ns,22668
|
||||||
|
charset_normalizer/cd.py,sha256=WKTo1HDb-H9HfCDc3Bfwq5jzS25Ziy9SE2a74SgTq88,12522
|
||||||
|
charset_normalizer/cli/__init__.py,sha256=D8I86lFk2-py45JvqxniTirSj_sFyE6sjaY_0-G1shc,136
|
||||||
|
charset_normalizer/cli/__main__.py,sha256=dMaXG6IJXRvqq8z2tig7Qb83-BpWTln55ooiku5_uvg,12646
|
||||||
|
charset_normalizer/cli/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
charset_normalizer/cli/__pycache__/__main__.cpython-312.pyc,,
|
||||||
|
charset_normalizer/constant.py,sha256=7UVY4ldYhmQMHUdgQ_sgZmzcQ0xxYxpBunqSZ-XJZ8U,42713
|
||||||
|
charset_normalizer/legacy.py,sha256=sYBzSpzsRrg_wF4LP536pG64BItw7Tqtc3SMQAHvFLM,2731
|
||||||
|
charset_normalizer/md.cpython-312-x86_64-linux-gnu.so,sha256=sZ7umtJLjKfA83NFJ7npkiDyr06zDT8cWtl6uIx2MsM,15912
|
||||||
|
charset_normalizer/md.py,sha256=-_oN3h3_X99nkFfqamD3yu45DC_wfk5odH0Tr_CQiXs,20145
|
||||||
|
charset_normalizer/md__mypyc.cpython-312-x86_64-linux-gnu.so,sha256=froFxeWX3QD-u-6lU-1gyOZmEo6pgm3i-HdUWz2J8ro,289536
|
||||||
|
charset_normalizer/models.py,sha256=lKXhOnIPtiakbK3i__J9wpOfzx3JDTKj7Dn3Rg0VaRI,12394
|
||||||
|
charset_normalizer/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
||||||
|
charset_normalizer/utils.py,sha256=sTejPgrdlNsKNucZfJCxJ95lMTLA0ShHLLE3n5wpT9Q,12170
|
||||||
|
charset_normalizer/version.py,sha256=hBN3id1io4HMVPtyDn9IIRVShbBM0kgVs3haVtppZOE,115
|
||||||
@@ -0,0 +1,7 @@
|
|||||||
|
Wheel-Version: 1.0
|
||||||
|
Generator: setuptools (80.9.0)
|
||||||
|
Root-Is-Purelib: false
|
||||||
|
Tag: cp312-cp312-manylinux_2_17_x86_64
|
||||||
|
Tag: cp312-cp312-manylinux2014_x86_64
|
||||||
|
Tag: cp312-cp312-manylinux_2_28_x86_64
|
||||||
|
|
||||||
@@ -0,0 +1,2 @@
|
|||||||
|
[console_scripts]
|
||||||
|
normalizer = charset_normalizer.cli:cli_detect
|
||||||
@@ -0,0 +1,21 @@
|
|||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2025 TAHRI Ahmed R.
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
@@ -0,0 +1 @@
|
|||||||
|
charset_normalizer
|
||||||
@@ -0,0 +1,48 @@
|
|||||||
|
"""
|
||||||
|
Charset-Normalizer
|
||||||
|
~~~~~~~~~~~~~~
|
||||||
|
The Real First Universal Charset Detector.
|
||||||
|
A library that helps you read text from an unknown charset encoding.
|
||||||
|
Motivated by chardet, This package is trying to resolve the issue by taking a new approach.
|
||||||
|
All IANA character set names for which the Python core library provides codecs are supported.
|
||||||
|
|
||||||
|
Basic usage:
|
||||||
|
>>> from charset_normalizer import from_bytes
|
||||||
|
>>> results = from_bytes('Bсеки човек има право на образование. Oбразованието!'.encode('utf_8'))
|
||||||
|
>>> best_guess = results.best()
|
||||||
|
>>> str(best_guess)
|
||||||
|
'Bсеки човек има право на образование. Oбразованието!'
|
||||||
|
|
||||||
|
Others methods and usages are available - see the full documentation
|
||||||
|
at <https://github.com/Ousret/charset_normalizer>.
|
||||||
|
:copyright: (c) 2021 by Ahmed TAHRI
|
||||||
|
:license: MIT, see LICENSE for more details.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import logging
|
||||||
|
|
||||||
|
from .api import from_bytes, from_fp, from_path, is_binary
|
||||||
|
from .legacy import detect
|
||||||
|
from .models import CharsetMatch, CharsetMatches
|
||||||
|
from .utils import set_logging_handler
|
||||||
|
from .version import VERSION, __version__
|
||||||
|
|
||||||
|
__all__ = (
|
||||||
|
"from_fp",
|
||||||
|
"from_path",
|
||||||
|
"from_bytes",
|
||||||
|
"is_binary",
|
||||||
|
"detect",
|
||||||
|
"CharsetMatch",
|
||||||
|
"CharsetMatches",
|
||||||
|
"__version__",
|
||||||
|
"VERSION",
|
||||||
|
"set_logging_handler",
|
||||||
|
)
|
||||||
|
|
||||||
|
# Attach a NullHandler to the top level logger by default
|
||||||
|
# https://docs.python.org/3.3/howto/logging.html#configuring-logging-for-a-library
|
||||||
|
|
||||||
|
logging.getLogger("charset_normalizer").addHandler(logging.NullHandler())
|
||||||
@@ -0,0 +1,6 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from .cli import cli_detect
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
cli_detect()
|
||||||
669
venv/lib/python3.12/site-packages/charset_normalizer/api.py
Normal file
669
venv/lib/python3.12/site-packages/charset_normalizer/api.py
Normal file
@@ -0,0 +1,669 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import logging
|
||||||
|
from os import PathLike
|
||||||
|
from typing import BinaryIO
|
||||||
|
|
||||||
|
from .cd import (
|
||||||
|
coherence_ratio,
|
||||||
|
encoding_languages,
|
||||||
|
mb_encoding_languages,
|
||||||
|
merge_coherence_ratios,
|
||||||
|
)
|
||||||
|
from .constant import IANA_SUPPORTED, TOO_BIG_SEQUENCE, TOO_SMALL_SEQUENCE, TRACE
|
||||||
|
from .md import mess_ratio
|
||||||
|
from .models import CharsetMatch, CharsetMatches
|
||||||
|
from .utils import (
|
||||||
|
any_specified_encoding,
|
||||||
|
cut_sequence_chunks,
|
||||||
|
iana_name,
|
||||||
|
identify_sig_or_bom,
|
||||||
|
is_cp_similar,
|
||||||
|
is_multi_byte_encoding,
|
||||||
|
should_strip_sig_or_bom,
|
||||||
|
)
|
||||||
|
|
||||||
|
logger = logging.getLogger("charset_normalizer")
|
||||||
|
explain_handler = logging.StreamHandler()
|
||||||
|
explain_handler.setFormatter(
|
||||||
|
logging.Formatter("%(asctime)s | %(levelname)s | %(message)s")
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def from_bytes(
|
||||||
|
sequences: bytes | bytearray,
|
||||||
|
steps: int = 5,
|
||||||
|
chunk_size: int = 512,
|
||||||
|
threshold: float = 0.2,
|
||||||
|
cp_isolation: list[str] | None = None,
|
||||||
|
cp_exclusion: list[str] | None = None,
|
||||||
|
preemptive_behaviour: bool = True,
|
||||||
|
explain: bool = False,
|
||||||
|
language_threshold: float = 0.1,
|
||||||
|
enable_fallback: bool = True,
|
||||||
|
) -> CharsetMatches:
|
||||||
|
"""
|
||||||
|
Given a raw bytes sequence, return the best possibles charset usable to render str objects.
|
||||||
|
If there is no results, it is a strong indicator that the source is binary/not text.
|
||||||
|
By default, the process will extract 5 blocks of 512o each to assess the mess and coherence of a given sequence.
|
||||||
|
And will give up a particular code page after 20% of measured mess. Those criteria are customizable at will.
|
||||||
|
|
||||||
|
The preemptive behavior DOES NOT replace the traditional detection workflow, it prioritize a particular code page
|
||||||
|
but never take it for granted. Can improve the performance.
|
||||||
|
|
||||||
|
You may want to focus your attention to some code page or/and not others, use cp_isolation and cp_exclusion for that
|
||||||
|
purpose.
|
||||||
|
|
||||||
|
This function will strip the SIG in the payload/sequence every time except on UTF-16, UTF-32.
|
||||||
|
By default the library does not setup any handler other than the NullHandler, if you choose to set the 'explain'
|
||||||
|
toggle to True it will alter the logger configuration to add a StreamHandler that is suitable for debugging.
|
||||||
|
Custom logging format and handler can be set manually.
|
||||||
|
"""
|
||||||
|
|
||||||
|
if not isinstance(sequences, (bytearray, bytes)):
|
||||||
|
raise TypeError(
|
||||||
|
"Expected object of type bytes or bytearray, got: {}".format(
|
||||||
|
type(sequences)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if explain:
|
||||||
|
previous_logger_level: int = logger.level
|
||||||
|
logger.addHandler(explain_handler)
|
||||||
|
logger.setLevel(TRACE)
|
||||||
|
|
||||||
|
length: int = len(sequences)
|
||||||
|
|
||||||
|
if length == 0:
|
||||||
|
logger.debug("Encoding detection on empty bytes, assuming utf_8 intention.")
|
||||||
|
if explain: # Defensive: ensure exit path clean handler
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level or logging.WARNING)
|
||||||
|
return CharsetMatches([CharsetMatch(sequences, "utf_8", 0.0, False, [], "")])
|
||||||
|
|
||||||
|
if cp_isolation is not None:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"cp_isolation is set. use this flag for debugging purpose. "
|
||||||
|
"limited list of encoding allowed : %s.",
|
||||||
|
", ".join(cp_isolation),
|
||||||
|
)
|
||||||
|
cp_isolation = [iana_name(cp, False) for cp in cp_isolation]
|
||||||
|
else:
|
||||||
|
cp_isolation = []
|
||||||
|
|
||||||
|
if cp_exclusion is not None:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"cp_exclusion is set. use this flag for debugging purpose. "
|
||||||
|
"limited list of encoding excluded : %s.",
|
||||||
|
", ".join(cp_exclusion),
|
||||||
|
)
|
||||||
|
cp_exclusion = [iana_name(cp, False) for cp in cp_exclusion]
|
||||||
|
else:
|
||||||
|
cp_exclusion = []
|
||||||
|
|
||||||
|
if length <= (chunk_size * steps):
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"override steps (%i) and chunk_size (%i) as content does not fit (%i byte(s) given) parameters.",
|
||||||
|
steps,
|
||||||
|
chunk_size,
|
||||||
|
length,
|
||||||
|
)
|
||||||
|
steps = 1
|
||||||
|
chunk_size = length
|
||||||
|
|
||||||
|
if steps > 1 and length / steps < chunk_size:
|
||||||
|
chunk_size = int(length / steps)
|
||||||
|
|
||||||
|
is_too_small_sequence: bool = len(sequences) < TOO_SMALL_SEQUENCE
|
||||||
|
is_too_large_sequence: bool = len(sequences) >= TOO_BIG_SEQUENCE
|
||||||
|
|
||||||
|
if is_too_small_sequence:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Trying to detect encoding from a tiny portion of ({}) byte(s).".format(
|
||||||
|
length
|
||||||
|
),
|
||||||
|
)
|
||||||
|
elif is_too_large_sequence:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Using lazy str decoding because the payload is quite large, ({}) byte(s).".format(
|
||||||
|
length
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
prioritized_encodings: list[str] = []
|
||||||
|
|
||||||
|
specified_encoding: str | None = (
|
||||||
|
any_specified_encoding(sequences) if preemptive_behaviour else None
|
||||||
|
)
|
||||||
|
|
||||||
|
if specified_encoding is not None:
|
||||||
|
prioritized_encodings.append(specified_encoding)
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Detected declarative mark in sequence. Priority +1 given for %s.",
|
||||||
|
specified_encoding,
|
||||||
|
)
|
||||||
|
|
||||||
|
tested: set[str] = set()
|
||||||
|
tested_but_hard_failure: list[str] = []
|
||||||
|
tested_but_soft_failure: list[str] = []
|
||||||
|
|
||||||
|
fallback_ascii: CharsetMatch | None = None
|
||||||
|
fallback_u8: CharsetMatch | None = None
|
||||||
|
fallback_specified: CharsetMatch | None = None
|
||||||
|
|
||||||
|
results: CharsetMatches = CharsetMatches()
|
||||||
|
|
||||||
|
early_stop_results: CharsetMatches = CharsetMatches()
|
||||||
|
|
||||||
|
sig_encoding, sig_payload = identify_sig_or_bom(sequences)
|
||||||
|
|
||||||
|
if sig_encoding is not None:
|
||||||
|
prioritized_encodings.append(sig_encoding)
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Detected a SIG or BOM mark on first %i byte(s). Priority +1 given for %s.",
|
||||||
|
len(sig_payload),
|
||||||
|
sig_encoding,
|
||||||
|
)
|
||||||
|
|
||||||
|
prioritized_encodings.append("ascii")
|
||||||
|
|
||||||
|
if "utf_8" not in prioritized_encodings:
|
||||||
|
prioritized_encodings.append("utf_8")
|
||||||
|
|
||||||
|
for encoding_iana in prioritized_encodings + IANA_SUPPORTED:
|
||||||
|
if cp_isolation and encoding_iana not in cp_isolation:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if cp_exclusion and encoding_iana in cp_exclusion:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if encoding_iana in tested:
|
||||||
|
continue
|
||||||
|
|
||||||
|
tested.add(encoding_iana)
|
||||||
|
|
||||||
|
decoded_payload: str | None = None
|
||||||
|
bom_or_sig_available: bool = sig_encoding == encoding_iana
|
||||||
|
strip_sig_or_bom: bool = bom_or_sig_available and should_strip_sig_or_bom(
|
||||||
|
encoding_iana
|
||||||
|
)
|
||||||
|
|
||||||
|
if encoding_iana in {"utf_16", "utf_32"} and not bom_or_sig_available:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Encoding %s won't be tested as-is because it require a BOM. Will try some sub-encoder LE/BE.",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
if encoding_iana in {"utf_7"} and not bom_or_sig_available:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Encoding %s won't be tested as-is because detection is unreliable without BOM/SIG.",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
is_multi_byte_decoder: bool = is_multi_byte_encoding(encoding_iana)
|
||||||
|
except (ModuleNotFoundError, ImportError):
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Encoding %s does not provide an IncrementalDecoder",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
if is_too_large_sequence and is_multi_byte_decoder is False:
|
||||||
|
str(
|
||||||
|
(
|
||||||
|
sequences[: int(50e4)]
|
||||||
|
if strip_sig_or_bom is False
|
||||||
|
else sequences[len(sig_payload) : int(50e4)]
|
||||||
|
),
|
||||||
|
encoding=encoding_iana,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
decoded_payload = str(
|
||||||
|
(
|
||||||
|
sequences
|
||||||
|
if strip_sig_or_bom is False
|
||||||
|
else sequences[len(sig_payload) :]
|
||||||
|
),
|
||||||
|
encoding=encoding_iana,
|
||||||
|
)
|
||||||
|
except (UnicodeDecodeError, LookupError) as e:
|
||||||
|
if not isinstance(e, LookupError):
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Code page %s does not fit given bytes sequence at ALL. %s",
|
||||||
|
encoding_iana,
|
||||||
|
str(e),
|
||||||
|
)
|
||||||
|
tested_but_hard_failure.append(encoding_iana)
|
||||||
|
continue
|
||||||
|
|
||||||
|
similar_soft_failure_test: bool = False
|
||||||
|
|
||||||
|
for encoding_soft_failed in tested_but_soft_failure:
|
||||||
|
if is_cp_similar(encoding_iana, encoding_soft_failed):
|
||||||
|
similar_soft_failure_test = True
|
||||||
|
break
|
||||||
|
|
||||||
|
if similar_soft_failure_test:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"%s is deemed too similar to code page %s and was consider unsuited already. Continuing!",
|
||||||
|
encoding_iana,
|
||||||
|
encoding_soft_failed,
|
||||||
|
)
|
||||||
|
continue
|
||||||
|
|
||||||
|
r_ = range(
|
||||||
|
0 if not bom_or_sig_available else len(sig_payload),
|
||||||
|
length,
|
||||||
|
int(length / steps),
|
||||||
|
)
|
||||||
|
|
||||||
|
multi_byte_bonus: bool = (
|
||||||
|
is_multi_byte_decoder
|
||||||
|
and decoded_payload is not None
|
||||||
|
and len(decoded_payload) < length
|
||||||
|
)
|
||||||
|
|
||||||
|
if multi_byte_bonus:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Code page %s is a multi byte encoding table and it appear that at least one character "
|
||||||
|
"was encoded using n-bytes.",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
|
||||||
|
max_chunk_gave_up: int = int(len(r_) / 4)
|
||||||
|
|
||||||
|
max_chunk_gave_up = max(max_chunk_gave_up, 2)
|
||||||
|
early_stop_count: int = 0
|
||||||
|
lazy_str_hard_failure = False
|
||||||
|
|
||||||
|
md_chunks: list[str] = []
|
||||||
|
md_ratios = []
|
||||||
|
|
||||||
|
try:
|
||||||
|
for chunk in cut_sequence_chunks(
|
||||||
|
sequences,
|
||||||
|
encoding_iana,
|
||||||
|
r_,
|
||||||
|
chunk_size,
|
||||||
|
bom_or_sig_available,
|
||||||
|
strip_sig_or_bom,
|
||||||
|
sig_payload,
|
||||||
|
is_multi_byte_decoder,
|
||||||
|
decoded_payload,
|
||||||
|
):
|
||||||
|
md_chunks.append(chunk)
|
||||||
|
|
||||||
|
md_ratios.append(
|
||||||
|
mess_ratio(
|
||||||
|
chunk,
|
||||||
|
threshold,
|
||||||
|
explain is True and 1 <= len(cp_isolation) <= 2,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if md_ratios[-1] >= threshold:
|
||||||
|
early_stop_count += 1
|
||||||
|
|
||||||
|
if (early_stop_count >= max_chunk_gave_up) or (
|
||||||
|
bom_or_sig_available and strip_sig_or_bom is False
|
||||||
|
):
|
||||||
|
break
|
||||||
|
except (
|
||||||
|
UnicodeDecodeError
|
||||||
|
) as e: # Lazy str loading may have missed something there
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"LazyStr Loading: After MD chunk decode, code page %s does not fit given bytes sequence at ALL. %s",
|
||||||
|
encoding_iana,
|
||||||
|
str(e),
|
||||||
|
)
|
||||||
|
early_stop_count = max_chunk_gave_up
|
||||||
|
lazy_str_hard_failure = True
|
||||||
|
|
||||||
|
# We might want to check the sequence again with the whole content
|
||||||
|
# Only if initial MD tests passes
|
||||||
|
if (
|
||||||
|
not lazy_str_hard_failure
|
||||||
|
and is_too_large_sequence
|
||||||
|
and not is_multi_byte_decoder
|
||||||
|
):
|
||||||
|
try:
|
||||||
|
sequences[int(50e3) :].decode(encoding_iana, errors="strict")
|
||||||
|
except UnicodeDecodeError as e:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"LazyStr Loading: After final lookup, code page %s does not fit given bytes sequence at ALL. %s",
|
||||||
|
encoding_iana,
|
||||||
|
str(e),
|
||||||
|
)
|
||||||
|
tested_but_hard_failure.append(encoding_iana)
|
||||||
|
continue
|
||||||
|
|
||||||
|
mean_mess_ratio: float = sum(md_ratios) / len(md_ratios) if md_ratios else 0.0
|
||||||
|
if mean_mess_ratio >= threshold or early_stop_count >= max_chunk_gave_up:
|
||||||
|
tested_but_soft_failure.append(encoding_iana)
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"%s was excluded because of initial chaos probing. Gave up %i time(s). "
|
||||||
|
"Computed mean chaos is %f %%.",
|
||||||
|
encoding_iana,
|
||||||
|
early_stop_count,
|
||||||
|
round(mean_mess_ratio * 100, ndigits=3),
|
||||||
|
)
|
||||||
|
# Preparing those fallbacks in case we got nothing.
|
||||||
|
if (
|
||||||
|
enable_fallback
|
||||||
|
and encoding_iana
|
||||||
|
in ["ascii", "utf_8", specified_encoding, "utf_16", "utf_32"]
|
||||||
|
and not lazy_str_hard_failure
|
||||||
|
):
|
||||||
|
fallback_entry = CharsetMatch(
|
||||||
|
sequences,
|
||||||
|
encoding_iana,
|
||||||
|
threshold,
|
||||||
|
bom_or_sig_available,
|
||||||
|
[],
|
||||||
|
decoded_payload,
|
||||||
|
preemptive_declaration=specified_encoding,
|
||||||
|
)
|
||||||
|
if encoding_iana == specified_encoding:
|
||||||
|
fallback_specified = fallback_entry
|
||||||
|
elif encoding_iana == "ascii":
|
||||||
|
fallback_ascii = fallback_entry
|
||||||
|
else:
|
||||||
|
fallback_u8 = fallback_entry
|
||||||
|
continue
|
||||||
|
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"%s passed initial chaos probing. Mean measured chaos is %f %%",
|
||||||
|
encoding_iana,
|
||||||
|
round(mean_mess_ratio * 100, ndigits=3),
|
||||||
|
)
|
||||||
|
|
||||||
|
if not is_multi_byte_decoder:
|
||||||
|
target_languages: list[str] = encoding_languages(encoding_iana)
|
||||||
|
else:
|
||||||
|
target_languages = mb_encoding_languages(encoding_iana)
|
||||||
|
|
||||||
|
if target_languages:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"{} should target any language(s) of {}".format(
|
||||||
|
encoding_iana, str(target_languages)
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
cd_ratios = []
|
||||||
|
|
||||||
|
# We shall skip the CD when its about ASCII
|
||||||
|
# Most of the time its not relevant to run "language-detection" on it.
|
||||||
|
if encoding_iana != "ascii":
|
||||||
|
for chunk in md_chunks:
|
||||||
|
chunk_languages = coherence_ratio(
|
||||||
|
chunk,
|
||||||
|
language_threshold,
|
||||||
|
",".join(target_languages) if target_languages else None,
|
||||||
|
)
|
||||||
|
|
||||||
|
cd_ratios.append(chunk_languages)
|
||||||
|
|
||||||
|
cd_ratios_merged = merge_coherence_ratios(cd_ratios)
|
||||||
|
|
||||||
|
if cd_ratios_merged:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"We detected language {} using {}".format(
|
||||||
|
cd_ratios_merged, encoding_iana
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
current_match = CharsetMatch(
|
||||||
|
sequences,
|
||||||
|
encoding_iana,
|
||||||
|
mean_mess_ratio,
|
||||||
|
bom_or_sig_available,
|
||||||
|
cd_ratios_merged,
|
||||||
|
(
|
||||||
|
decoded_payload
|
||||||
|
if (
|
||||||
|
is_too_large_sequence is False
|
||||||
|
or encoding_iana in [specified_encoding, "ascii", "utf_8"]
|
||||||
|
)
|
||||||
|
else None
|
||||||
|
),
|
||||||
|
preemptive_declaration=specified_encoding,
|
||||||
|
)
|
||||||
|
|
||||||
|
results.append(current_match)
|
||||||
|
|
||||||
|
if (
|
||||||
|
encoding_iana in [specified_encoding, "ascii", "utf_8"]
|
||||||
|
and mean_mess_ratio < 0.1
|
||||||
|
):
|
||||||
|
# If md says nothing to worry about, then... stop immediately!
|
||||||
|
if mean_mess_ratio == 0.0:
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: %s is most likely the one.",
|
||||||
|
current_match.encoding,
|
||||||
|
)
|
||||||
|
if explain: # Defensive: ensure exit path clean handler
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level)
|
||||||
|
return CharsetMatches([current_match])
|
||||||
|
|
||||||
|
early_stop_results.append(current_match)
|
||||||
|
|
||||||
|
if (
|
||||||
|
len(early_stop_results)
|
||||||
|
and (specified_encoding is None or specified_encoding in tested)
|
||||||
|
and "ascii" in tested
|
||||||
|
and "utf_8" in tested
|
||||||
|
):
|
||||||
|
probable_result: CharsetMatch = early_stop_results.best() # type: ignore[assignment]
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: %s is most likely the one.",
|
||||||
|
probable_result.encoding,
|
||||||
|
)
|
||||||
|
if explain: # Defensive: ensure exit path clean handler
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level)
|
||||||
|
|
||||||
|
return CharsetMatches([probable_result])
|
||||||
|
|
||||||
|
if encoding_iana == sig_encoding:
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: %s is most likely the one as we detected a BOM or SIG within "
|
||||||
|
"the beginning of the sequence.",
|
||||||
|
encoding_iana,
|
||||||
|
)
|
||||||
|
if explain: # Defensive: ensure exit path clean handler
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level)
|
||||||
|
return CharsetMatches([results[encoding_iana]])
|
||||||
|
|
||||||
|
if len(results) == 0:
|
||||||
|
if fallback_u8 or fallback_ascii or fallback_specified:
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Nothing got out of the detection process. Using ASCII/UTF-8/Specified fallback.",
|
||||||
|
)
|
||||||
|
|
||||||
|
if fallback_specified:
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: %s will be used as a fallback match",
|
||||||
|
fallback_specified.encoding,
|
||||||
|
)
|
||||||
|
results.append(fallback_specified)
|
||||||
|
elif (
|
||||||
|
(fallback_u8 and fallback_ascii is None)
|
||||||
|
or (
|
||||||
|
fallback_u8
|
||||||
|
and fallback_ascii
|
||||||
|
and fallback_u8.fingerprint != fallback_ascii.fingerprint
|
||||||
|
)
|
||||||
|
or (fallback_u8 is not None)
|
||||||
|
):
|
||||||
|
logger.debug("Encoding detection: utf_8 will be used as a fallback match")
|
||||||
|
results.append(fallback_u8)
|
||||||
|
elif fallback_ascii:
|
||||||
|
logger.debug("Encoding detection: ascii will be used as a fallback match")
|
||||||
|
results.append(fallback_ascii)
|
||||||
|
|
||||||
|
if results:
|
||||||
|
logger.debug(
|
||||||
|
"Encoding detection: Found %s as plausible (best-candidate) for content. With %i alternatives.",
|
||||||
|
results.best().encoding, # type: ignore
|
||||||
|
len(results) - 1,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
logger.debug("Encoding detection: Unable to determine any suitable charset.")
|
||||||
|
|
||||||
|
if explain:
|
||||||
|
logger.removeHandler(explain_handler)
|
||||||
|
logger.setLevel(previous_logger_level)
|
||||||
|
|
||||||
|
return results
|
||||||
|
|
||||||
|
|
||||||
|
def from_fp(
|
||||||
|
fp: BinaryIO,
|
||||||
|
steps: int = 5,
|
||||||
|
chunk_size: int = 512,
|
||||||
|
threshold: float = 0.20,
|
||||||
|
cp_isolation: list[str] | None = None,
|
||||||
|
cp_exclusion: list[str] | None = None,
|
||||||
|
preemptive_behaviour: bool = True,
|
||||||
|
explain: bool = False,
|
||||||
|
language_threshold: float = 0.1,
|
||||||
|
enable_fallback: bool = True,
|
||||||
|
) -> CharsetMatches:
|
||||||
|
"""
|
||||||
|
Same thing than the function from_bytes but using a file pointer that is already ready.
|
||||||
|
Will not close the file pointer.
|
||||||
|
"""
|
||||||
|
return from_bytes(
|
||||||
|
fp.read(),
|
||||||
|
steps,
|
||||||
|
chunk_size,
|
||||||
|
threshold,
|
||||||
|
cp_isolation,
|
||||||
|
cp_exclusion,
|
||||||
|
preemptive_behaviour,
|
||||||
|
explain,
|
||||||
|
language_threshold,
|
||||||
|
enable_fallback,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def from_path(
|
||||||
|
path: str | bytes | PathLike, # type: ignore[type-arg]
|
||||||
|
steps: int = 5,
|
||||||
|
chunk_size: int = 512,
|
||||||
|
threshold: float = 0.20,
|
||||||
|
cp_isolation: list[str] | None = None,
|
||||||
|
cp_exclusion: list[str] | None = None,
|
||||||
|
preemptive_behaviour: bool = True,
|
||||||
|
explain: bool = False,
|
||||||
|
language_threshold: float = 0.1,
|
||||||
|
enable_fallback: bool = True,
|
||||||
|
) -> CharsetMatches:
|
||||||
|
"""
|
||||||
|
Same thing than the function from_bytes but with one extra step. Opening and reading given file path in binary mode.
|
||||||
|
Can raise IOError.
|
||||||
|
"""
|
||||||
|
with open(path, "rb") as fp:
|
||||||
|
return from_fp(
|
||||||
|
fp,
|
||||||
|
steps,
|
||||||
|
chunk_size,
|
||||||
|
threshold,
|
||||||
|
cp_isolation,
|
||||||
|
cp_exclusion,
|
||||||
|
preemptive_behaviour,
|
||||||
|
explain,
|
||||||
|
language_threshold,
|
||||||
|
enable_fallback,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def is_binary(
|
||||||
|
fp_or_path_or_payload: PathLike | str | BinaryIO | bytes, # type: ignore[type-arg]
|
||||||
|
steps: int = 5,
|
||||||
|
chunk_size: int = 512,
|
||||||
|
threshold: float = 0.20,
|
||||||
|
cp_isolation: list[str] | None = None,
|
||||||
|
cp_exclusion: list[str] | None = None,
|
||||||
|
preemptive_behaviour: bool = True,
|
||||||
|
explain: bool = False,
|
||||||
|
language_threshold: float = 0.1,
|
||||||
|
enable_fallback: bool = False,
|
||||||
|
) -> bool:
|
||||||
|
"""
|
||||||
|
Detect if the given input (file, bytes, or path) points to a binary file. aka. not a string.
|
||||||
|
Based on the same main heuristic algorithms and default kwargs at the sole exception that fallbacks match
|
||||||
|
are disabled to be stricter around ASCII-compatible but unlikely to be a string.
|
||||||
|
"""
|
||||||
|
if isinstance(fp_or_path_or_payload, (str, PathLike)):
|
||||||
|
guesses = from_path(
|
||||||
|
fp_or_path_or_payload,
|
||||||
|
steps=steps,
|
||||||
|
chunk_size=chunk_size,
|
||||||
|
threshold=threshold,
|
||||||
|
cp_isolation=cp_isolation,
|
||||||
|
cp_exclusion=cp_exclusion,
|
||||||
|
preemptive_behaviour=preemptive_behaviour,
|
||||||
|
explain=explain,
|
||||||
|
language_threshold=language_threshold,
|
||||||
|
enable_fallback=enable_fallback,
|
||||||
|
)
|
||||||
|
elif isinstance(
|
||||||
|
fp_or_path_or_payload,
|
||||||
|
(
|
||||||
|
bytes,
|
||||||
|
bytearray,
|
||||||
|
),
|
||||||
|
):
|
||||||
|
guesses = from_bytes(
|
||||||
|
fp_or_path_or_payload,
|
||||||
|
steps=steps,
|
||||||
|
chunk_size=chunk_size,
|
||||||
|
threshold=threshold,
|
||||||
|
cp_isolation=cp_isolation,
|
||||||
|
cp_exclusion=cp_exclusion,
|
||||||
|
preemptive_behaviour=preemptive_behaviour,
|
||||||
|
explain=explain,
|
||||||
|
language_threshold=language_threshold,
|
||||||
|
enable_fallback=enable_fallback,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
guesses = from_fp(
|
||||||
|
fp_or_path_or_payload,
|
||||||
|
steps=steps,
|
||||||
|
chunk_size=chunk_size,
|
||||||
|
threshold=threshold,
|
||||||
|
cp_isolation=cp_isolation,
|
||||||
|
cp_exclusion=cp_exclusion,
|
||||||
|
preemptive_behaviour=preemptive_behaviour,
|
||||||
|
explain=explain,
|
||||||
|
language_threshold=language_threshold,
|
||||||
|
enable_fallback=enable_fallback,
|
||||||
|
)
|
||||||
|
|
||||||
|
return not guesses
|
||||||
395
venv/lib/python3.12/site-packages/charset_normalizer/cd.py
Normal file
395
venv/lib/python3.12/site-packages/charset_normalizer/cd.py
Normal file
@@ -0,0 +1,395 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import importlib
|
||||||
|
from codecs import IncrementalDecoder
|
||||||
|
from collections import Counter
|
||||||
|
from functools import lru_cache
|
||||||
|
from typing import Counter as TypeCounter
|
||||||
|
|
||||||
|
from .constant import (
|
||||||
|
FREQUENCIES,
|
||||||
|
KO_NAMES,
|
||||||
|
LANGUAGE_SUPPORTED_COUNT,
|
||||||
|
TOO_SMALL_SEQUENCE,
|
||||||
|
ZH_NAMES,
|
||||||
|
)
|
||||||
|
from .md import is_suspiciously_successive_range
|
||||||
|
from .models import CoherenceMatches
|
||||||
|
from .utils import (
|
||||||
|
is_accentuated,
|
||||||
|
is_latin,
|
||||||
|
is_multi_byte_encoding,
|
||||||
|
is_unicode_range_secondary,
|
||||||
|
unicode_range,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def encoding_unicode_range(iana_name: str) -> list[str]:
|
||||||
|
"""
|
||||||
|
Return associated unicode ranges in a single byte code page.
|
||||||
|
"""
|
||||||
|
if is_multi_byte_encoding(iana_name):
|
||||||
|
raise OSError("Function not supported on multi-byte code page")
|
||||||
|
|
||||||
|
decoder = importlib.import_module(f"encodings.{iana_name}").IncrementalDecoder
|
||||||
|
|
||||||
|
p: IncrementalDecoder = decoder(errors="ignore")
|
||||||
|
seen_ranges: dict[str, int] = {}
|
||||||
|
character_count: int = 0
|
||||||
|
|
||||||
|
for i in range(0x40, 0xFF):
|
||||||
|
chunk: str = p.decode(bytes([i]))
|
||||||
|
|
||||||
|
if chunk:
|
||||||
|
character_range: str | None = unicode_range(chunk)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if is_unicode_range_secondary(character_range) is False:
|
||||||
|
if character_range not in seen_ranges:
|
||||||
|
seen_ranges[character_range] = 0
|
||||||
|
seen_ranges[character_range] += 1
|
||||||
|
character_count += 1
|
||||||
|
|
||||||
|
return sorted(
|
||||||
|
[
|
||||||
|
character_range
|
||||||
|
for character_range in seen_ranges
|
||||||
|
if seen_ranges[character_range] / character_count >= 0.15
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def unicode_range_languages(primary_range: str) -> list[str]:
|
||||||
|
"""
|
||||||
|
Return inferred languages used with a unicode range.
|
||||||
|
"""
|
||||||
|
languages: list[str] = []
|
||||||
|
|
||||||
|
for language, characters in FREQUENCIES.items():
|
||||||
|
for character in characters:
|
||||||
|
if unicode_range(character) == primary_range:
|
||||||
|
languages.append(language)
|
||||||
|
break
|
||||||
|
|
||||||
|
return languages
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache()
|
||||||
|
def encoding_languages(iana_name: str) -> list[str]:
|
||||||
|
"""
|
||||||
|
Single-byte encoding language association. Some code page are heavily linked to particular language(s).
|
||||||
|
This function does the correspondence.
|
||||||
|
"""
|
||||||
|
unicode_ranges: list[str] = encoding_unicode_range(iana_name)
|
||||||
|
primary_range: str | None = None
|
||||||
|
|
||||||
|
for specified_range in unicode_ranges:
|
||||||
|
if "Latin" not in specified_range:
|
||||||
|
primary_range = specified_range
|
||||||
|
break
|
||||||
|
|
||||||
|
if primary_range is None:
|
||||||
|
return ["Latin Based"]
|
||||||
|
|
||||||
|
return unicode_range_languages(primary_range)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache()
|
||||||
|
def mb_encoding_languages(iana_name: str) -> list[str]:
|
||||||
|
"""
|
||||||
|
Multi-byte encoding language association. Some code page are heavily linked to particular language(s).
|
||||||
|
This function does the correspondence.
|
||||||
|
"""
|
||||||
|
if (
|
||||||
|
iana_name.startswith("shift_")
|
||||||
|
or iana_name.startswith("iso2022_jp")
|
||||||
|
or iana_name.startswith("euc_j")
|
||||||
|
or iana_name == "cp932"
|
||||||
|
):
|
||||||
|
return ["Japanese"]
|
||||||
|
if iana_name.startswith("gb") or iana_name in ZH_NAMES:
|
||||||
|
return ["Chinese"]
|
||||||
|
if iana_name.startswith("iso2022_kr") or iana_name in KO_NAMES:
|
||||||
|
return ["Korean"]
|
||||||
|
|
||||||
|
return []
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=LANGUAGE_SUPPORTED_COUNT)
|
||||||
|
def get_target_features(language: str) -> tuple[bool, bool]:
|
||||||
|
"""
|
||||||
|
Determine main aspects from a supported language if it contains accents and if is pure Latin.
|
||||||
|
"""
|
||||||
|
target_have_accents: bool = False
|
||||||
|
target_pure_latin: bool = True
|
||||||
|
|
||||||
|
for character in FREQUENCIES[language]:
|
||||||
|
if not target_have_accents and is_accentuated(character):
|
||||||
|
target_have_accents = True
|
||||||
|
if target_pure_latin and is_latin(character) is False:
|
||||||
|
target_pure_latin = False
|
||||||
|
|
||||||
|
return target_have_accents, target_pure_latin
|
||||||
|
|
||||||
|
|
||||||
|
def alphabet_languages(
|
||||||
|
characters: list[str], ignore_non_latin: bool = False
|
||||||
|
) -> list[str]:
|
||||||
|
"""
|
||||||
|
Return associated languages associated to given characters.
|
||||||
|
"""
|
||||||
|
languages: list[tuple[str, float]] = []
|
||||||
|
|
||||||
|
source_have_accents = any(is_accentuated(character) for character in characters)
|
||||||
|
|
||||||
|
for language, language_characters in FREQUENCIES.items():
|
||||||
|
target_have_accents, target_pure_latin = get_target_features(language)
|
||||||
|
|
||||||
|
if ignore_non_latin and target_pure_latin is False:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if target_have_accents is False and source_have_accents:
|
||||||
|
continue
|
||||||
|
|
||||||
|
character_count: int = len(language_characters)
|
||||||
|
|
||||||
|
character_match_count: int = len(
|
||||||
|
[c for c in language_characters if c in characters]
|
||||||
|
)
|
||||||
|
|
||||||
|
ratio: float = character_match_count / character_count
|
||||||
|
|
||||||
|
if ratio >= 0.2:
|
||||||
|
languages.append((language, ratio))
|
||||||
|
|
||||||
|
languages = sorted(languages, key=lambda x: x[1], reverse=True)
|
||||||
|
|
||||||
|
return [compatible_language[0] for compatible_language in languages]
|
||||||
|
|
||||||
|
|
||||||
|
def characters_popularity_compare(
|
||||||
|
language: str, ordered_characters: list[str]
|
||||||
|
) -> float:
|
||||||
|
"""
|
||||||
|
Determine if a ordered characters list (by occurrence from most appearance to rarest) match a particular language.
|
||||||
|
The result is a ratio between 0. (absolutely no correspondence) and 1. (near perfect fit).
|
||||||
|
Beware that is function is not strict on the match in order to ease the detection. (Meaning close match is 1.)
|
||||||
|
"""
|
||||||
|
if language not in FREQUENCIES:
|
||||||
|
raise ValueError(f"{language} not available")
|
||||||
|
|
||||||
|
character_approved_count: int = 0
|
||||||
|
FREQUENCIES_language_set = set(FREQUENCIES[language])
|
||||||
|
|
||||||
|
ordered_characters_count: int = len(ordered_characters)
|
||||||
|
target_language_characters_count: int = len(FREQUENCIES[language])
|
||||||
|
|
||||||
|
large_alphabet: bool = target_language_characters_count > 26
|
||||||
|
|
||||||
|
for character, character_rank in zip(
|
||||||
|
ordered_characters, range(0, ordered_characters_count)
|
||||||
|
):
|
||||||
|
if character not in FREQUENCIES_language_set:
|
||||||
|
continue
|
||||||
|
|
||||||
|
character_rank_in_language: int = FREQUENCIES[language].index(character)
|
||||||
|
expected_projection_ratio: float = (
|
||||||
|
target_language_characters_count / ordered_characters_count
|
||||||
|
)
|
||||||
|
character_rank_projection: int = int(character_rank * expected_projection_ratio)
|
||||||
|
|
||||||
|
if (
|
||||||
|
large_alphabet is False
|
||||||
|
and abs(character_rank_projection - character_rank_in_language) > 4
|
||||||
|
):
|
||||||
|
continue
|
||||||
|
|
||||||
|
if (
|
||||||
|
large_alphabet is True
|
||||||
|
and abs(character_rank_projection - character_rank_in_language)
|
||||||
|
< target_language_characters_count / 3
|
||||||
|
):
|
||||||
|
character_approved_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
characters_before_source: list[str] = FREQUENCIES[language][
|
||||||
|
0:character_rank_in_language
|
||||||
|
]
|
||||||
|
characters_after_source: list[str] = FREQUENCIES[language][
|
||||||
|
character_rank_in_language:
|
||||||
|
]
|
||||||
|
characters_before: list[str] = ordered_characters[0:character_rank]
|
||||||
|
characters_after: list[str] = ordered_characters[character_rank:]
|
||||||
|
|
||||||
|
before_match_count: int = len(
|
||||||
|
set(characters_before) & set(characters_before_source)
|
||||||
|
)
|
||||||
|
|
||||||
|
after_match_count: int = len(
|
||||||
|
set(characters_after) & set(characters_after_source)
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(characters_before_source) == 0 and before_match_count <= 4:
|
||||||
|
character_approved_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
if len(characters_after_source) == 0 and after_match_count <= 4:
|
||||||
|
character_approved_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
if (
|
||||||
|
before_match_count / len(characters_before_source) >= 0.4
|
||||||
|
or after_match_count / len(characters_after_source) >= 0.4
|
||||||
|
):
|
||||||
|
character_approved_count += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
return character_approved_count / len(ordered_characters)
|
||||||
|
|
||||||
|
|
||||||
|
def alpha_unicode_split(decoded_sequence: str) -> list[str]:
|
||||||
|
"""
|
||||||
|
Given a decoded text sequence, return a list of str. Unicode range / alphabet separation.
|
||||||
|
Ex. a text containing English/Latin with a bit a Hebrew will return two items in the resulting list;
|
||||||
|
One containing the latin letters and the other hebrew.
|
||||||
|
"""
|
||||||
|
layers: dict[str, str] = {}
|
||||||
|
|
||||||
|
for character in decoded_sequence:
|
||||||
|
if character.isalpha() is False:
|
||||||
|
continue
|
||||||
|
|
||||||
|
character_range: str | None = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
continue
|
||||||
|
|
||||||
|
layer_target_range: str | None = None
|
||||||
|
|
||||||
|
for discovered_range in layers:
|
||||||
|
if (
|
||||||
|
is_suspiciously_successive_range(discovered_range, character_range)
|
||||||
|
is False
|
||||||
|
):
|
||||||
|
layer_target_range = discovered_range
|
||||||
|
break
|
||||||
|
|
||||||
|
if layer_target_range is None:
|
||||||
|
layer_target_range = character_range
|
||||||
|
|
||||||
|
if layer_target_range not in layers:
|
||||||
|
layers[layer_target_range] = character.lower()
|
||||||
|
continue
|
||||||
|
|
||||||
|
layers[layer_target_range] += character.lower()
|
||||||
|
|
||||||
|
return list(layers.values())
|
||||||
|
|
||||||
|
|
||||||
|
def merge_coherence_ratios(results: list[CoherenceMatches]) -> CoherenceMatches:
|
||||||
|
"""
|
||||||
|
This function merge results previously given by the function coherence_ratio.
|
||||||
|
The return type is the same as coherence_ratio.
|
||||||
|
"""
|
||||||
|
per_language_ratios: dict[str, list[float]] = {}
|
||||||
|
for result in results:
|
||||||
|
for sub_result in result:
|
||||||
|
language, ratio = sub_result
|
||||||
|
if language not in per_language_ratios:
|
||||||
|
per_language_ratios[language] = [ratio]
|
||||||
|
continue
|
||||||
|
per_language_ratios[language].append(ratio)
|
||||||
|
|
||||||
|
merge = [
|
||||||
|
(
|
||||||
|
language,
|
||||||
|
round(
|
||||||
|
sum(per_language_ratios[language]) / len(per_language_ratios[language]),
|
||||||
|
4,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
for language in per_language_ratios
|
||||||
|
]
|
||||||
|
|
||||||
|
return sorted(merge, key=lambda x: x[1], reverse=True)
|
||||||
|
|
||||||
|
|
||||||
|
def filter_alt_coherence_matches(results: CoherenceMatches) -> CoherenceMatches:
|
||||||
|
"""
|
||||||
|
We shall NOT return "English—" in CoherenceMatches because it is an alternative
|
||||||
|
of "English". This function only keeps the best match and remove the em-dash in it.
|
||||||
|
"""
|
||||||
|
index_results: dict[str, list[float]] = dict()
|
||||||
|
|
||||||
|
for result in results:
|
||||||
|
language, ratio = result
|
||||||
|
no_em_name: str = language.replace("—", "")
|
||||||
|
|
||||||
|
if no_em_name not in index_results:
|
||||||
|
index_results[no_em_name] = []
|
||||||
|
|
||||||
|
index_results[no_em_name].append(ratio)
|
||||||
|
|
||||||
|
if any(len(index_results[e]) > 1 for e in index_results):
|
||||||
|
filtered_results: CoherenceMatches = []
|
||||||
|
|
||||||
|
for language in index_results:
|
||||||
|
filtered_results.append((language, max(index_results[language])))
|
||||||
|
|
||||||
|
return filtered_results
|
||||||
|
|
||||||
|
return results
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=2048)
|
||||||
|
def coherence_ratio(
|
||||||
|
decoded_sequence: str, threshold: float = 0.1, lg_inclusion: str | None = None
|
||||||
|
) -> CoherenceMatches:
|
||||||
|
"""
|
||||||
|
Detect ANY language that can be identified in given sequence. The sequence will be analysed by layers.
|
||||||
|
A layer = Character extraction by alphabets/ranges.
|
||||||
|
"""
|
||||||
|
|
||||||
|
results: list[tuple[str, float]] = []
|
||||||
|
ignore_non_latin: bool = False
|
||||||
|
|
||||||
|
sufficient_match_count: int = 0
|
||||||
|
|
||||||
|
lg_inclusion_list = lg_inclusion.split(",") if lg_inclusion is not None else []
|
||||||
|
if "Latin Based" in lg_inclusion_list:
|
||||||
|
ignore_non_latin = True
|
||||||
|
lg_inclusion_list.remove("Latin Based")
|
||||||
|
|
||||||
|
for layer in alpha_unicode_split(decoded_sequence):
|
||||||
|
sequence_frequencies: TypeCounter[str] = Counter(layer)
|
||||||
|
most_common = sequence_frequencies.most_common()
|
||||||
|
|
||||||
|
character_count: int = sum(o for c, o in most_common)
|
||||||
|
|
||||||
|
if character_count <= TOO_SMALL_SEQUENCE:
|
||||||
|
continue
|
||||||
|
|
||||||
|
popular_character_ordered: list[str] = [c for c, o in most_common]
|
||||||
|
|
||||||
|
for language in lg_inclusion_list or alphabet_languages(
|
||||||
|
popular_character_ordered, ignore_non_latin
|
||||||
|
):
|
||||||
|
ratio: float = characters_popularity_compare(
|
||||||
|
language, popular_character_ordered
|
||||||
|
)
|
||||||
|
|
||||||
|
if ratio < threshold:
|
||||||
|
continue
|
||||||
|
elif ratio >= 0.8:
|
||||||
|
sufficient_match_count += 1
|
||||||
|
|
||||||
|
results.append((language, round(ratio, 4)))
|
||||||
|
|
||||||
|
if sufficient_match_count >= 3:
|
||||||
|
break
|
||||||
|
|
||||||
|
return sorted(
|
||||||
|
filter_alt_coherence_matches(results), key=lambda x: x[1], reverse=True
|
||||||
|
)
|
||||||
@@ -0,0 +1,8 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from .__main__ import cli_detect, query_yes_no
|
||||||
|
|
||||||
|
__all__ = (
|
||||||
|
"cli_detect",
|
||||||
|
"query_yes_no",
|
||||||
|
)
|
||||||
@@ -0,0 +1,381 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import sys
|
||||||
|
import typing
|
||||||
|
from json import dumps
|
||||||
|
from os.path import abspath, basename, dirname, join, realpath
|
||||||
|
from platform import python_version
|
||||||
|
from unicodedata import unidata_version
|
||||||
|
|
||||||
|
import charset_normalizer.md as md_module
|
||||||
|
from charset_normalizer import from_fp
|
||||||
|
from charset_normalizer.models import CliDetectionResult
|
||||||
|
from charset_normalizer.version import __version__
|
||||||
|
|
||||||
|
|
||||||
|
def query_yes_no(question: str, default: str = "yes") -> bool:
|
||||||
|
"""Ask a yes/no question via input() and return their answer.
|
||||||
|
|
||||||
|
"question" is a string that is presented to the user.
|
||||||
|
"default" is the presumed answer if the user just hits <Enter>.
|
||||||
|
It must be "yes" (the default), "no" or None (meaning
|
||||||
|
an answer is required of the user).
|
||||||
|
|
||||||
|
The "answer" return value is True for "yes" or False for "no".
|
||||||
|
|
||||||
|
Credit goes to (c) https://stackoverflow.com/questions/3041986/apt-command-line-interface-like-yes-no-input
|
||||||
|
"""
|
||||||
|
valid = {"yes": True, "y": True, "ye": True, "no": False, "n": False}
|
||||||
|
if default is None:
|
||||||
|
prompt = " [y/n] "
|
||||||
|
elif default == "yes":
|
||||||
|
prompt = " [Y/n] "
|
||||||
|
elif default == "no":
|
||||||
|
prompt = " [y/N] "
|
||||||
|
else:
|
||||||
|
raise ValueError("invalid default answer: '%s'" % default)
|
||||||
|
|
||||||
|
while True:
|
||||||
|
sys.stdout.write(question + prompt)
|
||||||
|
choice = input().lower()
|
||||||
|
if default is not None and choice == "":
|
||||||
|
return valid[default]
|
||||||
|
elif choice in valid:
|
||||||
|
return valid[choice]
|
||||||
|
else:
|
||||||
|
sys.stdout.write("Please respond with 'yes' or 'no' (or 'y' or 'n').\n")
|
||||||
|
|
||||||
|
|
||||||
|
class FileType:
|
||||||
|
"""Factory for creating file object types
|
||||||
|
|
||||||
|
Instances of FileType are typically passed as type= arguments to the
|
||||||
|
ArgumentParser add_argument() method.
|
||||||
|
|
||||||
|
Keyword Arguments:
|
||||||
|
- mode -- A string indicating how the file is to be opened. Accepts the
|
||||||
|
same values as the builtin open() function.
|
||||||
|
- bufsize -- The file's desired buffer size. Accepts the same values as
|
||||||
|
the builtin open() function.
|
||||||
|
- encoding -- The file's encoding. Accepts the same values as the
|
||||||
|
builtin open() function.
|
||||||
|
- errors -- A string indicating how encoding and decoding errors are to
|
||||||
|
be handled. Accepts the same value as the builtin open() function.
|
||||||
|
|
||||||
|
Backported from CPython 3.12
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
mode: str = "r",
|
||||||
|
bufsize: int = -1,
|
||||||
|
encoding: str | None = None,
|
||||||
|
errors: str | None = None,
|
||||||
|
):
|
||||||
|
self._mode = mode
|
||||||
|
self._bufsize = bufsize
|
||||||
|
self._encoding = encoding
|
||||||
|
self._errors = errors
|
||||||
|
|
||||||
|
def __call__(self, string: str) -> typing.IO: # type: ignore[type-arg]
|
||||||
|
# the special argument "-" means sys.std{in,out}
|
||||||
|
if string == "-":
|
||||||
|
if "r" in self._mode:
|
||||||
|
return sys.stdin.buffer if "b" in self._mode else sys.stdin
|
||||||
|
elif any(c in self._mode for c in "wax"):
|
||||||
|
return sys.stdout.buffer if "b" in self._mode else sys.stdout
|
||||||
|
else:
|
||||||
|
msg = f'argument "-" with mode {self._mode}'
|
||||||
|
raise ValueError(msg)
|
||||||
|
|
||||||
|
# all other arguments are used as file names
|
||||||
|
try:
|
||||||
|
return open(string, self._mode, self._bufsize, self._encoding, self._errors)
|
||||||
|
except OSError as e:
|
||||||
|
message = f"can't open '{string}': {e}"
|
||||||
|
raise argparse.ArgumentTypeError(message)
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
args = self._mode, self._bufsize
|
||||||
|
kwargs = [("encoding", self._encoding), ("errors", self._errors)]
|
||||||
|
args_str = ", ".join(
|
||||||
|
[repr(arg) for arg in args if arg != -1]
|
||||||
|
+ [f"{kw}={arg!r}" for kw, arg in kwargs if arg is not None]
|
||||||
|
)
|
||||||
|
return f"{type(self).__name__}({args_str})"
|
||||||
|
|
||||||
|
|
||||||
|
def cli_detect(argv: list[str] | None = None) -> int:
|
||||||
|
"""
|
||||||
|
CLI assistant using ARGV and ArgumentParser
|
||||||
|
:param argv:
|
||||||
|
:return: 0 if everything is fine, anything else equal trouble
|
||||||
|
"""
|
||||||
|
parser = argparse.ArgumentParser(
|
||||||
|
description="The Real First Universal Charset Detector. "
|
||||||
|
"Discover originating encoding used on text file. "
|
||||||
|
"Normalize text to unicode."
|
||||||
|
)
|
||||||
|
|
||||||
|
parser.add_argument(
|
||||||
|
"files", type=FileType("rb"), nargs="+", help="File(s) to be analysed"
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-v",
|
||||||
|
"--verbose",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="verbose",
|
||||||
|
help="Display complementary information about file if any. "
|
||||||
|
"Stdout will contain logs about the detection process.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-a",
|
||||||
|
"--with-alternative",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="alternatives",
|
||||||
|
help="Output complementary possibilities if any. Top-level JSON WILL be a list.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-n",
|
||||||
|
"--normalize",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="normalize",
|
||||||
|
help="Permit to normalize input file. If not set, program does not write anything.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-m",
|
||||||
|
"--minimal",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="minimal",
|
||||||
|
help="Only output the charset detected to STDOUT. Disabling JSON output.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-r",
|
||||||
|
"--replace",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="replace",
|
||||||
|
help="Replace file when trying to normalize it instead of creating a new one.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-f",
|
||||||
|
"--force",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="force",
|
||||||
|
help="Replace file without asking if you are sure, use this flag with caution.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-i",
|
||||||
|
"--no-preemptive",
|
||||||
|
action="store_true",
|
||||||
|
default=False,
|
||||||
|
dest="no_preemptive",
|
||||||
|
help="Disable looking at a charset declaration to hint the detector.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"-t",
|
||||||
|
"--threshold",
|
||||||
|
action="store",
|
||||||
|
default=0.2,
|
||||||
|
type=float,
|
||||||
|
dest="threshold",
|
||||||
|
help="Define a custom maximum amount of noise allowed in decoded content. 0. <= noise <= 1.",
|
||||||
|
)
|
||||||
|
parser.add_argument(
|
||||||
|
"--version",
|
||||||
|
action="version",
|
||||||
|
version="Charset-Normalizer {} - Python {} - Unicode {} - SpeedUp {}".format(
|
||||||
|
__version__,
|
||||||
|
python_version(),
|
||||||
|
unidata_version,
|
||||||
|
"OFF" if md_module.__file__.lower().endswith(".py") else "ON",
|
||||||
|
),
|
||||||
|
help="Show version information and exit.",
|
||||||
|
)
|
||||||
|
|
||||||
|
args = parser.parse_args(argv)
|
||||||
|
|
||||||
|
if args.replace is True and args.normalize is False:
|
||||||
|
if args.files:
|
||||||
|
for my_file in args.files:
|
||||||
|
my_file.close()
|
||||||
|
print("Use --replace in addition of --normalize only.", file=sys.stderr)
|
||||||
|
return 1
|
||||||
|
|
||||||
|
if args.force is True and args.replace is False:
|
||||||
|
if args.files:
|
||||||
|
for my_file in args.files:
|
||||||
|
my_file.close()
|
||||||
|
print("Use --force in addition of --replace only.", file=sys.stderr)
|
||||||
|
return 1
|
||||||
|
|
||||||
|
if args.threshold < 0.0 or args.threshold > 1.0:
|
||||||
|
if args.files:
|
||||||
|
for my_file in args.files:
|
||||||
|
my_file.close()
|
||||||
|
print("--threshold VALUE should be between 0. AND 1.", file=sys.stderr)
|
||||||
|
return 1
|
||||||
|
|
||||||
|
x_ = []
|
||||||
|
|
||||||
|
for my_file in args.files:
|
||||||
|
matches = from_fp(
|
||||||
|
my_file,
|
||||||
|
threshold=args.threshold,
|
||||||
|
explain=args.verbose,
|
||||||
|
preemptive_behaviour=args.no_preemptive is False,
|
||||||
|
)
|
||||||
|
|
||||||
|
best_guess = matches.best()
|
||||||
|
|
||||||
|
if best_guess is None:
|
||||||
|
print(
|
||||||
|
'Unable to identify originating encoding for "{}". {}'.format(
|
||||||
|
my_file.name,
|
||||||
|
(
|
||||||
|
"Maybe try increasing maximum amount of chaos."
|
||||||
|
if args.threshold < 1.0
|
||||||
|
else ""
|
||||||
|
),
|
||||||
|
),
|
||||||
|
file=sys.stderr,
|
||||||
|
)
|
||||||
|
x_.append(
|
||||||
|
CliDetectionResult(
|
||||||
|
abspath(my_file.name),
|
||||||
|
None,
|
||||||
|
[],
|
||||||
|
[],
|
||||||
|
"Unknown",
|
||||||
|
[],
|
||||||
|
False,
|
||||||
|
1.0,
|
||||||
|
0.0,
|
||||||
|
None,
|
||||||
|
True,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
x_.append(
|
||||||
|
CliDetectionResult(
|
||||||
|
abspath(my_file.name),
|
||||||
|
best_guess.encoding,
|
||||||
|
best_guess.encoding_aliases,
|
||||||
|
[
|
||||||
|
cp
|
||||||
|
for cp in best_guess.could_be_from_charset
|
||||||
|
if cp != best_guess.encoding
|
||||||
|
],
|
||||||
|
best_guess.language,
|
||||||
|
best_guess.alphabets,
|
||||||
|
best_guess.bom,
|
||||||
|
best_guess.percent_chaos,
|
||||||
|
best_guess.percent_coherence,
|
||||||
|
None,
|
||||||
|
True,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(matches) > 1 and args.alternatives:
|
||||||
|
for el in matches:
|
||||||
|
if el != best_guess:
|
||||||
|
x_.append(
|
||||||
|
CliDetectionResult(
|
||||||
|
abspath(my_file.name),
|
||||||
|
el.encoding,
|
||||||
|
el.encoding_aliases,
|
||||||
|
[
|
||||||
|
cp
|
||||||
|
for cp in el.could_be_from_charset
|
||||||
|
if cp != el.encoding
|
||||||
|
],
|
||||||
|
el.language,
|
||||||
|
el.alphabets,
|
||||||
|
el.bom,
|
||||||
|
el.percent_chaos,
|
||||||
|
el.percent_coherence,
|
||||||
|
None,
|
||||||
|
False,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
if args.normalize is True:
|
||||||
|
if best_guess.encoding.startswith("utf") is True:
|
||||||
|
print(
|
||||||
|
'"{}" file does not need to be normalized, as it already came from unicode.'.format(
|
||||||
|
my_file.name
|
||||||
|
),
|
||||||
|
file=sys.stderr,
|
||||||
|
)
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
continue
|
||||||
|
|
||||||
|
dir_path = dirname(realpath(my_file.name))
|
||||||
|
file_name = basename(realpath(my_file.name))
|
||||||
|
|
||||||
|
o_: list[str] = file_name.split(".")
|
||||||
|
|
||||||
|
if args.replace is False:
|
||||||
|
o_.insert(-1, best_guess.encoding)
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
elif (
|
||||||
|
args.force is False
|
||||||
|
and query_yes_no(
|
||||||
|
'Are you sure to normalize "{}" by replacing it ?'.format(
|
||||||
|
my_file.name
|
||||||
|
),
|
||||||
|
"no",
|
||||||
|
)
|
||||||
|
is False
|
||||||
|
):
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
continue
|
||||||
|
|
||||||
|
try:
|
||||||
|
x_[0].unicode_path = join(dir_path, ".".join(o_))
|
||||||
|
|
||||||
|
with open(x_[0].unicode_path, "wb") as fp:
|
||||||
|
fp.write(best_guess.output())
|
||||||
|
except OSError as e:
|
||||||
|
print(str(e), file=sys.stderr)
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
return 2
|
||||||
|
|
||||||
|
if my_file.closed is False:
|
||||||
|
my_file.close()
|
||||||
|
|
||||||
|
if args.minimal is False:
|
||||||
|
print(
|
||||||
|
dumps(
|
||||||
|
[el.__dict__ for el in x_] if len(x_) > 1 else x_[0].__dict__,
|
||||||
|
ensure_ascii=True,
|
||||||
|
indent=4,
|
||||||
|
)
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
for my_file in args.files:
|
||||||
|
print(
|
||||||
|
", ".join(
|
||||||
|
[
|
||||||
|
el.encoding or "undefined"
|
||||||
|
for el in x_
|
||||||
|
if el.path == abspath(my_file.name)
|
||||||
|
]
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
return 0
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
cli_detect()
|
||||||
2015
venv/lib/python3.12/site-packages/charset_normalizer/constant.py
Normal file
2015
venv/lib/python3.12/site-packages/charset_normalizer/constant.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,80 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from typing import TYPE_CHECKING, Any
|
||||||
|
from warnings import warn
|
||||||
|
|
||||||
|
from .api import from_bytes
|
||||||
|
from .constant import CHARDET_CORRESPONDENCE, TOO_SMALL_SEQUENCE
|
||||||
|
|
||||||
|
# TODO: remove this check when dropping Python 3.7 support
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from typing_extensions import TypedDict
|
||||||
|
|
||||||
|
class ResultDict(TypedDict):
|
||||||
|
encoding: str | None
|
||||||
|
language: str
|
||||||
|
confidence: float | None
|
||||||
|
|
||||||
|
|
||||||
|
def detect(
|
||||||
|
byte_str: bytes, should_rename_legacy: bool = False, **kwargs: Any
|
||||||
|
) -> ResultDict:
|
||||||
|
"""
|
||||||
|
chardet legacy method
|
||||||
|
Detect the encoding of the given byte string. It should be mostly backward-compatible.
|
||||||
|
Encoding name will match Chardet own writing whenever possible. (Not on encoding name unsupported by it)
|
||||||
|
This function is deprecated and should be used to migrate your project easily, consult the documentation for
|
||||||
|
further information. Not planned for removal.
|
||||||
|
|
||||||
|
:param byte_str: The byte sequence to examine.
|
||||||
|
:param should_rename_legacy: Should we rename legacy encodings
|
||||||
|
to their more modern equivalents?
|
||||||
|
"""
|
||||||
|
if len(kwargs):
|
||||||
|
warn(
|
||||||
|
f"charset-normalizer disregard arguments '{','.join(list(kwargs.keys()))}' in legacy function detect()"
|
||||||
|
)
|
||||||
|
|
||||||
|
if not isinstance(byte_str, (bytearray, bytes)):
|
||||||
|
raise TypeError( # pragma: nocover
|
||||||
|
f"Expected object of type bytes or bytearray, got: {type(byte_str)}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if isinstance(byte_str, bytearray):
|
||||||
|
byte_str = bytes(byte_str)
|
||||||
|
|
||||||
|
r = from_bytes(byte_str).best()
|
||||||
|
|
||||||
|
encoding = r.encoding if r is not None else None
|
||||||
|
language = r.language if r is not None and r.language != "Unknown" else ""
|
||||||
|
confidence = 1.0 - r.chaos if r is not None else None
|
||||||
|
|
||||||
|
# automatically lower confidence
|
||||||
|
# on small bytes samples.
|
||||||
|
# https://github.com/jawah/charset_normalizer/issues/391
|
||||||
|
if (
|
||||||
|
confidence is not None
|
||||||
|
and confidence >= 0.9
|
||||||
|
and encoding
|
||||||
|
not in {
|
||||||
|
"utf_8",
|
||||||
|
"ascii",
|
||||||
|
}
|
||||||
|
and r.bom is False # type: ignore[union-attr]
|
||||||
|
and len(byte_str) < TOO_SMALL_SEQUENCE
|
||||||
|
):
|
||||||
|
confidence -= 0.2
|
||||||
|
|
||||||
|
# Note: CharsetNormalizer does not return 'UTF-8-SIG' as the sig get stripped in the detection/normalization process
|
||||||
|
# but chardet does return 'utf-8-sig' and it is a valid codec name.
|
||||||
|
if r is not None and encoding == "utf_8" and r.bom:
|
||||||
|
encoding += "_sig"
|
||||||
|
|
||||||
|
if should_rename_legacy is False and encoding in CHARDET_CORRESPONDENCE:
|
||||||
|
encoding = CHARDET_CORRESPONDENCE[encoding]
|
||||||
|
|
||||||
|
return {
|
||||||
|
"encoding": encoding,
|
||||||
|
"language": language,
|
||||||
|
"confidence": confidence,
|
||||||
|
}
|
||||||
Binary file not shown.
635
venv/lib/python3.12/site-packages/charset_normalizer/md.py
Normal file
635
venv/lib/python3.12/site-packages/charset_normalizer/md.py
Normal file
@@ -0,0 +1,635 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from functools import lru_cache
|
||||||
|
from logging import getLogger
|
||||||
|
|
||||||
|
from .constant import (
|
||||||
|
COMMON_SAFE_ASCII_CHARACTERS,
|
||||||
|
TRACE,
|
||||||
|
UNICODE_SECONDARY_RANGE_KEYWORD,
|
||||||
|
)
|
||||||
|
from .utils import (
|
||||||
|
is_accentuated,
|
||||||
|
is_arabic,
|
||||||
|
is_arabic_isolated_form,
|
||||||
|
is_case_variable,
|
||||||
|
is_cjk,
|
||||||
|
is_emoticon,
|
||||||
|
is_hangul,
|
||||||
|
is_hiragana,
|
||||||
|
is_katakana,
|
||||||
|
is_latin,
|
||||||
|
is_punctuation,
|
||||||
|
is_separator,
|
||||||
|
is_symbol,
|
||||||
|
is_thai,
|
||||||
|
is_unprintable,
|
||||||
|
remove_accent,
|
||||||
|
unicode_range,
|
||||||
|
is_cjk_uncommon,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class MessDetectorPlugin:
|
||||||
|
"""
|
||||||
|
Base abstract class used for mess detection plugins.
|
||||||
|
All detectors MUST extend and implement given methods.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
"""
|
||||||
|
Determine if given character should be fed in.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError # pragma: nocover
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
"""
|
||||||
|
The main routine to be executed upon character.
|
||||||
|
Insert the logic in witch the text would be considered chaotic.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError # pragma: nocover
|
||||||
|
|
||||||
|
def reset(self) -> None: # pragma: no cover
|
||||||
|
"""
|
||||||
|
Permit to reset the plugin to the initial state.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
"""
|
||||||
|
Compute the chaos ratio based on what your feed() has seen.
|
||||||
|
Must NOT be lower than 0.; No restriction gt 0.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError # pragma: nocover
|
||||||
|
|
||||||
|
|
||||||
|
class TooManySymbolOrPunctuationPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._punctuation_count: int = 0
|
||||||
|
self._symbol_count: int = 0
|
||||||
|
self._character_count: int = 0
|
||||||
|
|
||||||
|
self._last_printable_char: str | None = None
|
||||||
|
self._frenzy_symbol_in_word: bool = False
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return character.isprintable()
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if (
|
||||||
|
character != self._last_printable_char
|
||||||
|
and character not in COMMON_SAFE_ASCII_CHARACTERS
|
||||||
|
):
|
||||||
|
if is_punctuation(character):
|
||||||
|
self._punctuation_count += 1
|
||||||
|
elif (
|
||||||
|
character.isdigit() is False
|
||||||
|
and is_symbol(character)
|
||||||
|
and is_emoticon(character) is False
|
||||||
|
):
|
||||||
|
self._symbol_count += 2
|
||||||
|
|
||||||
|
self._last_printable_char = character
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._punctuation_count = 0
|
||||||
|
self._character_count = 0
|
||||||
|
self._symbol_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
ratio_of_punctuation: float = (
|
||||||
|
self._punctuation_count + self._symbol_count
|
||||||
|
) / self._character_count
|
||||||
|
|
||||||
|
return ratio_of_punctuation if ratio_of_punctuation >= 0.3 else 0.0
|
||||||
|
|
||||||
|
|
||||||
|
class TooManyAccentuatedPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._accentuated_count: int = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return character.isalpha()
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if is_accentuated(character):
|
||||||
|
self._accentuated_count += 1
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._character_count = 0
|
||||||
|
self._accentuated_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count < 8:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
ratio_of_accentuation: float = self._accentuated_count / self._character_count
|
||||||
|
return ratio_of_accentuation if ratio_of_accentuation >= 0.35 else 0.0
|
||||||
|
|
||||||
|
|
||||||
|
class UnprintablePlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._unprintable_count: int = 0
|
||||||
|
self._character_count: int = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
if is_unprintable(character):
|
||||||
|
self._unprintable_count += 1
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._unprintable_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
return (self._unprintable_count * 8) / self._character_count
|
||||||
|
|
||||||
|
|
||||||
|
class SuspiciousDuplicateAccentPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._successive_count: int = 0
|
||||||
|
self._character_count: int = 0
|
||||||
|
|
||||||
|
self._last_latin_character: str | None = None
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return character.isalpha() and is_latin(character)
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
if (
|
||||||
|
self._last_latin_character is not None
|
||||||
|
and is_accentuated(character)
|
||||||
|
and is_accentuated(self._last_latin_character)
|
||||||
|
):
|
||||||
|
if character.isupper() and self._last_latin_character.isupper():
|
||||||
|
self._successive_count += 1
|
||||||
|
# Worse if its the same char duplicated with different accent.
|
||||||
|
if remove_accent(character) == remove_accent(self._last_latin_character):
|
||||||
|
self._successive_count += 1
|
||||||
|
self._last_latin_character = character
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._successive_count = 0
|
||||||
|
self._character_count = 0
|
||||||
|
self._last_latin_character = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
return (self._successive_count * 2) / self._character_count
|
||||||
|
|
||||||
|
|
||||||
|
class SuspiciousRange(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._suspicious_successive_range_count: int = 0
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._last_printable_seen: str | None = None
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return character.isprintable()
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if (
|
||||||
|
character.isspace()
|
||||||
|
or is_punctuation(character)
|
||||||
|
or character in COMMON_SAFE_ASCII_CHARACTERS
|
||||||
|
):
|
||||||
|
self._last_printable_seen = None
|
||||||
|
return
|
||||||
|
|
||||||
|
if self._last_printable_seen is None:
|
||||||
|
self._last_printable_seen = character
|
||||||
|
return
|
||||||
|
|
||||||
|
unicode_range_a: str | None = unicode_range(self._last_printable_seen)
|
||||||
|
unicode_range_b: str | None = unicode_range(character)
|
||||||
|
|
||||||
|
if is_suspiciously_successive_range(unicode_range_a, unicode_range_b):
|
||||||
|
self._suspicious_successive_range_count += 1
|
||||||
|
|
||||||
|
self._last_printable_seen = character
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._character_count = 0
|
||||||
|
self._suspicious_successive_range_count = 0
|
||||||
|
self._last_printable_seen = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count <= 13:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
ratio_of_suspicious_range_usage: float = (
|
||||||
|
self._suspicious_successive_range_count * 2
|
||||||
|
) / self._character_count
|
||||||
|
|
||||||
|
return ratio_of_suspicious_range_usage
|
||||||
|
|
||||||
|
|
||||||
|
class SuperWeirdWordPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._word_count: int = 0
|
||||||
|
self._bad_word_count: int = 0
|
||||||
|
self._foreign_long_count: int = 0
|
||||||
|
|
||||||
|
self._is_current_word_bad: bool = False
|
||||||
|
self._foreign_long_watch: bool = False
|
||||||
|
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._bad_character_count: int = 0
|
||||||
|
|
||||||
|
self._buffer: str = ""
|
||||||
|
self._buffer_accent_count: int = 0
|
||||||
|
self._buffer_glyph_count: int = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
if character.isalpha():
|
||||||
|
self._buffer += character
|
||||||
|
if is_accentuated(character):
|
||||||
|
self._buffer_accent_count += 1
|
||||||
|
if (
|
||||||
|
self._foreign_long_watch is False
|
||||||
|
and (is_latin(character) is False or is_accentuated(character))
|
||||||
|
and is_cjk(character) is False
|
||||||
|
and is_hangul(character) is False
|
||||||
|
and is_katakana(character) is False
|
||||||
|
and is_hiragana(character) is False
|
||||||
|
and is_thai(character) is False
|
||||||
|
):
|
||||||
|
self._foreign_long_watch = True
|
||||||
|
if (
|
||||||
|
is_cjk(character)
|
||||||
|
or is_hangul(character)
|
||||||
|
or is_katakana(character)
|
||||||
|
or is_hiragana(character)
|
||||||
|
or is_thai(character)
|
||||||
|
):
|
||||||
|
self._buffer_glyph_count += 1
|
||||||
|
return
|
||||||
|
if not self._buffer:
|
||||||
|
return
|
||||||
|
if (
|
||||||
|
character.isspace() or is_punctuation(character) or is_separator(character)
|
||||||
|
) and self._buffer:
|
||||||
|
self._word_count += 1
|
||||||
|
buffer_length: int = len(self._buffer)
|
||||||
|
|
||||||
|
self._character_count += buffer_length
|
||||||
|
|
||||||
|
if buffer_length >= 4:
|
||||||
|
if self._buffer_accent_count / buffer_length >= 0.5:
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
# Word/Buffer ending with an upper case accentuated letter are so rare,
|
||||||
|
# that we will consider them all as suspicious. Same weight as foreign_long suspicious.
|
||||||
|
elif (
|
||||||
|
is_accentuated(self._buffer[-1])
|
||||||
|
and self._buffer[-1].isupper()
|
||||||
|
and all(_.isupper() for _ in self._buffer) is False
|
||||||
|
):
|
||||||
|
self._foreign_long_count += 1
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
elif self._buffer_glyph_count == 1:
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
self._foreign_long_count += 1
|
||||||
|
if buffer_length >= 24 and self._foreign_long_watch:
|
||||||
|
camel_case_dst = [
|
||||||
|
i
|
||||||
|
for c, i in zip(self._buffer, range(0, buffer_length))
|
||||||
|
if c.isupper()
|
||||||
|
]
|
||||||
|
probable_camel_cased: bool = False
|
||||||
|
|
||||||
|
if camel_case_dst and (len(camel_case_dst) / buffer_length <= 0.3):
|
||||||
|
probable_camel_cased = True
|
||||||
|
|
||||||
|
if not probable_camel_cased:
|
||||||
|
self._foreign_long_count += 1
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
|
||||||
|
if self._is_current_word_bad:
|
||||||
|
self._bad_word_count += 1
|
||||||
|
self._bad_character_count += len(self._buffer)
|
||||||
|
self._is_current_word_bad = False
|
||||||
|
|
||||||
|
self._foreign_long_watch = False
|
||||||
|
self._buffer = ""
|
||||||
|
self._buffer_accent_count = 0
|
||||||
|
self._buffer_glyph_count = 0
|
||||||
|
elif (
|
||||||
|
character not in {"<", ">", "-", "=", "~", "|", "_"}
|
||||||
|
and character.isdigit() is False
|
||||||
|
and is_symbol(character)
|
||||||
|
):
|
||||||
|
self._is_current_word_bad = True
|
||||||
|
self._buffer += character
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._buffer = ""
|
||||||
|
self._is_current_word_bad = False
|
||||||
|
self._foreign_long_watch = False
|
||||||
|
self._bad_word_count = 0
|
||||||
|
self._word_count = 0
|
||||||
|
self._character_count = 0
|
||||||
|
self._bad_character_count = 0
|
||||||
|
self._foreign_long_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._word_count <= 10 and self._foreign_long_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
return self._bad_character_count / self._character_count
|
||||||
|
|
||||||
|
|
||||||
|
class CjkUncommonPlugin(MessDetectorPlugin):
|
||||||
|
"""
|
||||||
|
Detect messy CJK text that probably means nothing.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._uncommon_count: int = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return is_cjk(character)
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if is_cjk_uncommon(character):
|
||||||
|
self._uncommon_count += 1
|
||||||
|
return
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._character_count = 0
|
||||||
|
self._uncommon_count = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count < 8:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
uncommon_form_usage: float = self._uncommon_count / self._character_count
|
||||||
|
|
||||||
|
# we can be pretty sure it's garbage when uncommon characters are widely
|
||||||
|
# used. otherwise it could just be traditional chinese for example.
|
||||||
|
return uncommon_form_usage / 10 if uncommon_form_usage > 0.5 else 0.0
|
||||||
|
|
||||||
|
|
||||||
|
class ArchaicUpperLowerPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._buf: bool = False
|
||||||
|
|
||||||
|
self._character_count_since_last_sep: int = 0
|
||||||
|
|
||||||
|
self._successive_upper_lower_count: int = 0
|
||||||
|
self._successive_upper_lower_count_final: int = 0
|
||||||
|
|
||||||
|
self._character_count: int = 0
|
||||||
|
|
||||||
|
self._last_alpha_seen: str | None = None
|
||||||
|
self._current_ascii_only: bool = True
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
is_concerned = character.isalpha() and is_case_variable(character)
|
||||||
|
chunk_sep = is_concerned is False
|
||||||
|
|
||||||
|
if chunk_sep and self._character_count_since_last_sep > 0:
|
||||||
|
if (
|
||||||
|
self._character_count_since_last_sep <= 64
|
||||||
|
and character.isdigit() is False
|
||||||
|
and self._current_ascii_only is False
|
||||||
|
):
|
||||||
|
self._successive_upper_lower_count_final += (
|
||||||
|
self._successive_upper_lower_count
|
||||||
|
)
|
||||||
|
|
||||||
|
self._successive_upper_lower_count = 0
|
||||||
|
self._character_count_since_last_sep = 0
|
||||||
|
self._last_alpha_seen = None
|
||||||
|
self._buf = False
|
||||||
|
self._character_count += 1
|
||||||
|
self._current_ascii_only = True
|
||||||
|
|
||||||
|
return
|
||||||
|
|
||||||
|
if self._current_ascii_only is True and character.isascii() is False:
|
||||||
|
self._current_ascii_only = False
|
||||||
|
|
||||||
|
if self._last_alpha_seen is not None:
|
||||||
|
if (character.isupper() and self._last_alpha_seen.islower()) or (
|
||||||
|
character.islower() and self._last_alpha_seen.isupper()
|
||||||
|
):
|
||||||
|
if self._buf is True:
|
||||||
|
self._successive_upper_lower_count += 2
|
||||||
|
self._buf = False
|
||||||
|
else:
|
||||||
|
self._buf = True
|
||||||
|
else:
|
||||||
|
self._buf = False
|
||||||
|
|
||||||
|
self._character_count += 1
|
||||||
|
self._character_count_since_last_sep += 1
|
||||||
|
self._last_alpha_seen = character
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._character_count = 0
|
||||||
|
self._character_count_since_last_sep = 0
|
||||||
|
self._successive_upper_lower_count = 0
|
||||||
|
self._successive_upper_lower_count_final = 0
|
||||||
|
self._last_alpha_seen = None
|
||||||
|
self._buf = False
|
||||||
|
self._current_ascii_only = True
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count == 0:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
return self._successive_upper_lower_count_final / self._character_count
|
||||||
|
|
||||||
|
|
||||||
|
class ArabicIsolatedFormPlugin(MessDetectorPlugin):
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._character_count: int = 0
|
||||||
|
self._isolated_form_count: int = 0
|
||||||
|
|
||||||
|
def reset(self) -> None: # Abstract
|
||||||
|
self._character_count = 0
|
||||||
|
self._isolated_form_count = 0
|
||||||
|
|
||||||
|
def eligible(self, character: str) -> bool:
|
||||||
|
return is_arabic(character)
|
||||||
|
|
||||||
|
def feed(self, character: str) -> None:
|
||||||
|
self._character_count += 1
|
||||||
|
|
||||||
|
if is_arabic_isolated_form(character):
|
||||||
|
self._isolated_form_count += 1
|
||||||
|
|
||||||
|
@property
|
||||||
|
def ratio(self) -> float:
|
||||||
|
if self._character_count < 8:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
isolated_form_usage: float = self._isolated_form_count / self._character_count
|
||||||
|
|
||||||
|
return isolated_form_usage
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=1024)
|
||||||
|
def is_suspiciously_successive_range(
|
||||||
|
unicode_range_a: str | None, unicode_range_b: str | None
|
||||||
|
) -> bool:
|
||||||
|
"""
|
||||||
|
Determine if two Unicode range seen next to each other can be considered as suspicious.
|
||||||
|
"""
|
||||||
|
if unicode_range_a is None or unicode_range_b is None:
|
||||||
|
return True
|
||||||
|
|
||||||
|
if unicode_range_a == unicode_range_b:
|
||||||
|
return False
|
||||||
|
|
||||||
|
if "Latin" in unicode_range_a and "Latin" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
|
||||||
|
if "Emoticons" in unicode_range_a or "Emoticons" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Latin characters can be accompanied with a combining diacritical mark
|
||||||
|
# eg. Vietnamese.
|
||||||
|
if ("Latin" in unicode_range_a or "Latin" in unicode_range_b) and (
|
||||||
|
"Combining" in unicode_range_a or "Combining" in unicode_range_b
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
|
||||||
|
keywords_range_a, keywords_range_b = (
|
||||||
|
unicode_range_a.split(" "),
|
||||||
|
unicode_range_b.split(" "),
|
||||||
|
)
|
||||||
|
|
||||||
|
for el in keywords_range_a:
|
||||||
|
if el in UNICODE_SECONDARY_RANGE_KEYWORD:
|
||||||
|
continue
|
||||||
|
if el in keywords_range_b:
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Japanese Exception
|
||||||
|
range_a_jp_chars, range_b_jp_chars = (
|
||||||
|
unicode_range_a
|
||||||
|
in (
|
||||||
|
"Hiragana",
|
||||||
|
"Katakana",
|
||||||
|
),
|
||||||
|
unicode_range_b in ("Hiragana", "Katakana"),
|
||||||
|
)
|
||||||
|
if (range_a_jp_chars or range_b_jp_chars) and (
|
||||||
|
"CJK" in unicode_range_a or "CJK" in unicode_range_b
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
if range_a_jp_chars and range_b_jp_chars:
|
||||||
|
return False
|
||||||
|
|
||||||
|
if "Hangul" in unicode_range_a or "Hangul" in unicode_range_b:
|
||||||
|
if "CJK" in unicode_range_a or "CJK" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
if unicode_range_a == "Basic Latin" or unicode_range_b == "Basic Latin":
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Chinese/Japanese use dedicated range for punctuation and/or separators.
|
||||||
|
if ("CJK" in unicode_range_a or "CJK" in unicode_range_b) or (
|
||||||
|
unicode_range_a in ["Katakana", "Hiragana"]
|
||||||
|
and unicode_range_b in ["Katakana", "Hiragana"]
|
||||||
|
):
|
||||||
|
if "Punctuation" in unicode_range_a or "Punctuation" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
if "Forms" in unicode_range_a or "Forms" in unicode_range_b:
|
||||||
|
return False
|
||||||
|
if unicode_range_a == "Basic Latin" or unicode_range_b == "Basic Latin":
|
||||||
|
return False
|
||||||
|
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=2048)
|
||||||
|
def mess_ratio(
|
||||||
|
decoded_sequence: str, maximum_threshold: float = 0.2, debug: bool = False
|
||||||
|
) -> float:
|
||||||
|
"""
|
||||||
|
Compute a mess ratio given a decoded bytes sequence. The maximum threshold does stop the computation earlier.
|
||||||
|
"""
|
||||||
|
|
||||||
|
detectors: list[MessDetectorPlugin] = [
|
||||||
|
md_class() for md_class in MessDetectorPlugin.__subclasses__()
|
||||||
|
]
|
||||||
|
|
||||||
|
length: int = len(decoded_sequence) + 1
|
||||||
|
|
||||||
|
mean_mess_ratio: float = 0.0
|
||||||
|
|
||||||
|
if length < 512:
|
||||||
|
intermediary_mean_mess_ratio_calc: int = 32
|
||||||
|
elif length <= 1024:
|
||||||
|
intermediary_mean_mess_ratio_calc = 64
|
||||||
|
else:
|
||||||
|
intermediary_mean_mess_ratio_calc = 128
|
||||||
|
|
||||||
|
for character, index in zip(decoded_sequence + "\n", range(length)):
|
||||||
|
for detector in detectors:
|
||||||
|
if detector.eligible(character):
|
||||||
|
detector.feed(character)
|
||||||
|
|
||||||
|
if (
|
||||||
|
index > 0 and index % intermediary_mean_mess_ratio_calc == 0
|
||||||
|
) or index == length - 1:
|
||||||
|
mean_mess_ratio = sum(dt.ratio for dt in detectors)
|
||||||
|
|
||||||
|
if mean_mess_ratio >= maximum_threshold:
|
||||||
|
break
|
||||||
|
|
||||||
|
if debug:
|
||||||
|
logger = getLogger("charset_normalizer")
|
||||||
|
|
||||||
|
logger.log(
|
||||||
|
TRACE,
|
||||||
|
"Mess-detector extended-analysis start. "
|
||||||
|
f"intermediary_mean_mess_ratio_calc={intermediary_mean_mess_ratio_calc} mean_mess_ratio={mean_mess_ratio} "
|
||||||
|
f"maximum_threshold={maximum_threshold}",
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(decoded_sequence) > 16:
|
||||||
|
logger.log(TRACE, f"Starting with: {decoded_sequence[:16]}")
|
||||||
|
logger.log(TRACE, f"Ending with: {decoded_sequence[-16::]}")
|
||||||
|
|
||||||
|
for dt in detectors:
|
||||||
|
logger.log(TRACE, f"{dt.__class__}: {dt.ratio}")
|
||||||
|
|
||||||
|
return round(mean_mess_ratio, 3)
|
||||||
Binary file not shown.
360
venv/lib/python3.12/site-packages/charset_normalizer/models.py
Normal file
360
venv/lib/python3.12/site-packages/charset_normalizer/models.py
Normal file
@@ -0,0 +1,360 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from encodings.aliases import aliases
|
||||||
|
from hashlib import sha256
|
||||||
|
from json import dumps
|
||||||
|
from re import sub
|
||||||
|
from typing import Any, Iterator, List, Tuple
|
||||||
|
|
||||||
|
from .constant import RE_POSSIBLE_ENCODING_INDICATION, TOO_BIG_SEQUENCE
|
||||||
|
from .utils import iana_name, is_multi_byte_encoding, unicode_range
|
||||||
|
|
||||||
|
|
||||||
|
class CharsetMatch:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
payload: bytes,
|
||||||
|
guessed_encoding: str,
|
||||||
|
mean_mess_ratio: float,
|
||||||
|
has_sig_or_bom: bool,
|
||||||
|
languages: CoherenceMatches,
|
||||||
|
decoded_payload: str | None = None,
|
||||||
|
preemptive_declaration: str | None = None,
|
||||||
|
):
|
||||||
|
self._payload: bytes = payload
|
||||||
|
|
||||||
|
self._encoding: str = guessed_encoding
|
||||||
|
self._mean_mess_ratio: float = mean_mess_ratio
|
||||||
|
self._languages: CoherenceMatches = languages
|
||||||
|
self._has_sig_or_bom: bool = has_sig_or_bom
|
||||||
|
self._unicode_ranges: list[str] | None = None
|
||||||
|
|
||||||
|
self._leaves: list[CharsetMatch] = []
|
||||||
|
self._mean_coherence_ratio: float = 0.0
|
||||||
|
|
||||||
|
self._output_payload: bytes | None = None
|
||||||
|
self._output_encoding: str | None = None
|
||||||
|
|
||||||
|
self._string: str | None = decoded_payload
|
||||||
|
|
||||||
|
self._preemptive_declaration: str | None = preemptive_declaration
|
||||||
|
|
||||||
|
def __eq__(self, other: object) -> bool:
|
||||||
|
if not isinstance(other, CharsetMatch):
|
||||||
|
if isinstance(other, str):
|
||||||
|
return iana_name(other) == self.encoding
|
||||||
|
return False
|
||||||
|
return self.encoding == other.encoding and self.fingerprint == other.fingerprint
|
||||||
|
|
||||||
|
def __lt__(self, other: object) -> bool:
|
||||||
|
"""
|
||||||
|
Implemented to make sorted available upon CharsetMatches items.
|
||||||
|
"""
|
||||||
|
if not isinstance(other, CharsetMatch):
|
||||||
|
raise ValueError
|
||||||
|
|
||||||
|
chaos_difference: float = abs(self.chaos - other.chaos)
|
||||||
|
coherence_difference: float = abs(self.coherence - other.coherence)
|
||||||
|
|
||||||
|
# Below 1% difference --> Use Coherence
|
||||||
|
if chaos_difference < 0.01 and coherence_difference > 0.02:
|
||||||
|
return self.coherence > other.coherence
|
||||||
|
elif chaos_difference < 0.01 and coherence_difference <= 0.02:
|
||||||
|
# When having a difficult decision, use the result that decoded as many multi-byte as possible.
|
||||||
|
# preserve RAM usage!
|
||||||
|
if len(self._payload) >= TOO_BIG_SEQUENCE:
|
||||||
|
return self.chaos < other.chaos
|
||||||
|
return self.multi_byte_usage > other.multi_byte_usage
|
||||||
|
|
||||||
|
return self.chaos < other.chaos
|
||||||
|
|
||||||
|
@property
|
||||||
|
def multi_byte_usage(self) -> float:
|
||||||
|
return 1.0 - (len(str(self)) / len(self.raw))
|
||||||
|
|
||||||
|
def __str__(self) -> str:
|
||||||
|
# Lazy Str Loading
|
||||||
|
if self._string is None:
|
||||||
|
self._string = str(self._payload, self._encoding, "strict")
|
||||||
|
return self._string
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
return f"<CharsetMatch '{self.encoding}' bytes({self.fingerprint})>"
|
||||||
|
|
||||||
|
def add_submatch(self, other: CharsetMatch) -> None:
|
||||||
|
if not isinstance(other, CharsetMatch) or other == self:
|
||||||
|
raise ValueError(
|
||||||
|
"Unable to add instance <{}> as a submatch of a CharsetMatch".format(
|
||||||
|
other.__class__
|
||||||
|
)
|
||||||
|
)
|
||||||
|
|
||||||
|
other._string = None # Unload RAM usage; dirty trick.
|
||||||
|
self._leaves.append(other)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def encoding(self) -> str:
|
||||||
|
return self._encoding
|
||||||
|
|
||||||
|
@property
|
||||||
|
def encoding_aliases(self) -> list[str]:
|
||||||
|
"""
|
||||||
|
Encoding name are known by many name, using this could help when searching for IBM855 when it's listed as CP855.
|
||||||
|
"""
|
||||||
|
also_known_as: list[str] = []
|
||||||
|
for u, p in aliases.items():
|
||||||
|
if self.encoding == u:
|
||||||
|
also_known_as.append(p)
|
||||||
|
elif self.encoding == p:
|
||||||
|
also_known_as.append(u)
|
||||||
|
return also_known_as
|
||||||
|
|
||||||
|
@property
|
||||||
|
def bom(self) -> bool:
|
||||||
|
return self._has_sig_or_bom
|
||||||
|
|
||||||
|
@property
|
||||||
|
def byte_order_mark(self) -> bool:
|
||||||
|
return self._has_sig_or_bom
|
||||||
|
|
||||||
|
@property
|
||||||
|
def languages(self) -> list[str]:
|
||||||
|
"""
|
||||||
|
Return the complete list of possible languages found in decoded sequence.
|
||||||
|
Usually not really useful. Returned list may be empty even if 'language' property return something != 'Unknown'.
|
||||||
|
"""
|
||||||
|
return [e[0] for e in self._languages]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def language(self) -> str:
|
||||||
|
"""
|
||||||
|
Most probable language found in decoded sequence. If none were detected or inferred, the property will return
|
||||||
|
"Unknown".
|
||||||
|
"""
|
||||||
|
if not self._languages:
|
||||||
|
# Trying to infer the language based on the given encoding
|
||||||
|
# Its either English or we should not pronounce ourselves in certain cases.
|
||||||
|
if "ascii" in self.could_be_from_charset:
|
||||||
|
return "English"
|
||||||
|
|
||||||
|
# doing it there to avoid circular import
|
||||||
|
from charset_normalizer.cd import encoding_languages, mb_encoding_languages
|
||||||
|
|
||||||
|
languages = (
|
||||||
|
mb_encoding_languages(self.encoding)
|
||||||
|
if is_multi_byte_encoding(self.encoding)
|
||||||
|
else encoding_languages(self.encoding)
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(languages) == 0 or "Latin Based" in languages:
|
||||||
|
return "Unknown"
|
||||||
|
|
||||||
|
return languages[0]
|
||||||
|
|
||||||
|
return self._languages[0][0]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def chaos(self) -> float:
|
||||||
|
return self._mean_mess_ratio
|
||||||
|
|
||||||
|
@property
|
||||||
|
def coherence(self) -> float:
|
||||||
|
if not self._languages:
|
||||||
|
return 0.0
|
||||||
|
return self._languages[0][1]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def percent_chaos(self) -> float:
|
||||||
|
return round(self.chaos * 100, ndigits=3)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def percent_coherence(self) -> float:
|
||||||
|
return round(self.coherence * 100, ndigits=3)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def raw(self) -> bytes:
|
||||||
|
"""
|
||||||
|
Original untouched bytes.
|
||||||
|
"""
|
||||||
|
return self._payload
|
||||||
|
|
||||||
|
@property
|
||||||
|
def submatch(self) -> list[CharsetMatch]:
|
||||||
|
return self._leaves
|
||||||
|
|
||||||
|
@property
|
||||||
|
def has_submatch(self) -> bool:
|
||||||
|
return len(self._leaves) > 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def alphabets(self) -> list[str]:
|
||||||
|
if self._unicode_ranges is not None:
|
||||||
|
return self._unicode_ranges
|
||||||
|
# list detected ranges
|
||||||
|
detected_ranges: list[str | None] = [unicode_range(char) for char in str(self)]
|
||||||
|
# filter and sort
|
||||||
|
self._unicode_ranges = sorted(list({r for r in detected_ranges if r}))
|
||||||
|
return self._unicode_ranges
|
||||||
|
|
||||||
|
@property
|
||||||
|
def could_be_from_charset(self) -> list[str]:
|
||||||
|
"""
|
||||||
|
The complete list of encoding that output the exact SAME str result and therefore could be the originating
|
||||||
|
encoding.
|
||||||
|
This list does include the encoding available in property 'encoding'.
|
||||||
|
"""
|
||||||
|
return [self._encoding] + [m.encoding for m in self._leaves]
|
||||||
|
|
||||||
|
def output(self, encoding: str = "utf_8") -> bytes:
|
||||||
|
"""
|
||||||
|
Method to get re-encoded bytes payload using given target encoding. Default to UTF-8.
|
||||||
|
Any errors will be simply ignored by the encoder NOT replaced.
|
||||||
|
"""
|
||||||
|
if self._output_encoding is None or self._output_encoding != encoding:
|
||||||
|
self._output_encoding = encoding
|
||||||
|
decoded_string = str(self)
|
||||||
|
if (
|
||||||
|
self._preemptive_declaration is not None
|
||||||
|
and self._preemptive_declaration.lower()
|
||||||
|
not in ["utf-8", "utf8", "utf_8"]
|
||||||
|
):
|
||||||
|
patched_header = sub(
|
||||||
|
RE_POSSIBLE_ENCODING_INDICATION,
|
||||||
|
lambda m: m.string[m.span()[0] : m.span()[1]].replace(
|
||||||
|
m.groups()[0],
|
||||||
|
iana_name(self._output_encoding).replace("_", "-"), # type: ignore[arg-type]
|
||||||
|
),
|
||||||
|
decoded_string[:8192],
|
||||||
|
count=1,
|
||||||
|
)
|
||||||
|
|
||||||
|
decoded_string = patched_header + decoded_string[8192:]
|
||||||
|
|
||||||
|
self._output_payload = decoded_string.encode(encoding, "replace")
|
||||||
|
|
||||||
|
return self._output_payload # type: ignore
|
||||||
|
|
||||||
|
@property
|
||||||
|
def fingerprint(self) -> str:
|
||||||
|
"""
|
||||||
|
Retrieve the unique SHA256 computed using the transformed (re-encoded) payload. Not the original one.
|
||||||
|
"""
|
||||||
|
return sha256(self.output()).hexdigest()
|
||||||
|
|
||||||
|
|
||||||
|
class CharsetMatches:
|
||||||
|
"""
|
||||||
|
Container with every CharsetMatch items ordered by default from most probable to the less one.
|
||||||
|
Act like a list(iterable) but does not implements all related methods.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, results: list[CharsetMatch] | None = None):
|
||||||
|
self._results: list[CharsetMatch] = sorted(results) if results else []
|
||||||
|
|
||||||
|
def __iter__(self) -> Iterator[CharsetMatch]:
|
||||||
|
yield from self._results
|
||||||
|
|
||||||
|
def __getitem__(self, item: int | str) -> CharsetMatch:
|
||||||
|
"""
|
||||||
|
Retrieve a single item either by its position or encoding name (alias may be used here).
|
||||||
|
Raise KeyError upon invalid index or encoding not present in results.
|
||||||
|
"""
|
||||||
|
if isinstance(item, int):
|
||||||
|
return self._results[item]
|
||||||
|
if isinstance(item, str):
|
||||||
|
item = iana_name(item, False)
|
||||||
|
for result in self._results:
|
||||||
|
if item in result.could_be_from_charset:
|
||||||
|
return result
|
||||||
|
raise KeyError
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
return len(self._results)
|
||||||
|
|
||||||
|
def __bool__(self) -> bool:
|
||||||
|
return len(self._results) > 0
|
||||||
|
|
||||||
|
def append(self, item: CharsetMatch) -> None:
|
||||||
|
"""
|
||||||
|
Insert a single match. Will be inserted accordingly to preserve sort.
|
||||||
|
Can be inserted as a submatch.
|
||||||
|
"""
|
||||||
|
if not isinstance(item, CharsetMatch):
|
||||||
|
raise ValueError(
|
||||||
|
"Cannot append instance '{}' to CharsetMatches".format(
|
||||||
|
str(item.__class__)
|
||||||
|
)
|
||||||
|
)
|
||||||
|
# We should disable the submatch factoring when the input file is too heavy (conserve RAM usage)
|
||||||
|
if len(item.raw) < TOO_BIG_SEQUENCE:
|
||||||
|
for match in self._results:
|
||||||
|
if match.fingerprint == item.fingerprint and match.chaos == item.chaos:
|
||||||
|
match.add_submatch(item)
|
||||||
|
return
|
||||||
|
self._results.append(item)
|
||||||
|
self._results = sorted(self._results)
|
||||||
|
|
||||||
|
def best(self) -> CharsetMatch | None:
|
||||||
|
"""
|
||||||
|
Simply return the first match. Strict equivalent to matches[0].
|
||||||
|
"""
|
||||||
|
if not self._results:
|
||||||
|
return None
|
||||||
|
return self._results[0]
|
||||||
|
|
||||||
|
def first(self) -> CharsetMatch | None:
|
||||||
|
"""
|
||||||
|
Redundant method, call the method best(). Kept for BC reasons.
|
||||||
|
"""
|
||||||
|
return self.best()
|
||||||
|
|
||||||
|
|
||||||
|
CoherenceMatch = Tuple[str, float]
|
||||||
|
CoherenceMatches = List[CoherenceMatch]
|
||||||
|
|
||||||
|
|
||||||
|
class CliDetectionResult:
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
path: str,
|
||||||
|
encoding: str | None,
|
||||||
|
encoding_aliases: list[str],
|
||||||
|
alternative_encodings: list[str],
|
||||||
|
language: str,
|
||||||
|
alphabets: list[str],
|
||||||
|
has_sig_or_bom: bool,
|
||||||
|
chaos: float,
|
||||||
|
coherence: float,
|
||||||
|
unicode_path: str | None,
|
||||||
|
is_preferred: bool,
|
||||||
|
):
|
||||||
|
self.path: str = path
|
||||||
|
self.unicode_path: str | None = unicode_path
|
||||||
|
self.encoding: str | None = encoding
|
||||||
|
self.encoding_aliases: list[str] = encoding_aliases
|
||||||
|
self.alternative_encodings: list[str] = alternative_encodings
|
||||||
|
self.language: str = language
|
||||||
|
self.alphabets: list[str] = alphabets
|
||||||
|
self.has_sig_or_bom: bool = has_sig_or_bom
|
||||||
|
self.chaos: float = chaos
|
||||||
|
self.coherence: float = coherence
|
||||||
|
self.is_preferred: bool = is_preferred
|
||||||
|
|
||||||
|
@property
|
||||||
|
def __dict__(self) -> dict[str, Any]: # type: ignore
|
||||||
|
return {
|
||||||
|
"path": self.path,
|
||||||
|
"encoding": self.encoding,
|
||||||
|
"encoding_aliases": self.encoding_aliases,
|
||||||
|
"alternative_encodings": self.alternative_encodings,
|
||||||
|
"language": self.language,
|
||||||
|
"alphabets": self.alphabets,
|
||||||
|
"has_sig_or_bom": self.has_sig_or_bom,
|
||||||
|
"chaos": self.chaos,
|
||||||
|
"coherence": self.coherence,
|
||||||
|
"unicode_path": self.unicode_path,
|
||||||
|
"is_preferred": self.is_preferred,
|
||||||
|
}
|
||||||
|
|
||||||
|
def to_json(self) -> str:
|
||||||
|
return dumps(self.__dict__, ensure_ascii=True, indent=4)
|
||||||
414
venv/lib/python3.12/site-packages/charset_normalizer/utils.py
Normal file
414
venv/lib/python3.12/site-packages/charset_normalizer/utils.py
Normal file
@@ -0,0 +1,414 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import importlib
|
||||||
|
import logging
|
||||||
|
import unicodedata
|
||||||
|
from codecs import IncrementalDecoder
|
||||||
|
from encodings.aliases import aliases
|
||||||
|
from functools import lru_cache
|
||||||
|
from re import findall
|
||||||
|
from typing import Generator
|
||||||
|
|
||||||
|
from _multibytecodec import ( # type: ignore[import-not-found,import]
|
||||||
|
MultibyteIncrementalDecoder,
|
||||||
|
)
|
||||||
|
|
||||||
|
from .constant import (
|
||||||
|
ENCODING_MARKS,
|
||||||
|
IANA_SUPPORTED_SIMILAR,
|
||||||
|
RE_POSSIBLE_ENCODING_INDICATION,
|
||||||
|
UNICODE_RANGES_COMBINED,
|
||||||
|
UNICODE_SECONDARY_RANGE_KEYWORD,
|
||||||
|
UTF8_MAXIMAL_ALLOCATION,
|
||||||
|
COMMON_CJK_CHARACTERS,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_accentuated(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
description: str = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
return (
|
||||||
|
"WITH GRAVE" in description
|
||||||
|
or "WITH ACUTE" in description
|
||||||
|
or "WITH CEDILLA" in description
|
||||||
|
or "WITH DIAERESIS" in description
|
||||||
|
or "WITH CIRCUMFLEX" in description
|
||||||
|
or "WITH TILDE" in description
|
||||||
|
or "WITH MACRON" in description
|
||||||
|
or "WITH RING ABOVE" in description
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def remove_accent(character: str) -> str:
|
||||||
|
decomposed: str = unicodedata.decomposition(character)
|
||||||
|
if not decomposed:
|
||||||
|
return character
|
||||||
|
|
||||||
|
codes: list[str] = decomposed.split(" ")
|
||||||
|
|
||||||
|
return chr(int(codes[0], 16))
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def unicode_range(character: str) -> str | None:
|
||||||
|
"""
|
||||||
|
Retrieve the Unicode range official name from a single character.
|
||||||
|
"""
|
||||||
|
character_ord: int = ord(character)
|
||||||
|
|
||||||
|
for range_name, ord_range in UNICODE_RANGES_COMBINED.items():
|
||||||
|
if character_ord in ord_range:
|
||||||
|
return range_name
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_latin(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
description: str = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
return "LATIN" in description
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_punctuation(character: str) -> bool:
|
||||||
|
character_category: str = unicodedata.category(character)
|
||||||
|
|
||||||
|
if "P" in character_category:
|
||||||
|
return True
|
||||||
|
|
||||||
|
character_range: str | None = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "Punctuation" in character_range
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_symbol(character: str) -> bool:
|
||||||
|
character_category: str = unicodedata.category(character)
|
||||||
|
|
||||||
|
if "S" in character_category or "N" in character_category:
|
||||||
|
return True
|
||||||
|
|
||||||
|
character_range: str | None = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "Forms" in character_range and character_category != "Lo"
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_emoticon(character: str) -> bool:
|
||||||
|
character_range: str | None = unicode_range(character)
|
||||||
|
|
||||||
|
if character_range is None:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "Emoticons" in character_range or "Pictographs" in character_range
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_separator(character: str) -> bool:
|
||||||
|
if character.isspace() or character in {"|", "+", "<", ">"}:
|
||||||
|
return True
|
||||||
|
|
||||||
|
character_category: str = unicodedata.category(character)
|
||||||
|
|
||||||
|
return "Z" in character_category or character_category in {"Po", "Pd", "Pc"}
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_case_variable(character: str) -> bool:
|
||||||
|
return character.islower() != character.isupper()
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_cjk(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "CJK" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_hiragana(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "HIRAGANA" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_katakana(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "KATAKANA" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_hangul(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "HANGUL" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_thai(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "THAI" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_arabic(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "ARABIC" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_arabic_isolated_form(character: str) -> bool:
|
||||||
|
try:
|
||||||
|
character_name = unicodedata.name(character)
|
||||||
|
except ValueError: # Defensive: unicode database outdated?
|
||||||
|
return False
|
||||||
|
|
||||||
|
return "ARABIC" in character_name and "ISOLATED FORM" in character_name
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_cjk_uncommon(character: str) -> bool:
|
||||||
|
return character not in COMMON_CJK_CHARACTERS
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=len(UNICODE_RANGES_COMBINED))
|
||||||
|
def is_unicode_range_secondary(range_name: str) -> bool:
|
||||||
|
return any(keyword in range_name for keyword in UNICODE_SECONDARY_RANGE_KEYWORD)
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=UTF8_MAXIMAL_ALLOCATION)
|
||||||
|
def is_unprintable(character: str) -> bool:
|
||||||
|
return (
|
||||||
|
character.isspace() is False # includes \n \t \r \v
|
||||||
|
and character.isprintable() is False
|
||||||
|
and character != "\x1a" # Why? Its the ASCII substitute character.
|
||||||
|
and character != "\ufeff" # bug discovered in Python,
|
||||||
|
# Zero Width No-Break Space located in Arabic Presentation Forms-B, Unicode 1.1 not acknowledged as space.
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def any_specified_encoding(sequence: bytes, search_zone: int = 8192) -> str | None:
|
||||||
|
"""
|
||||||
|
Extract using ASCII-only decoder any specified encoding in the first n-bytes.
|
||||||
|
"""
|
||||||
|
if not isinstance(sequence, bytes):
|
||||||
|
raise TypeError
|
||||||
|
|
||||||
|
seq_len: int = len(sequence)
|
||||||
|
|
||||||
|
results: list[str] = findall(
|
||||||
|
RE_POSSIBLE_ENCODING_INDICATION,
|
||||||
|
sequence[: min(seq_len, search_zone)].decode("ascii", errors="ignore"),
|
||||||
|
)
|
||||||
|
|
||||||
|
if len(results) == 0:
|
||||||
|
return None
|
||||||
|
|
||||||
|
for specified_encoding in results:
|
||||||
|
specified_encoding = specified_encoding.lower().replace("-", "_")
|
||||||
|
|
||||||
|
encoding_alias: str
|
||||||
|
encoding_iana: str
|
||||||
|
|
||||||
|
for encoding_alias, encoding_iana in aliases.items():
|
||||||
|
if encoding_alias == specified_encoding:
|
||||||
|
return encoding_iana
|
||||||
|
if encoding_iana == specified_encoding:
|
||||||
|
return encoding_iana
|
||||||
|
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
@lru_cache(maxsize=128)
|
||||||
|
def is_multi_byte_encoding(name: str) -> bool:
|
||||||
|
"""
|
||||||
|
Verify is a specific encoding is a multi byte one based on it IANA name
|
||||||
|
"""
|
||||||
|
return name in {
|
||||||
|
"utf_8",
|
||||||
|
"utf_8_sig",
|
||||||
|
"utf_16",
|
||||||
|
"utf_16_be",
|
||||||
|
"utf_16_le",
|
||||||
|
"utf_32",
|
||||||
|
"utf_32_le",
|
||||||
|
"utf_32_be",
|
||||||
|
"utf_7",
|
||||||
|
} or issubclass(
|
||||||
|
importlib.import_module(f"encodings.{name}").IncrementalDecoder,
|
||||||
|
MultibyteIncrementalDecoder,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def identify_sig_or_bom(sequence: bytes) -> tuple[str | None, bytes]:
|
||||||
|
"""
|
||||||
|
Identify and extract SIG/BOM in given sequence.
|
||||||
|
"""
|
||||||
|
|
||||||
|
for iana_encoding in ENCODING_MARKS:
|
||||||
|
marks: bytes | list[bytes] = ENCODING_MARKS[iana_encoding]
|
||||||
|
|
||||||
|
if isinstance(marks, bytes):
|
||||||
|
marks = [marks]
|
||||||
|
|
||||||
|
for mark in marks:
|
||||||
|
if sequence.startswith(mark):
|
||||||
|
return iana_encoding, mark
|
||||||
|
|
||||||
|
return None, b""
|
||||||
|
|
||||||
|
|
||||||
|
def should_strip_sig_or_bom(iana_encoding: str) -> bool:
|
||||||
|
return iana_encoding not in {"utf_16", "utf_32"}
|
||||||
|
|
||||||
|
|
||||||
|
def iana_name(cp_name: str, strict: bool = True) -> str:
|
||||||
|
"""Returns the Python normalized encoding name (Not the IANA official name)."""
|
||||||
|
cp_name = cp_name.lower().replace("-", "_")
|
||||||
|
|
||||||
|
encoding_alias: str
|
||||||
|
encoding_iana: str
|
||||||
|
|
||||||
|
for encoding_alias, encoding_iana in aliases.items():
|
||||||
|
if cp_name in [encoding_alias, encoding_iana]:
|
||||||
|
return encoding_iana
|
||||||
|
|
||||||
|
if strict:
|
||||||
|
raise ValueError(f"Unable to retrieve IANA for '{cp_name}'")
|
||||||
|
|
||||||
|
return cp_name
|
||||||
|
|
||||||
|
|
||||||
|
def cp_similarity(iana_name_a: str, iana_name_b: str) -> float:
|
||||||
|
if is_multi_byte_encoding(iana_name_a) or is_multi_byte_encoding(iana_name_b):
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
decoder_a = importlib.import_module(f"encodings.{iana_name_a}").IncrementalDecoder
|
||||||
|
decoder_b = importlib.import_module(f"encodings.{iana_name_b}").IncrementalDecoder
|
||||||
|
|
||||||
|
id_a: IncrementalDecoder = decoder_a(errors="ignore")
|
||||||
|
id_b: IncrementalDecoder = decoder_b(errors="ignore")
|
||||||
|
|
||||||
|
character_match_count: int = 0
|
||||||
|
|
||||||
|
for i in range(255):
|
||||||
|
to_be_decoded: bytes = bytes([i])
|
||||||
|
if id_a.decode(to_be_decoded) == id_b.decode(to_be_decoded):
|
||||||
|
character_match_count += 1
|
||||||
|
|
||||||
|
return character_match_count / 254
|
||||||
|
|
||||||
|
|
||||||
|
def is_cp_similar(iana_name_a: str, iana_name_b: str) -> bool:
|
||||||
|
"""
|
||||||
|
Determine if two code page are at least 80% similar. IANA_SUPPORTED_SIMILAR dict was generated using
|
||||||
|
the function cp_similarity.
|
||||||
|
"""
|
||||||
|
return (
|
||||||
|
iana_name_a in IANA_SUPPORTED_SIMILAR
|
||||||
|
and iana_name_b in IANA_SUPPORTED_SIMILAR[iana_name_a]
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def set_logging_handler(
|
||||||
|
name: str = "charset_normalizer",
|
||||||
|
level: int = logging.INFO,
|
||||||
|
format_string: str = "%(asctime)s | %(levelname)s | %(message)s",
|
||||||
|
) -> None:
|
||||||
|
logger = logging.getLogger(name)
|
||||||
|
logger.setLevel(level)
|
||||||
|
|
||||||
|
handler = logging.StreamHandler()
|
||||||
|
handler.setFormatter(logging.Formatter(format_string))
|
||||||
|
logger.addHandler(handler)
|
||||||
|
|
||||||
|
|
||||||
|
def cut_sequence_chunks(
|
||||||
|
sequences: bytes,
|
||||||
|
encoding_iana: str,
|
||||||
|
offsets: range,
|
||||||
|
chunk_size: int,
|
||||||
|
bom_or_sig_available: bool,
|
||||||
|
strip_sig_or_bom: bool,
|
||||||
|
sig_payload: bytes,
|
||||||
|
is_multi_byte_decoder: bool,
|
||||||
|
decoded_payload: str | None = None,
|
||||||
|
) -> Generator[str, None, None]:
|
||||||
|
if decoded_payload and is_multi_byte_decoder is False:
|
||||||
|
for i in offsets:
|
||||||
|
chunk = decoded_payload[i : i + chunk_size]
|
||||||
|
if not chunk:
|
||||||
|
break
|
||||||
|
yield chunk
|
||||||
|
else:
|
||||||
|
for i in offsets:
|
||||||
|
chunk_end = i + chunk_size
|
||||||
|
if chunk_end > len(sequences) + 8:
|
||||||
|
continue
|
||||||
|
|
||||||
|
cut_sequence = sequences[i : i + chunk_size]
|
||||||
|
|
||||||
|
if bom_or_sig_available and strip_sig_or_bom is False:
|
||||||
|
cut_sequence = sig_payload + cut_sequence
|
||||||
|
|
||||||
|
chunk = cut_sequence.decode(
|
||||||
|
encoding_iana,
|
||||||
|
errors="ignore" if is_multi_byte_decoder else "strict",
|
||||||
|
)
|
||||||
|
|
||||||
|
# multi-byte bad cutting detector and adjustment
|
||||||
|
# not the cleanest way to perform that fix but clever enough for now.
|
||||||
|
if is_multi_byte_decoder and i > 0:
|
||||||
|
chunk_partial_size_chk: int = min(chunk_size, 16)
|
||||||
|
|
||||||
|
if (
|
||||||
|
decoded_payload
|
||||||
|
and chunk[:chunk_partial_size_chk] not in decoded_payload
|
||||||
|
):
|
||||||
|
for j in range(i, i - 4, -1):
|
||||||
|
cut_sequence = sequences[j:chunk_end]
|
||||||
|
|
||||||
|
if bom_or_sig_available and strip_sig_or_bom is False:
|
||||||
|
cut_sequence = sig_payload + cut_sequence
|
||||||
|
|
||||||
|
chunk = cut_sequence.decode(encoding_iana, errors="ignore")
|
||||||
|
|
||||||
|
if chunk[:chunk_partial_size_chk] in decoded_payload:
|
||||||
|
break
|
||||||
|
|
||||||
|
yield chunk
|
||||||
@@ -0,0 +1,8 @@
|
|||||||
|
"""
|
||||||
|
Expose version
|
||||||
|
"""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
__version__ = "3.4.3"
|
||||||
|
VERSION = __version__.split(".")
|
||||||
@@ -0,0 +1 @@
|
|||||||
|
pip
|
||||||
@@ -0,0 +1,133 @@
|
|||||||
|
Metadata-Version: 2.4
|
||||||
|
Name: requests
|
||||||
|
Version: 2.32.5
|
||||||
|
Summary: Python HTTP for Humans.
|
||||||
|
Home-page: https://requests.readthedocs.io
|
||||||
|
Author: Kenneth Reitz
|
||||||
|
Author-email: me@kennethreitz.org
|
||||||
|
License: Apache-2.0
|
||||||
|
Project-URL: Documentation, https://requests.readthedocs.io
|
||||||
|
Project-URL: Source, https://github.com/psf/requests
|
||||||
|
Classifier: Development Status :: 5 - Production/Stable
|
||||||
|
Classifier: Environment :: Web Environment
|
||||||
|
Classifier: Intended Audience :: Developers
|
||||||
|
Classifier: License :: OSI Approved :: Apache Software License
|
||||||
|
Classifier: Natural Language :: English
|
||||||
|
Classifier: Operating System :: OS Independent
|
||||||
|
Classifier: Programming Language :: Python
|
||||||
|
Classifier: Programming Language :: Python :: 3
|
||||||
|
Classifier: Programming Language :: Python :: 3.9
|
||||||
|
Classifier: Programming Language :: Python :: 3.10
|
||||||
|
Classifier: Programming Language :: Python :: 3.11
|
||||||
|
Classifier: Programming Language :: Python :: 3.12
|
||||||
|
Classifier: Programming Language :: Python :: 3.13
|
||||||
|
Classifier: Programming Language :: Python :: 3.14
|
||||||
|
Classifier: Programming Language :: Python :: 3 :: Only
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: CPython
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
||||||
|
Classifier: Topic :: Internet :: WWW/HTTP
|
||||||
|
Classifier: Topic :: Software Development :: Libraries
|
||||||
|
Requires-Python: >=3.9
|
||||||
|
Description-Content-Type: text/markdown
|
||||||
|
License-File: LICENSE
|
||||||
|
Requires-Dist: charset_normalizer<4,>=2
|
||||||
|
Requires-Dist: idna<4,>=2.5
|
||||||
|
Requires-Dist: urllib3<3,>=1.21.1
|
||||||
|
Requires-Dist: certifi>=2017.4.17
|
||||||
|
Provides-Extra: security
|
||||||
|
Provides-Extra: socks
|
||||||
|
Requires-Dist: PySocks!=1.5.7,>=1.5.6; extra == "socks"
|
||||||
|
Provides-Extra: use-chardet-on-py3
|
||||||
|
Requires-Dist: chardet<6,>=3.0.2; extra == "use-chardet-on-py3"
|
||||||
|
Dynamic: author
|
||||||
|
Dynamic: author-email
|
||||||
|
Dynamic: classifier
|
||||||
|
Dynamic: description
|
||||||
|
Dynamic: description-content-type
|
||||||
|
Dynamic: home-page
|
||||||
|
Dynamic: license
|
||||||
|
Dynamic: license-file
|
||||||
|
Dynamic: project-url
|
||||||
|
Dynamic: provides-extra
|
||||||
|
Dynamic: requires-dist
|
||||||
|
Dynamic: requires-python
|
||||||
|
Dynamic: summary
|
||||||
|
|
||||||
|
# Requests
|
||||||
|
|
||||||
|
**Requests** is a simple, yet elegant, HTTP library.
|
||||||
|
|
||||||
|
```python
|
||||||
|
>>> import requests
|
||||||
|
>>> r = requests.get('https://httpbin.org/basic-auth/user/pass', auth=('user', 'pass'))
|
||||||
|
>>> r.status_code
|
||||||
|
200
|
||||||
|
>>> r.headers['content-type']
|
||||||
|
'application/json; charset=utf8'
|
||||||
|
>>> r.encoding
|
||||||
|
'utf-8'
|
||||||
|
>>> r.text
|
||||||
|
'{"authenticated": true, ...'
|
||||||
|
>>> r.json()
|
||||||
|
{'authenticated': True, ...}
|
||||||
|
```
|
||||||
|
|
||||||
|
Requests allows you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs, or to form-encode your `PUT` & `POST` data — but nowadays, just use the `json` method!
|
||||||
|
|
||||||
|
Requests is one of the most downloaded Python packages today, pulling in around `30M downloads / week`— according to GitHub, Requests is currently [depended upon](https://github.com/psf/requests/network/dependents?package_id=UGFja2FnZS01NzA4OTExNg%3D%3D) by `1,000,000+` repositories. You may certainly put your trust in this code.
|
||||||
|
|
||||||
|
[](https://pepy.tech/project/requests)
|
||||||
|
[](https://pypi.org/project/requests)
|
||||||
|
[](https://github.com/psf/requests/graphs/contributors)
|
||||||
|
|
||||||
|
## Installing Requests and Supported Versions
|
||||||
|
|
||||||
|
Requests is available on PyPI:
|
||||||
|
|
||||||
|
```console
|
||||||
|
$ python -m pip install requests
|
||||||
|
```
|
||||||
|
|
||||||
|
Requests officially supports Python 3.9+.
|
||||||
|
|
||||||
|
## Supported Features & Best–Practices
|
||||||
|
|
||||||
|
Requests is ready for the demands of building robust and reliable HTTP–speaking applications, for the needs of today.
|
||||||
|
|
||||||
|
- Keep-Alive & Connection Pooling
|
||||||
|
- International Domains and URLs
|
||||||
|
- Sessions with Cookie Persistence
|
||||||
|
- Browser-style TLS/SSL Verification
|
||||||
|
- Basic & Digest Authentication
|
||||||
|
- Familiar `dict`–like Cookies
|
||||||
|
- Automatic Content Decompression and Decoding
|
||||||
|
- Multi-part File Uploads
|
||||||
|
- SOCKS Proxy Support
|
||||||
|
- Connection Timeouts
|
||||||
|
- Streaming Downloads
|
||||||
|
- Automatic honoring of `.netrc`
|
||||||
|
- Chunked HTTP Requests
|
||||||
|
|
||||||
|
## API Reference and User Guide available on [Read the Docs](https://requests.readthedocs.io)
|
||||||
|
|
||||||
|
[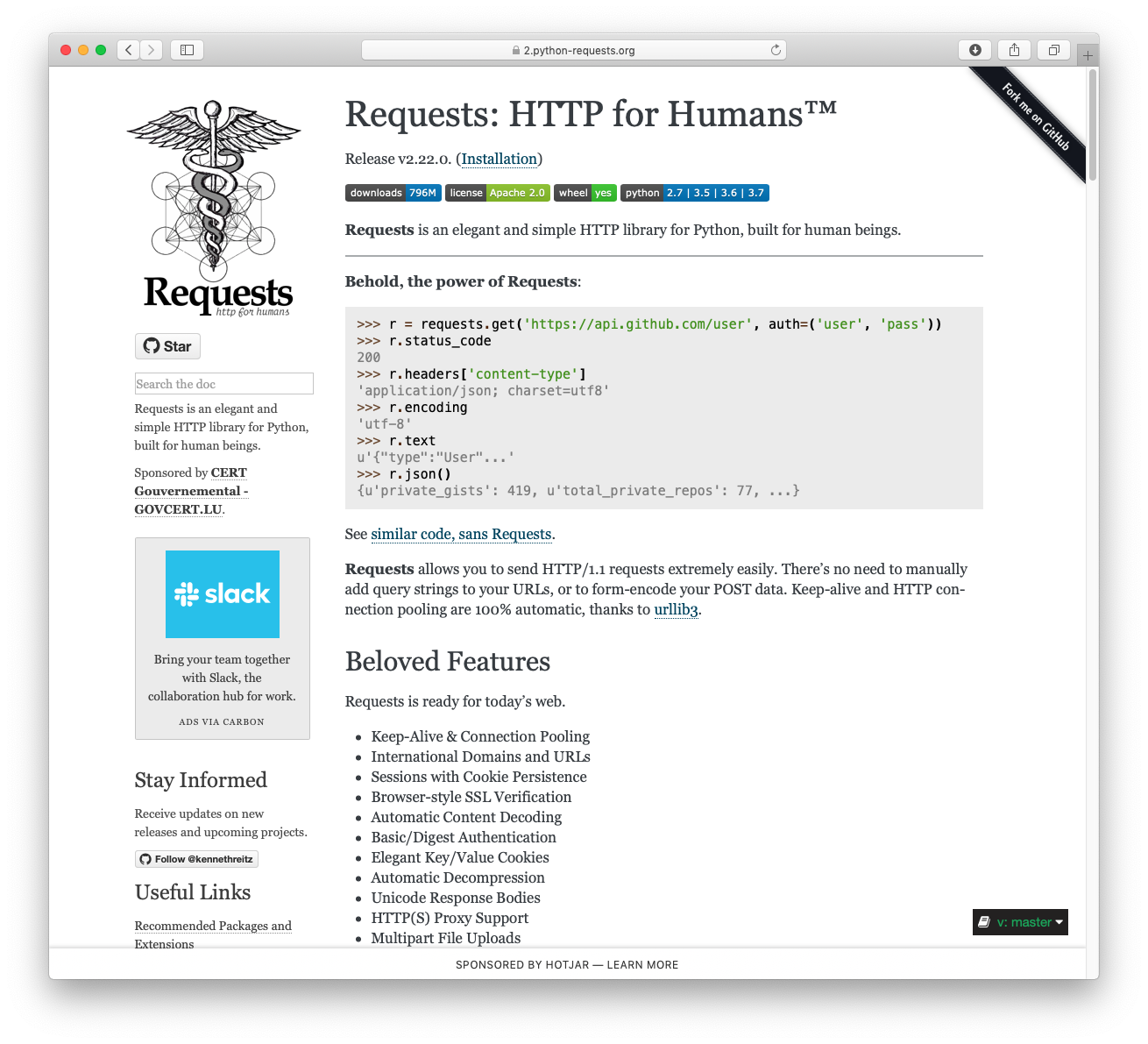](https://requests.readthedocs.io)
|
||||||
|
|
||||||
|
## Cloning the repository
|
||||||
|
|
||||||
|
When cloning the Requests repository, you may need to add the `-c
|
||||||
|
fetch.fsck.badTimezone=ignore` flag to avoid an error about a bad commit timestamp (see
|
||||||
|
[this issue](https://github.com/psf/requests/issues/2690) for more background):
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git clone -c fetch.fsck.badTimezone=ignore https://github.com/psf/requests.git
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also apply this setting to your global Git config:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git config --global fetch.fsck.badTimezone ignore
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
[](https://kennethreitz.org) [](https://www.python.org/psf)
|
||||||
@@ -0,0 +1,43 @@
|
|||||||
|
requests-2.32.5.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
||||||
|
requests-2.32.5.dist-info/METADATA,sha256=ZbWgjagfSRVRPnYJZf8Ut1GPZbe7Pv4NqzZLvMTUDLA,4945
|
||||||
|
requests-2.32.5.dist-info/RECORD,,
|
||||||
|
requests-2.32.5.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
||||||
|
requests-2.32.5.dist-info/WHEEL,sha256=_zCd3N1l69ArxyTb8rzEoP9TpbYXkqRFSNOD5OuxnTs,91
|
||||||
|
requests-2.32.5.dist-info/licenses/LICENSE,sha256=CeipvOyAZxBGUsFoaFqwkx54aPnIKEtm9a5u2uXxEws,10142
|
||||||
|
requests-2.32.5.dist-info/top_level.txt,sha256=fMSVmHfb5rbGOo6xv-O_tUX6j-WyixssE-SnwcDRxNQ,9
|
||||||
|
requests/__init__.py,sha256=4xaAERmPDIBPsa2PsjpU9r06yooK-2mZKHTZAhWRWts,5072
|
||||||
|
requests/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/__version__.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/_internal_utils.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/adapters.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/api.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/auth.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/certs.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/compat.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/cookies.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/exceptions.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/help.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/hooks.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/models.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/packages.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/sessions.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/status_codes.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/structures.cpython-312.pyc,,
|
||||||
|
requests/__pycache__/utils.cpython-312.pyc,,
|
||||||
|
requests/__version__.py,sha256=QKDceK8K_ujqwDDc3oYrR0odOBYgKVOQQ5vFap_G_cg,435
|
||||||
|
requests/_internal_utils.py,sha256=nMQymr4hs32TqVo5AbCrmcJEhvPUh7xXlluyqwslLiQ,1495
|
||||||
|
requests/adapters.py,sha256=8nX113gbb123aUtx2ETkAN_6IsYX-M2fRoLGluTEcRk,26285
|
||||||
|
requests/api.py,sha256=_Zb9Oa7tzVIizTKwFrPjDEY9ejtm_OnSRERnADxGsQs,6449
|
||||||
|
requests/auth.py,sha256=kF75tqnLctZ9Mf_hm9TZIj4cQWnN5uxRz8oWsx5wmR0,10186
|
||||||
|
requests/certs.py,sha256=Z9Sb410Anv6jUFTyss0jFFhU6xst8ctELqfy8Ev23gw,429
|
||||||
|
requests/compat.py,sha256=J7sIjR6XoDGp5JTVzOxkK5fSoUVUa_Pjc7iRZhAWGmI,2142
|
||||||
|
requests/cookies.py,sha256=bNi-iqEj4NPZ00-ob-rHvzkvObzN3lEpgw3g6paS3Xw,18590
|
||||||
|
requests/exceptions.py,sha256=jJPS1UWATs86ShVUaLorTiJb1SaGuoNEWgICJep-VkY,4260
|
||||||
|
requests/help.py,sha256=gPX5d_H7Xd88aDABejhqGgl9B1VFRTt5BmiYvL3PzIQ,3875
|
||||||
|
requests/hooks.py,sha256=CiuysiHA39V5UfcCBXFIx83IrDpuwfN9RcTUgv28ftQ,733
|
||||||
|
requests/models.py,sha256=MjZdZ4k7tnw-1nz5PKShjmPmqyk0L6DciwnFngb_Vk4,35510
|
||||||
|
requests/packages.py,sha256=_g0gZ681UyAlKHRjH6kanbaoxx2eAb6qzcXiODyTIoc,904
|
||||||
|
requests/sessions.py,sha256=Cl1dpEnOfwrzzPbku-emepNeN4Rt_0_58Iy2x-JGTm8,30503
|
||||||
|
requests/status_codes.py,sha256=iJUAeA25baTdw-6PfD0eF4qhpINDJRJI-yaMqxs4LEI,4322
|
||||||
|
requests/structures.py,sha256=-IbmhVz06S-5aPSZuUthZ6-6D9XOjRuTXHOabY041XM,2912
|
||||||
|
requests/utils.py,sha256=WqU86rZ3wvhC-tQjWcjtH_HEKZwWB3iWCZV6SW5DEdQ,33213
|
||||||
@@ -0,0 +1,5 @@
|
|||||||
|
Wheel-Version: 1.0
|
||||||
|
Generator: setuptools (80.9.0)
|
||||||
|
Root-Is-Purelib: true
|
||||||
|
Tag: py3-none-any
|
||||||
|
|
||||||
@@ -0,0 +1,175 @@
|
|||||||
|
|
||||||
|
Apache License
|
||||||
|
Version 2.0, January 2004
|
||||||
|
http://www.apache.org/licenses/
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||||
|
|
||||||
|
1. Definitions.
|
||||||
|
|
||||||
|
"License" shall mean the terms and conditions for use, reproduction,
|
||||||
|
and distribution as defined by Sections 1 through 9 of this document.
|
||||||
|
|
||||||
|
"Licensor" shall mean the copyright owner or entity authorized by
|
||||||
|
the copyright owner that is granting the License.
|
||||||
|
|
||||||
|
"Legal Entity" shall mean the union of the acting entity and all
|
||||||
|
other entities that control, are controlled by, or are under common
|
||||||
|
control with that entity. For the purposes of this definition,
|
||||||
|
"control" means (i) the power, direct or indirect, to cause the
|
||||||
|
direction or management of such entity, whether by contract or
|
||||||
|
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||||
|
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||||
|
|
||||||
|
"You" (or "Your") shall mean an individual or Legal Entity
|
||||||
|
exercising permissions granted by this License.
|
||||||
|
|
||||||
|
"Source" form shall mean the preferred form for making modifications,
|
||||||
|
including but not limited to software source code, documentation
|
||||||
|
source, and configuration files.
|
||||||
|
|
||||||
|
"Object" form shall mean any form resulting from mechanical
|
||||||
|
transformation or translation of a Source form, including but
|
||||||
|
not limited to compiled object code, generated documentation,
|
||||||
|
and conversions to other media types.
|
||||||
|
|
||||||
|
"Work" shall mean the work of authorship, whether in Source or
|
||||||
|
Object form, made available under the License, as indicated by a
|
||||||
|
copyright notice that is included in or attached to the work
|
||||||
|
(an example is provided in the Appendix below).
|
||||||
|
|
||||||
|
"Derivative Works" shall mean any work, whether in Source or Object
|
||||||
|
form, that is based on (or derived from) the Work and for which the
|
||||||
|
editorial revisions, annotations, elaborations, or other modifications
|
||||||
|
represent, as a whole, an original work of authorship. For the purposes
|
||||||
|
of this License, Derivative Works shall not include works that remain
|
||||||
|
separable from, or merely link (or bind by name) to the interfaces of,
|
||||||
|
the Work and Derivative Works thereof.
|
||||||
|
|
||||||
|
"Contribution" shall mean any work of authorship, including
|
||||||
|
the original version of the Work and any modifications or additions
|
||||||
|
to that Work or Derivative Works thereof, that is intentionally
|
||||||
|
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||||
|
or by an individual or Legal Entity authorized to submit on behalf of
|
||||||
|
the copyright owner. For the purposes of this definition, "submitted"
|
||||||
|
means any form of electronic, verbal, or written communication sent
|
||||||
|
to the Licensor or its representatives, including but not limited to
|
||||||
|
communication on electronic mailing lists, source code control systems,
|
||||||
|
and issue tracking systems that are managed by, or on behalf of, the
|
||||||
|
Licensor for the purpose of discussing and improving the Work, but
|
||||||
|
excluding communication that is conspicuously marked or otherwise
|
||||||
|
designated in writing by the copyright owner as "Not a Contribution."
|
||||||
|
|
||||||
|
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||||
|
on behalf of whom a Contribution has been received by Licensor and
|
||||||
|
subsequently incorporated within the Work.
|
||||||
|
|
||||||
|
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
copyright license to reproduce, prepare Derivative Works of,
|
||||||
|
publicly display, publicly perform, sublicense, and distribute the
|
||||||
|
Work and such Derivative Works in Source or Object form.
|
||||||
|
|
||||||
|
3. Grant of Patent License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
(except as stated in this section) patent license to make, have made,
|
||||||
|
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||||
|
where such license applies only to those patent claims licensable
|
||||||
|
by such Contributor that are necessarily infringed by their
|
||||||
|
Contribution(s) alone or by combination of their Contribution(s)
|
||||||
|
with the Work to which such Contribution(s) was submitted. If You
|
||||||
|
institute patent litigation against any entity (including a
|
||||||
|
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||||
|
or a Contribution incorporated within the Work constitutes direct
|
||||||
|
or contributory patent infringement, then any patent licenses
|
||||||
|
granted to You under this License for that Work shall terminate
|
||||||
|
as of the date such litigation is filed.
|
||||||
|
|
||||||
|
4. Redistribution. You may reproduce and distribute copies of the
|
||||||
|
Work or Derivative Works thereof in any medium, with or without
|
||||||
|
modifications, and in Source or Object form, provided that You
|
||||||
|
meet the following conditions:
|
||||||
|
|
||||||
|
(a) You must give any other recipients of the Work or
|
||||||
|
Derivative Works a copy of this License; and
|
||||||
|
|
||||||
|
(b) You must cause any modified files to carry prominent notices
|
||||||
|
stating that You changed the files; and
|
||||||
|
|
||||||
|
(c) You must retain, in the Source form of any Derivative Works
|
||||||
|
that You distribute, all copyright, patent, trademark, and
|
||||||
|
attribution notices from the Source form of the Work,
|
||||||
|
excluding those notices that do not pertain to any part of
|
||||||
|
the Derivative Works; and
|
||||||
|
|
||||||
|
(d) If the Work includes a "NOTICE" text file as part of its
|
||||||
|
distribution, then any Derivative Works that You distribute must
|
||||||
|
include a readable copy of the attribution notices contained
|
||||||
|
within such NOTICE file, excluding those notices that do not
|
||||||
|
pertain to any part of the Derivative Works, in at least one
|
||||||
|
of the following places: within a NOTICE text file distributed
|
||||||
|
as part of the Derivative Works; within the Source form or
|
||||||
|
documentation, if provided along with the Derivative Works; or,
|
||||||
|
within a display generated by the Derivative Works, if and
|
||||||
|
wherever such third-party notices normally appear. The contents
|
||||||
|
of the NOTICE file are for informational purposes only and
|
||||||
|
do not modify the License. You may add Your own attribution
|
||||||
|
notices within Derivative Works that You distribute, alongside
|
||||||
|
or as an addendum to the NOTICE text from the Work, provided
|
||||||
|
that such additional attribution notices cannot be construed
|
||||||
|
as modifying the License.
|
||||||
|
|
||||||
|
You may add Your own copyright statement to Your modifications and
|
||||||
|
may provide additional or different license terms and conditions
|
||||||
|
for use, reproduction, or distribution of Your modifications, or
|
||||||
|
for any such Derivative Works as a whole, provided Your use,
|
||||||
|
reproduction, and distribution of the Work otherwise complies with
|
||||||
|
the conditions stated in this License.
|
||||||
|
|
||||||
|
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||||
|
any Contribution intentionally submitted for inclusion in the Work
|
||||||
|
by You to the Licensor shall be under the terms and conditions of
|
||||||
|
this License, without any additional terms or conditions.
|
||||||
|
Notwithstanding the above, nothing herein shall supersede or modify
|
||||||
|
the terms of any separate license agreement you may have executed
|
||||||
|
with Licensor regarding such Contributions.
|
||||||
|
|
||||||
|
6. Trademarks. This License does not grant permission to use the trade
|
||||||
|
names, trademarks, service marks, or product names of the Licensor,
|
||||||
|
except as required for reasonable and customary use in describing the
|
||||||
|
origin of the Work and reproducing the content of the NOTICE file.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||||
|
agreed to in writing, Licensor provides the Work (and each
|
||||||
|
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||||
|
implied, including, without limitation, any warranties or conditions
|
||||||
|
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||||
|
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||||
|
appropriateness of using or redistributing the Work and assume any
|
||||||
|
risks associated with Your exercise of permissions under this License.
|
||||||
|
|
||||||
|
8. Limitation of Liability. In no event and under no legal theory,
|
||||||
|
whether in tort (including negligence), contract, or otherwise,
|
||||||
|
unless required by applicable law (such as deliberate and grossly
|
||||||
|
negligent acts) or agreed to in writing, shall any Contributor be
|
||||||
|
liable to You for damages, including any direct, indirect, special,
|
||||||
|
incidental, or consequential damages of any character arising as a
|
||||||
|
result of this License or out of the use or inability to use the
|
||||||
|
Work (including but not limited to damages for loss of goodwill,
|
||||||
|
work stoppage, computer failure or malfunction, or any and all
|
||||||
|
other commercial damages or losses), even if such Contributor
|
||||||
|
has been advised of the possibility of such damages.
|
||||||
|
|
||||||
|
9. Accepting Warranty or Additional Liability. While redistributing
|
||||||
|
the Work or Derivative Works thereof, You may choose to offer,
|
||||||
|
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||||
|
or other liability obligations and/or rights consistent with this
|
||||||
|
License. However, in accepting such obligations, You may act only
|
||||||
|
on Your own behalf and on Your sole responsibility, not on behalf
|
||||||
|
of any other Contributor, and only if You agree to indemnify,
|
||||||
|
defend, and hold each Contributor harmless for any liability
|
||||||
|
incurred by, or claims asserted against, such Contributor by reason
|
||||||
|
of your accepting any such warranty or additional liability.
|
||||||
@@ -0,0 +1 @@
|
|||||||
|
requests
|
||||||
184
venv/lib/python3.12/site-packages/requests/__init__.py
Normal file
184
venv/lib/python3.12/site-packages/requests/__init__.py
Normal file
@@ -0,0 +1,184 @@
|
|||||||
|
# __
|
||||||
|
# /__) _ _ _ _ _/ _
|
||||||
|
# / ( (- (/ (/ (- _) / _)
|
||||||
|
# /
|
||||||
|
|
||||||
|
"""
|
||||||
|
Requests HTTP Library
|
||||||
|
~~~~~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
Requests is an HTTP library, written in Python, for human beings.
|
||||||
|
Basic GET usage:
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> r = requests.get('https://www.python.org')
|
||||||
|
>>> r.status_code
|
||||||
|
200
|
||||||
|
>>> b'Python is a programming language' in r.content
|
||||||
|
True
|
||||||
|
|
||||||
|
... or POST:
|
||||||
|
|
||||||
|
>>> payload = dict(key1='value1', key2='value2')
|
||||||
|
>>> r = requests.post('https://httpbin.org/post', data=payload)
|
||||||
|
>>> print(r.text)
|
||||||
|
{
|
||||||
|
...
|
||||||
|
"form": {
|
||||||
|
"key1": "value1",
|
||||||
|
"key2": "value2"
|
||||||
|
},
|
||||||
|
...
|
||||||
|
}
|
||||||
|
|
||||||
|
The other HTTP methods are supported - see `requests.api`. Full documentation
|
||||||
|
is at <https://requests.readthedocs.io>.
|
||||||
|
|
||||||
|
:copyright: (c) 2017 by Kenneth Reitz.
|
||||||
|
:license: Apache 2.0, see LICENSE for more details.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
from .exceptions import RequestsDependencyWarning
|
||||||
|
|
||||||
|
try:
|
||||||
|
from charset_normalizer import __version__ as charset_normalizer_version
|
||||||
|
except ImportError:
|
||||||
|
charset_normalizer_version = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
from chardet import __version__ as chardet_version
|
||||||
|
except ImportError:
|
||||||
|
chardet_version = None
|
||||||
|
|
||||||
|
|
||||||
|
def check_compatibility(urllib3_version, chardet_version, charset_normalizer_version):
|
||||||
|
urllib3_version = urllib3_version.split(".")
|
||||||
|
assert urllib3_version != ["dev"] # Verify urllib3 isn't installed from git.
|
||||||
|
|
||||||
|
# Sometimes, urllib3 only reports its version as 16.1.
|
||||||
|
if len(urllib3_version) == 2:
|
||||||
|
urllib3_version.append("0")
|
||||||
|
|
||||||
|
# Check urllib3 for compatibility.
|
||||||
|
major, minor, patch = urllib3_version # noqa: F811
|
||||||
|
major, minor, patch = int(major), int(minor), int(patch)
|
||||||
|
# urllib3 >= 1.21.1
|
||||||
|
assert major >= 1
|
||||||
|
if major == 1:
|
||||||
|
assert minor >= 21
|
||||||
|
|
||||||
|
# Check charset_normalizer for compatibility.
|
||||||
|
if chardet_version:
|
||||||
|
major, minor, patch = chardet_version.split(".")[:3]
|
||||||
|
major, minor, patch = int(major), int(minor), int(patch)
|
||||||
|
# chardet_version >= 3.0.2, < 6.0.0
|
||||||
|
assert (3, 0, 2) <= (major, minor, patch) < (6, 0, 0)
|
||||||
|
elif charset_normalizer_version:
|
||||||
|
major, minor, patch = charset_normalizer_version.split(".")[:3]
|
||||||
|
major, minor, patch = int(major), int(minor), int(patch)
|
||||||
|
# charset_normalizer >= 2.0.0 < 4.0.0
|
||||||
|
assert (2, 0, 0) <= (major, minor, patch) < (4, 0, 0)
|
||||||
|
else:
|
||||||
|
warnings.warn(
|
||||||
|
"Unable to find acceptable character detection dependency "
|
||||||
|
"(chardet or charset_normalizer).",
|
||||||
|
RequestsDependencyWarning,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def _check_cryptography(cryptography_version):
|
||||||
|
# cryptography < 1.3.4
|
||||||
|
try:
|
||||||
|
cryptography_version = list(map(int, cryptography_version.split(".")))
|
||||||
|
except ValueError:
|
||||||
|
return
|
||||||
|
|
||||||
|
if cryptography_version < [1, 3, 4]:
|
||||||
|
warning = "Old version of cryptography ({}) may cause slowdown.".format(
|
||||||
|
cryptography_version
|
||||||
|
)
|
||||||
|
warnings.warn(warning, RequestsDependencyWarning)
|
||||||
|
|
||||||
|
|
||||||
|
# Check imported dependencies for compatibility.
|
||||||
|
try:
|
||||||
|
check_compatibility(
|
||||||
|
urllib3.__version__, chardet_version, charset_normalizer_version
|
||||||
|
)
|
||||||
|
except (AssertionError, ValueError):
|
||||||
|
warnings.warn(
|
||||||
|
"urllib3 ({}) or chardet ({})/charset_normalizer ({}) doesn't match a supported "
|
||||||
|
"version!".format(
|
||||||
|
urllib3.__version__, chardet_version, charset_normalizer_version
|
||||||
|
),
|
||||||
|
RequestsDependencyWarning,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Attempt to enable urllib3's fallback for SNI support
|
||||||
|
# if the standard library doesn't support SNI or the
|
||||||
|
# 'ssl' library isn't available.
|
||||||
|
try:
|
||||||
|
try:
|
||||||
|
import ssl
|
||||||
|
except ImportError:
|
||||||
|
ssl = None
|
||||||
|
|
||||||
|
if not getattr(ssl, "HAS_SNI", False):
|
||||||
|
from urllib3.contrib import pyopenssl
|
||||||
|
|
||||||
|
pyopenssl.inject_into_urllib3()
|
||||||
|
|
||||||
|
# Check cryptography version
|
||||||
|
from cryptography import __version__ as cryptography_version
|
||||||
|
|
||||||
|
_check_cryptography(cryptography_version)
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# urllib3's DependencyWarnings should be silenced.
|
||||||
|
from urllib3.exceptions import DependencyWarning
|
||||||
|
|
||||||
|
warnings.simplefilter("ignore", DependencyWarning)
|
||||||
|
|
||||||
|
# Set default logging handler to avoid "No handler found" warnings.
|
||||||
|
import logging
|
||||||
|
from logging import NullHandler
|
||||||
|
|
||||||
|
from . import packages, utils
|
||||||
|
from .__version__ import (
|
||||||
|
__author__,
|
||||||
|
__author_email__,
|
||||||
|
__build__,
|
||||||
|
__cake__,
|
||||||
|
__copyright__,
|
||||||
|
__description__,
|
||||||
|
__license__,
|
||||||
|
__title__,
|
||||||
|
__url__,
|
||||||
|
__version__,
|
||||||
|
)
|
||||||
|
from .api import delete, get, head, options, patch, post, put, request
|
||||||
|
from .exceptions import (
|
||||||
|
ConnectionError,
|
||||||
|
ConnectTimeout,
|
||||||
|
FileModeWarning,
|
||||||
|
HTTPError,
|
||||||
|
JSONDecodeError,
|
||||||
|
ReadTimeout,
|
||||||
|
RequestException,
|
||||||
|
Timeout,
|
||||||
|
TooManyRedirects,
|
||||||
|
URLRequired,
|
||||||
|
)
|
||||||
|
from .models import PreparedRequest, Request, Response
|
||||||
|
from .sessions import Session, session
|
||||||
|
from .status_codes import codes
|
||||||
|
|
||||||
|
logging.getLogger(__name__).addHandler(NullHandler())
|
||||||
|
|
||||||
|
# FileModeWarnings go off per the default.
|
||||||
|
warnings.simplefilter("default", FileModeWarning, append=True)
|
||||||
14
venv/lib/python3.12/site-packages/requests/__version__.py
Normal file
14
venv/lib/python3.12/site-packages/requests/__version__.py
Normal file
@@ -0,0 +1,14 @@
|
|||||||
|
# .-. .-. .-. . . .-. .-. .-. .-.
|
||||||
|
# |( |- |.| | | |- `-. | `-.
|
||||||
|
# ' ' `-' `-`.`-' `-' `-' ' `-'
|
||||||
|
|
||||||
|
__title__ = "requests"
|
||||||
|
__description__ = "Python HTTP for Humans."
|
||||||
|
__url__ = "https://requests.readthedocs.io"
|
||||||
|
__version__ = "2.32.5"
|
||||||
|
__build__ = 0x023205
|
||||||
|
__author__ = "Kenneth Reitz"
|
||||||
|
__author_email__ = "me@kennethreitz.org"
|
||||||
|
__license__ = "Apache-2.0"
|
||||||
|
__copyright__ = "Copyright Kenneth Reitz"
|
||||||
|
__cake__ = "\u2728 \U0001f370 \u2728"
|
||||||
@@ -0,0 +1,50 @@
|
|||||||
|
"""
|
||||||
|
requests._internal_utils
|
||||||
|
~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
Provides utility functions that are consumed internally by Requests
|
||||||
|
which depend on extremely few external helpers (such as compat)
|
||||||
|
"""
|
||||||
|
import re
|
||||||
|
|
||||||
|
from .compat import builtin_str
|
||||||
|
|
||||||
|
_VALID_HEADER_NAME_RE_BYTE = re.compile(rb"^[^:\s][^:\r\n]*$")
|
||||||
|
_VALID_HEADER_NAME_RE_STR = re.compile(r"^[^:\s][^:\r\n]*$")
|
||||||
|
_VALID_HEADER_VALUE_RE_BYTE = re.compile(rb"^\S[^\r\n]*$|^$")
|
||||||
|
_VALID_HEADER_VALUE_RE_STR = re.compile(r"^\S[^\r\n]*$|^$")
|
||||||
|
|
||||||
|
_HEADER_VALIDATORS_STR = (_VALID_HEADER_NAME_RE_STR, _VALID_HEADER_VALUE_RE_STR)
|
||||||
|
_HEADER_VALIDATORS_BYTE = (_VALID_HEADER_NAME_RE_BYTE, _VALID_HEADER_VALUE_RE_BYTE)
|
||||||
|
HEADER_VALIDATORS = {
|
||||||
|
bytes: _HEADER_VALIDATORS_BYTE,
|
||||||
|
str: _HEADER_VALIDATORS_STR,
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def to_native_string(string, encoding="ascii"):
|
||||||
|
"""Given a string object, regardless of type, returns a representation of
|
||||||
|
that string in the native string type, encoding and decoding where
|
||||||
|
necessary. This assumes ASCII unless told otherwise.
|
||||||
|
"""
|
||||||
|
if isinstance(string, builtin_str):
|
||||||
|
out = string
|
||||||
|
else:
|
||||||
|
out = string.decode(encoding)
|
||||||
|
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
def unicode_is_ascii(u_string):
|
||||||
|
"""Determine if unicode string only contains ASCII characters.
|
||||||
|
|
||||||
|
:param str u_string: unicode string to check. Must be unicode
|
||||||
|
and not Python 2 `str`.
|
||||||
|
:rtype: bool
|
||||||
|
"""
|
||||||
|
assert isinstance(u_string, str)
|
||||||
|
try:
|
||||||
|
u_string.encode("ascii")
|
||||||
|
return True
|
||||||
|
except UnicodeEncodeError:
|
||||||
|
return False
|
||||||
696
venv/lib/python3.12/site-packages/requests/adapters.py
Normal file
696
venv/lib/python3.12/site-packages/requests/adapters.py
Normal file
@@ -0,0 +1,696 @@
|
|||||||
|
"""
|
||||||
|
requests.adapters
|
||||||
|
~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module contains the transport adapters that Requests uses to define
|
||||||
|
and maintain connections.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import os.path
|
||||||
|
import socket # noqa: F401
|
||||||
|
import typing
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
from urllib3.exceptions import ClosedPoolError, ConnectTimeoutError
|
||||||
|
from urllib3.exceptions import HTTPError as _HTTPError
|
||||||
|
from urllib3.exceptions import InvalidHeader as _InvalidHeader
|
||||||
|
from urllib3.exceptions import (
|
||||||
|
LocationValueError,
|
||||||
|
MaxRetryError,
|
||||||
|
NewConnectionError,
|
||||||
|
ProtocolError,
|
||||||
|
)
|
||||||
|
from urllib3.exceptions import ProxyError as _ProxyError
|
||||||
|
from urllib3.exceptions import ReadTimeoutError, ResponseError
|
||||||
|
from urllib3.exceptions import SSLError as _SSLError
|
||||||
|
from urllib3.poolmanager import PoolManager, proxy_from_url
|
||||||
|
from urllib3.util import Timeout as TimeoutSauce
|
||||||
|
from urllib3.util import parse_url
|
||||||
|
from urllib3.util.retry import Retry
|
||||||
|
|
||||||
|
from .auth import _basic_auth_str
|
||||||
|
from .compat import basestring, urlparse
|
||||||
|
from .cookies import extract_cookies_to_jar
|
||||||
|
from .exceptions import (
|
||||||
|
ConnectionError,
|
||||||
|
ConnectTimeout,
|
||||||
|
InvalidHeader,
|
||||||
|
InvalidProxyURL,
|
||||||
|
InvalidSchema,
|
||||||
|
InvalidURL,
|
||||||
|
ProxyError,
|
||||||
|
ReadTimeout,
|
||||||
|
RetryError,
|
||||||
|
SSLError,
|
||||||
|
)
|
||||||
|
from .models import Response
|
||||||
|
from .structures import CaseInsensitiveDict
|
||||||
|
from .utils import (
|
||||||
|
DEFAULT_CA_BUNDLE_PATH,
|
||||||
|
extract_zipped_paths,
|
||||||
|
get_auth_from_url,
|
||||||
|
get_encoding_from_headers,
|
||||||
|
prepend_scheme_if_needed,
|
||||||
|
select_proxy,
|
||||||
|
urldefragauth,
|
||||||
|
)
|
||||||
|
|
||||||
|
try:
|
||||||
|
from urllib3.contrib.socks import SOCKSProxyManager
|
||||||
|
except ImportError:
|
||||||
|
|
||||||
|
def SOCKSProxyManager(*args, **kwargs):
|
||||||
|
raise InvalidSchema("Missing dependencies for SOCKS support.")
|
||||||
|
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from .models import PreparedRequest
|
||||||
|
|
||||||
|
|
||||||
|
DEFAULT_POOLBLOCK = False
|
||||||
|
DEFAULT_POOLSIZE = 10
|
||||||
|
DEFAULT_RETRIES = 0
|
||||||
|
DEFAULT_POOL_TIMEOUT = None
|
||||||
|
|
||||||
|
|
||||||
|
def _urllib3_request_context(
|
||||||
|
request: "PreparedRequest",
|
||||||
|
verify: "bool | str | None",
|
||||||
|
client_cert: "typing.Tuple[str, str] | str | None",
|
||||||
|
poolmanager: "PoolManager",
|
||||||
|
) -> "(typing.Dict[str, typing.Any], typing.Dict[str, typing.Any])":
|
||||||
|
host_params = {}
|
||||||
|
pool_kwargs = {}
|
||||||
|
parsed_request_url = urlparse(request.url)
|
||||||
|
scheme = parsed_request_url.scheme.lower()
|
||||||
|
port = parsed_request_url.port
|
||||||
|
|
||||||
|
cert_reqs = "CERT_REQUIRED"
|
||||||
|
if verify is False:
|
||||||
|
cert_reqs = "CERT_NONE"
|
||||||
|
elif isinstance(verify, str):
|
||||||
|
if not os.path.isdir(verify):
|
||||||
|
pool_kwargs["ca_certs"] = verify
|
||||||
|
else:
|
||||||
|
pool_kwargs["ca_cert_dir"] = verify
|
||||||
|
pool_kwargs["cert_reqs"] = cert_reqs
|
||||||
|
if client_cert is not None:
|
||||||
|
if isinstance(client_cert, tuple) and len(client_cert) == 2:
|
||||||
|
pool_kwargs["cert_file"] = client_cert[0]
|
||||||
|
pool_kwargs["key_file"] = client_cert[1]
|
||||||
|
else:
|
||||||
|
# According to our docs, we allow users to specify just the client
|
||||||
|
# cert path
|
||||||
|
pool_kwargs["cert_file"] = client_cert
|
||||||
|
host_params = {
|
||||||
|
"scheme": scheme,
|
||||||
|
"host": parsed_request_url.hostname,
|
||||||
|
"port": port,
|
||||||
|
}
|
||||||
|
return host_params, pool_kwargs
|
||||||
|
|
||||||
|
|
||||||
|
class BaseAdapter:
|
||||||
|
"""The Base Transport Adapter"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
def send(
|
||||||
|
self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None
|
||||||
|
):
|
||||||
|
"""Sends PreparedRequest object. Returns Response object.
|
||||||
|
|
||||||
|
:param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
|
||||||
|
:param stream: (optional) Whether to stream the request content.
|
||||||
|
:param timeout: (optional) How long to wait for the server to send
|
||||||
|
data before giving up, as a float, or a :ref:`(connect timeout,
|
||||||
|
read timeout) <timeouts>` tuple.
|
||||||
|
:type timeout: float or tuple
|
||||||
|
:param verify: (optional) Either a boolean, in which case it controls whether we verify
|
||||||
|
the server's TLS certificate, or a string, in which case it must be a path
|
||||||
|
to a CA bundle to use
|
||||||
|
:param cert: (optional) Any user-provided SSL certificate to be trusted.
|
||||||
|
:param proxies: (optional) The proxies dictionary to apply to the request.
|
||||||
|
"""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
"""Cleans up adapter specific items."""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPAdapter(BaseAdapter):
|
||||||
|
"""The built-in HTTP Adapter for urllib3.
|
||||||
|
|
||||||
|
Provides a general-case interface for Requests sessions to contact HTTP and
|
||||||
|
HTTPS urls by implementing the Transport Adapter interface. This class will
|
||||||
|
usually be created by the :class:`Session <Session>` class under the
|
||||||
|
covers.
|
||||||
|
|
||||||
|
:param pool_connections: The number of urllib3 connection pools to cache.
|
||||||
|
:param pool_maxsize: The maximum number of connections to save in the pool.
|
||||||
|
:param max_retries: The maximum number of retries each connection
|
||||||
|
should attempt. Note, this applies only to failed DNS lookups, socket
|
||||||
|
connections and connection timeouts, never to requests where data has
|
||||||
|
made it to the server. By default, Requests does not retry failed
|
||||||
|
connections. If you need granular control over the conditions under
|
||||||
|
which we retry a request, import urllib3's ``Retry`` class and pass
|
||||||
|
that instead.
|
||||||
|
:param pool_block: Whether the connection pool should block for connections.
|
||||||
|
|
||||||
|
Usage::
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> s = requests.Session()
|
||||||
|
>>> a = requests.adapters.HTTPAdapter(max_retries=3)
|
||||||
|
>>> s.mount('http://', a)
|
||||||
|
"""
|
||||||
|
|
||||||
|
__attrs__ = [
|
||||||
|
"max_retries",
|
||||||
|
"config",
|
||||||
|
"_pool_connections",
|
||||||
|
"_pool_maxsize",
|
||||||
|
"_pool_block",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
pool_connections=DEFAULT_POOLSIZE,
|
||||||
|
pool_maxsize=DEFAULT_POOLSIZE,
|
||||||
|
max_retries=DEFAULT_RETRIES,
|
||||||
|
pool_block=DEFAULT_POOLBLOCK,
|
||||||
|
):
|
||||||
|
if max_retries == DEFAULT_RETRIES:
|
||||||
|
self.max_retries = Retry(0, read=False)
|
||||||
|
else:
|
||||||
|
self.max_retries = Retry.from_int(max_retries)
|
||||||
|
self.config = {}
|
||||||
|
self.proxy_manager = {}
|
||||||
|
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
self._pool_connections = pool_connections
|
||||||
|
self._pool_maxsize = pool_maxsize
|
||||||
|
self._pool_block = pool_block
|
||||||
|
|
||||||
|
self.init_poolmanager(pool_connections, pool_maxsize, block=pool_block)
|
||||||
|
|
||||||
|
def __getstate__(self):
|
||||||
|
return {attr: getattr(self, attr, None) for attr in self.__attrs__}
|
||||||
|
|
||||||
|
def __setstate__(self, state):
|
||||||
|
# Can't handle by adding 'proxy_manager' to self.__attrs__ because
|
||||||
|
# self.poolmanager uses a lambda function, which isn't pickleable.
|
||||||
|
self.proxy_manager = {}
|
||||||
|
self.config = {}
|
||||||
|
|
||||||
|
for attr, value in state.items():
|
||||||
|
setattr(self, attr, value)
|
||||||
|
|
||||||
|
self.init_poolmanager(
|
||||||
|
self._pool_connections, self._pool_maxsize, block=self._pool_block
|
||||||
|
)
|
||||||
|
|
||||||
|
def init_poolmanager(
|
||||||
|
self, connections, maxsize, block=DEFAULT_POOLBLOCK, **pool_kwargs
|
||||||
|
):
|
||||||
|
"""Initializes a urllib3 PoolManager.
|
||||||
|
|
||||||
|
This method should not be called from user code, and is only
|
||||||
|
exposed for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param connections: The number of urllib3 connection pools to cache.
|
||||||
|
:param maxsize: The maximum number of connections to save in the pool.
|
||||||
|
:param block: Block when no free connections are available.
|
||||||
|
:param pool_kwargs: Extra keyword arguments used to initialize the Pool Manager.
|
||||||
|
"""
|
||||||
|
# save these values for pickling
|
||||||
|
self._pool_connections = connections
|
||||||
|
self._pool_maxsize = maxsize
|
||||||
|
self._pool_block = block
|
||||||
|
|
||||||
|
self.poolmanager = PoolManager(
|
||||||
|
num_pools=connections,
|
||||||
|
maxsize=maxsize,
|
||||||
|
block=block,
|
||||||
|
**pool_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
def proxy_manager_for(self, proxy, **proxy_kwargs):
|
||||||
|
"""Return urllib3 ProxyManager for the given proxy.
|
||||||
|
|
||||||
|
This method should not be called from user code, and is only
|
||||||
|
exposed for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param proxy: The proxy to return a urllib3 ProxyManager for.
|
||||||
|
:param proxy_kwargs: Extra keyword arguments used to configure the Proxy Manager.
|
||||||
|
:returns: ProxyManager
|
||||||
|
:rtype: urllib3.ProxyManager
|
||||||
|
"""
|
||||||
|
if proxy in self.proxy_manager:
|
||||||
|
manager = self.proxy_manager[proxy]
|
||||||
|
elif proxy.lower().startswith("socks"):
|
||||||
|
username, password = get_auth_from_url(proxy)
|
||||||
|
manager = self.proxy_manager[proxy] = SOCKSProxyManager(
|
||||||
|
proxy,
|
||||||
|
username=username,
|
||||||
|
password=password,
|
||||||
|
num_pools=self._pool_connections,
|
||||||
|
maxsize=self._pool_maxsize,
|
||||||
|
block=self._pool_block,
|
||||||
|
**proxy_kwargs,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
proxy_headers = self.proxy_headers(proxy)
|
||||||
|
manager = self.proxy_manager[proxy] = proxy_from_url(
|
||||||
|
proxy,
|
||||||
|
proxy_headers=proxy_headers,
|
||||||
|
num_pools=self._pool_connections,
|
||||||
|
maxsize=self._pool_maxsize,
|
||||||
|
block=self._pool_block,
|
||||||
|
**proxy_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
return manager
|
||||||
|
|
||||||
|
def cert_verify(self, conn, url, verify, cert):
|
||||||
|
"""Verify a SSL certificate. This method should not be called from user
|
||||||
|
code, and is only exposed for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param conn: The urllib3 connection object associated with the cert.
|
||||||
|
:param url: The requested URL.
|
||||||
|
:param verify: Either a boolean, in which case it controls whether we verify
|
||||||
|
the server's TLS certificate, or a string, in which case it must be a path
|
||||||
|
to a CA bundle to use
|
||||||
|
:param cert: The SSL certificate to verify.
|
||||||
|
"""
|
||||||
|
if url.lower().startswith("https") and verify:
|
||||||
|
cert_loc = None
|
||||||
|
|
||||||
|
# Allow self-specified cert location.
|
||||||
|
if verify is not True:
|
||||||
|
cert_loc = verify
|
||||||
|
|
||||||
|
if not cert_loc:
|
||||||
|
cert_loc = extract_zipped_paths(DEFAULT_CA_BUNDLE_PATH)
|
||||||
|
|
||||||
|
if not cert_loc or not os.path.exists(cert_loc):
|
||||||
|
raise OSError(
|
||||||
|
f"Could not find a suitable TLS CA certificate bundle, "
|
||||||
|
f"invalid path: {cert_loc}"
|
||||||
|
)
|
||||||
|
|
||||||
|
conn.cert_reqs = "CERT_REQUIRED"
|
||||||
|
|
||||||
|
if not os.path.isdir(cert_loc):
|
||||||
|
conn.ca_certs = cert_loc
|
||||||
|
else:
|
||||||
|
conn.ca_cert_dir = cert_loc
|
||||||
|
else:
|
||||||
|
conn.cert_reqs = "CERT_NONE"
|
||||||
|
conn.ca_certs = None
|
||||||
|
conn.ca_cert_dir = None
|
||||||
|
|
||||||
|
if cert:
|
||||||
|
if not isinstance(cert, basestring):
|
||||||
|
conn.cert_file = cert[0]
|
||||||
|
conn.key_file = cert[1]
|
||||||
|
else:
|
||||||
|
conn.cert_file = cert
|
||||||
|
conn.key_file = None
|
||||||
|
if conn.cert_file and not os.path.exists(conn.cert_file):
|
||||||
|
raise OSError(
|
||||||
|
f"Could not find the TLS certificate file, "
|
||||||
|
f"invalid path: {conn.cert_file}"
|
||||||
|
)
|
||||||
|
if conn.key_file and not os.path.exists(conn.key_file):
|
||||||
|
raise OSError(
|
||||||
|
f"Could not find the TLS key file, invalid path: {conn.key_file}"
|
||||||
|
)
|
||||||
|
|
||||||
|
def build_response(self, req, resp):
|
||||||
|
"""Builds a :class:`Response <requests.Response>` object from a urllib3
|
||||||
|
response. This should not be called from user code, and is only exposed
|
||||||
|
for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`
|
||||||
|
|
||||||
|
:param req: The :class:`PreparedRequest <PreparedRequest>` used to generate the response.
|
||||||
|
:param resp: The urllib3 response object.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
response = Response()
|
||||||
|
|
||||||
|
# Fallback to None if there's no status_code, for whatever reason.
|
||||||
|
response.status_code = getattr(resp, "status", None)
|
||||||
|
|
||||||
|
# Make headers case-insensitive.
|
||||||
|
response.headers = CaseInsensitiveDict(getattr(resp, "headers", {}))
|
||||||
|
|
||||||
|
# Set encoding.
|
||||||
|
response.encoding = get_encoding_from_headers(response.headers)
|
||||||
|
response.raw = resp
|
||||||
|
response.reason = response.raw.reason
|
||||||
|
|
||||||
|
if isinstance(req.url, bytes):
|
||||||
|
response.url = req.url.decode("utf-8")
|
||||||
|
else:
|
||||||
|
response.url = req.url
|
||||||
|
|
||||||
|
# Add new cookies from the server.
|
||||||
|
extract_cookies_to_jar(response.cookies, req, resp)
|
||||||
|
|
||||||
|
# Give the Response some context.
|
||||||
|
response.request = req
|
||||||
|
response.connection = self
|
||||||
|
|
||||||
|
return response
|
||||||
|
|
||||||
|
def build_connection_pool_key_attributes(self, request, verify, cert=None):
|
||||||
|
"""Build the PoolKey attributes used by urllib3 to return a connection.
|
||||||
|
|
||||||
|
This looks at the PreparedRequest, the user-specified verify value,
|
||||||
|
and the value of the cert parameter to determine what PoolKey values
|
||||||
|
to use to select a connection from a given urllib3 Connection Pool.
|
||||||
|
|
||||||
|
The SSL related pool key arguments are not consistently set. As of
|
||||||
|
this writing, use the following to determine what keys may be in that
|
||||||
|
dictionary:
|
||||||
|
|
||||||
|
* If ``verify`` is ``True``, ``"ssl_context"`` will be set and will be the
|
||||||
|
default Requests SSL Context
|
||||||
|
* If ``verify`` is ``False``, ``"ssl_context"`` will not be set but
|
||||||
|
``"cert_reqs"`` will be set
|
||||||
|
* If ``verify`` is a string, (i.e., it is a user-specified trust bundle)
|
||||||
|
``"ca_certs"`` will be set if the string is not a directory recognized
|
||||||
|
by :py:func:`os.path.isdir`, otherwise ``"ca_cert_dir"`` will be
|
||||||
|
set.
|
||||||
|
* If ``"cert"`` is specified, ``"cert_file"`` will always be set. If
|
||||||
|
``"cert"`` is a tuple with a second item, ``"key_file"`` will also
|
||||||
|
be present
|
||||||
|
|
||||||
|
To override these settings, one may subclass this class, call this
|
||||||
|
method and use the above logic to change parameters as desired. For
|
||||||
|
example, if one wishes to use a custom :py:class:`ssl.SSLContext` one
|
||||||
|
must both set ``"ssl_context"`` and based on what else they require,
|
||||||
|
alter the other keys to ensure the desired behaviour.
|
||||||
|
|
||||||
|
:param request:
|
||||||
|
The PreparedReqest being sent over the connection.
|
||||||
|
:type request:
|
||||||
|
:class:`~requests.models.PreparedRequest`
|
||||||
|
:param verify:
|
||||||
|
Either a boolean, in which case it controls whether
|
||||||
|
we verify the server's TLS certificate, or a string, in which case it
|
||||||
|
must be a path to a CA bundle to use.
|
||||||
|
:param cert:
|
||||||
|
(optional) Any user-provided SSL certificate for client
|
||||||
|
authentication (a.k.a., mTLS). This may be a string (i.e., just
|
||||||
|
the path to a file which holds both certificate and key) or a
|
||||||
|
tuple of length 2 with the certificate file path and key file
|
||||||
|
path.
|
||||||
|
:returns:
|
||||||
|
A tuple of two dictionaries. The first is the "host parameters"
|
||||||
|
portion of the Pool Key including scheme, hostname, and port. The
|
||||||
|
second is a dictionary of SSLContext related parameters.
|
||||||
|
"""
|
||||||
|
return _urllib3_request_context(request, verify, cert, self.poolmanager)
|
||||||
|
|
||||||
|
def get_connection_with_tls_context(self, request, verify, proxies=None, cert=None):
|
||||||
|
"""Returns a urllib3 connection for the given request and TLS settings.
|
||||||
|
This should not be called from user code, and is only exposed for use
|
||||||
|
when subclassing the :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param request:
|
||||||
|
The :class:`PreparedRequest <PreparedRequest>` object to be sent
|
||||||
|
over the connection.
|
||||||
|
:param verify:
|
||||||
|
Either a boolean, in which case it controls whether we verify the
|
||||||
|
server's TLS certificate, or a string, in which case it must be a
|
||||||
|
path to a CA bundle to use.
|
||||||
|
:param proxies:
|
||||||
|
(optional) The proxies dictionary to apply to the request.
|
||||||
|
:param cert:
|
||||||
|
(optional) Any user-provided SSL certificate to be used for client
|
||||||
|
authentication (a.k.a., mTLS).
|
||||||
|
:rtype:
|
||||||
|
urllib3.ConnectionPool
|
||||||
|
"""
|
||||||
|
proxy = select_proxy(request.url, proxies)
|
||||||
|
try:
|
||||||
|
host_params, pool_kwargs = self.build_connection_pool_key_attributes(
|
||||||
|
request,
|
||||||
|
verify,
|
||||||
|
cert,
|
||||||
|
)
|
||||||
|
except ValueError as e:
|
||||||
|
raise InvalidURL(e, request=request)
|
||||||
|
if proxy:
|
||||||
|
proxy = prepend_scheme_if_needed(proxy, "http")
|
||||||
|
proxy_url = parse_url(proxy)
|
||||||
|
if not proxy_url.host:
|
||||||
|
raise InvalidProxyURL(
|
||||||
|
"Please check proxy URL. It is malformed "
|
||||||
|
"and could be missing the host."
|
||||||
|
)
|
||||||
|
proxy_manager = self.proxy_manager_for(proxy)
|
||||||
|
conn = proxy_manager.connection_from_host(
|
||||||
|
**host_params, pool_kwargs=pool_kwargs
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# Only scheme should be lower case
|
||||||
|
conn = self.poolmanager.connection_from_host(
|
||||||
|
**host_params, pool_kwargs=pool_kwargs
|
||||||
|
)
|
||||||
|
|
||||||
|
return conn
|
||||||
|
|
||||||
|
def get_connection(self, url, proxies=None):
|
||||||
|
"""DEPRECATED: Users should move to `get_connection_with_tls_context`
|
||||||
|
for all subclasses of HTTPAdapter using Requests>=2.32.2.
|
||||||
|
|
||||||
|
Returns a urllib3 connection for the given URL. This should not be
|
||||||
|
called from user code, and is only exposed for use when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param url: The URL to connect to.
|
||||||
|
:param proxies: (optional) A Requests-style dictionary of proxies used on this request.
|
||||||
|
:rtype: urllib3.ConnectionPool
|
||||||
|
"""
|
||||||
|
warnings.warn(
|
||||||
|
(
|
||||||
|
"`get_connection` has been deprecated in favor of "
|
||||||
|
"`get_connection_with_tls_context`. Custom HTTPAdapter subclasses "
|
||||||
|
"will need to migrate for Requests>=2.32.2. Please see "
|
||||||
|
"https://github.com/psf/requests/pull/6710 for more details."
|
||||||
|
),
|
||||||
|
DeprecationWarning,
|
||||||
|
)
|
||||||
|
proxy = select_proxy(url, proxies)
|
||||||
|
|
||||||
|
if proxy:
|
||||||
|
proxy = prepend_scheme_if_needed(proxy, "http")
|
||||||
|
proxy_url = parse_url(proxy)
|
||||||
|
if not proxy_url.host:
|
||||||
|
raise InvalidProxyURL(
|
||||||
|
"Please check proxy URL. It is malformed "
|
||||||
|
"and could be missing the host."
|
||||||
|
)
|
||||||
|
proxy_manager = self.proxy_manager_for(proxy)
|
||||||
|
conn = proxy_manager.connection_from_url(url)
|
||||||
|
else:
|
||||||
|
# Only scheme should be lower case
|
||||||
|
parsed = urlparse(url)
|
||||||
|
url = parsed.geturl()
|
||||||
|
conn = self.poolmanager.connection_from_url(url)
|
||||||
|
|
||||||
|
return conn
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
"""Disposes of any internal state.
|
||||||
|
|
||||||
|
Currently, this closes the PoolManager and any active ProxyManager,
|
||||||
|
which closes any pooled connections.
|
||||||
|
"""
|
||||||
|
self.poolmanager.clear()
|
||||||
|
for proxy in self.proxy_manager.values():
|
||||||
|
proxy.clear()
|
||||||
|
|
||||||
|
def request_url(self, request, proxies):
|
||||||
|
"""Obtain the url to use when making the final request.
|
||||||
|
|
||||||
|
If the message is being sent through a HTTP proxy, the full URL has to
|
||||||
|
be used. Otherwise, we should only use the path portion of the URL.
|
||||||
|
|
||||||
|
This should not be called from user code, and is only exposed for use
|
||||||
|
when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
|
||||||
|
:param proxies: A dictionary of schemes or schemes and hosts to proxy URLs.
|
||||||
|
:rtype: str
|
||||||
|
"""
|
||||||
|
proxy = select_proxy(request.url, proxies)
|
||||||
|
scheme = urlparse(request.url).scheme
|
||||||
|
|
||||||
|
is_proxied_http_request = proxy and scheme != "https"
|
||||||
|
using_socks_proxy = False
|
||||||
|
if proxy:
|
||||||
|
proxy_scheme = urlparse(proxy).scheme.lower()
|
||||||
|
using_socks_proxy = proxy_scheme.startswith("socks")
|
||||||
|
|
||||||
|
url = request.path_url
|
||||||
|
if url.startswith("//"): # Don't confuse urllib3
|
||||||
|
url = f"/{url.lstrip('/')}"
|
||||||
|
|
||||||
|
if is_proxied_http_request and not using_socks_proxy:
|
||||||
|
url = urldefragauth(request.url)
|
||||||
|
|
||||||
|
return url
|
||||||
|
|
||||||
|
def add_headers(self, request, **kwargs):
|
||||||
|
"""Add any headers needed by the connection. As of v2.0 this does
|
||||||
|
nothing by default, but is left for overriding by users that subclass
|
||||||
|
the :class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
This should not be called from user code, and is only exposed for use
|
||||||
|
when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param request: The :class:`PreparedRequest <PreparedRequest>` to add headers to.
|
||||||
|
:param kwargs: The keyword arguments from the call to send().
|
||||||
|
"""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def proxy_headers(self, proxy):
|
||||||
|
"""Returns a dictionary of the headers to add to any request sent
|
||||||
|
through a proxy. This works with urllib3 magic to ensure that they are
|
||||||
|
correctly sent to the proxy, rather than in a tunnelled request if
|
||||||
|
CONNECT is being used.
|
||||||
|
|
||||||
|
This should not be called from user code, and is only exposed for use
|
||||||
|
when subclassing the
|
||||||
|
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>`.
|
||||||
|
|
||||||
|
:param proxy: The url of the proxy being used for this request.
|
||||||
|
:rtype: dict
|
||||||
|
"""
|
||||||
|
headers = {}
|
||||||
|
username, password = get_auth_from_url(proxy)
|
||||||
|
|
||||||
|
if username:
|
||||||
|
headers["Proxy-Authorization"] = _basic_auth_str(username, password)
|
||||||
|
|
||||||
|
return headers
|
||||||
|
|
||||||
|
def send(
|
||||||
|
self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None
|
||||||
|
):
|
||||||
|
"""Sends PreparedRequest object. Returns Response object.
|
||||||
|
|
||||||
|
:param request: The :class:`PreparedRequest <PreparedRequest>` being sent.
|
||||||
|
:param stream: (optional) Whether to stream the request content.
|
||||||
|
:param timeout: (optional) How long to wait for the server to send
|
||||||
|
data before giving up, as a float, or a :ref:`(connect timeout,
|
||||||
|
read timeout) <timeouts>` tuple.
|
||||||
|
:type timeout: float or tuple or urllib3 Timeout object
|
||||||
|
:param verify: (optional) Either a boolean, in which case it controls whether
|
||||||
|
we verify the server's TLS certificate, or a string, in which case it
|
||||||
|
must be a path to a CA bundle to use
|
||||||
|
:param cert: (optional) Any user-provided SSL certificate to be trusted.
|
||||||
|
:param proxies: (optional) The proxies dictionary to apply to the request.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
try:
|
||||||
|
conn = self.get_connection_with_tls_context(
|
||||||
|
request, verify, proxies=proxies, cert=cert
|
||||||
|
)
|
||||||
|
except LocationValueError as e:
|
||||||
|
raise InvalidURL(e, request=request)
|
||||||
|
|
||||||
|
self.cert_verify(conn, request.url, verify, cert)
|
||||||
|
url = self.request_url(request, proxies)
|
||||||
|
self.add_headers(
|
||||||
|
request,
|
||||||
|
stream=stream,
|
||||||
|
timeout=timeout,
|
||||||
|
verify=verify,
|
||||||
|
cert=cert,
|
||||||
|
proxies=proxies,
|
||||||
|
)
|
||||||
|
|
||||||
|
chunked = not (request.body is None or "Content-Length" in request.headers)
|
||||||
|
|
||||||
|
if isinstance(timeout, tuple):
|
||||||
|
try:
|
||||||
|
connect, read = timeout
|
||||||
|
timeout = TimeoutSauce(connect=connect, read=read)
|
||||||
|
except ValueError:
|
||||||
|
raise ValueError(
|
||||||
|
f"Invalid timeout {timeout}. Pass a (connect, read) timeout tuple, "
|
||||||
|
f"or a single float to set both timeouts to the same value."
|
||||||
|
)
|
||||||
|
elif isinstance(timeout, TimeoutSauce):
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
timeout = TimeoutSauce(connect=timeout, read=timeout)
|
||||||
|
|
||||||
|
try:
|
||||||
|
resp = conn.urlopen(
|
||||||
|
method=request.method,
|
||||||
|
url=url,
|
||||||
|
body=request.body,
|
||||||
|
headers=request.headers,
|
||||||
|
redirect=False,
|
||||||
|
assert_same_host=False,
|
||||||
|
preload_content=False,
|
||||||
|
decode_content=False,
|
||||||
|
retries=self.max_retries,
|
||||||
|
timeout=timeout,
|
||||||
|
chunked=chunked,
|
||||||
|
)
|
||||||
|
|
||||||
|
except (ProtocolError, OSError) as err:
|
||||||
|
raise ConnectionError(err, request=request)
|
||||||
|
|
||||||
|
except MaxRetryError as e:
|
||||||
|
if isinstance(e.reason, ConnectTimeoutError):
|
||||||
|
# TODO: Remove this in 3.0.0: see #2811
|
||||||
|
if not isinstance(e.reason, NewConnectionError):
|
||||||
|
raise ConnectTimeout(e, request=request)
|
||||||
|
|
||||||
|
if isinstance(e.reason, ResponseError):
|
||||||
|
raise RetryError(e, request=request)
|
||||||
|
|
||||||
|
if isinstance(e.reason, _ProxyError):
|
||||||
|
raise ProxyError(e, request=request)
|
||||||
|
|
||||||
|
if isinstance(e.reason, _SSLError):
|
||||||
|
# This branch is for urllib3 v1.22 and later.
|
||||||
|
raise SSLError(e, request=request)
|
||||||
|
|
||||||
|
raise ConnectionError(e, request=request)
|
||||||
|
|
||||||
|
except ClosedPoolError as e:
|
||||||
|
raise ConnectionError(e, request=request)
|
||||||
|
|
||||||
|
except _ProxyError as e:
|
||||||
|
raise ProxyError(e)
|
||||||
|
|
||||||
|
except (_SSLError, _HTTPError) as e:
|
||||||
|
if isinstance(e, _SSLError):
|
||||||
|
# This branch is for urllib3 versions earlier than v1.22
|
||||||
|
raise SSLError(e, request=request)
|
||||||
|
elif isinstance(e, ReadTimeoutError):
|
||||||
|
raise ReadTimeout(e, request=request)
|
||||||
|
elif isinstance(e, _InvalidHeader):
|
||||||
|
raise InvalidHeader(e, request=request)
|
||||||
|
else:
|
||||||
|
raise
|
||||||
|
|
||||||
|
return self.build_response(request, resp)
|
||||||
157
venv/lib/python3.12/site-packages/requests/api.py
Normal file
157
venv/lib/python3.12/site-packages/requests/api.py
Normal file
@@ -0,0 +1,157 @@
|
|||||||
|
"""
|
||||||
|
requests.api
|
||||||
|
~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module implements the Requests API.
|
||||||
|
|
||||||
|
:copyright: (c) 2012 by Kenneth Reitz.
|
||||||
|
:license: Apache2, see LICENSE for more details.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from . import sessions
|
||||||
|
|
||||||
|
|
||||||
|
def request(method, url, **kwargs):
|
||||||
|
"""Constructs and sends a :class:`Request <Request>`.
|
||||||
|
|
||||||
|
:param method: method for the new :class:`Request` object: ``GET``, ``OPTIONS``, ``HEAD``, ``POST``, ``PUT``, ``PATCH``, or ``DELETE``.
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param params: (optional) Dictionary, list of tuples or bytes to send
|
||||||
|
in the query string for the :class:`Request`.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
|
||||||
|
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
|
||||||
|
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
|
||||||
|
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
|
||||||
|
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
|
||||||
|
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content_type'`` is a string
|
||||||
|
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
|
||||||
|
to add for the file.
|
||||||
|
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
|
||||||
|
:param timeout: (optional) How many seconds to wait for the server to send data
|
||||||
|
before giving up, as a float, or a :ref:`(connect timeout, read
|
||||||
|
timeout) <timeouts>` tuple.
|
||||||
|
:type timeout: float or tuple
|
||||||
|
:param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
|
||||||
|
:type allow_redirects: bool
|
||||||
|
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
|
||||||
|
:param verify: (optional) Either a boolean, in which case it controls whether we verify
|
||||||
|
the server's TLS certificate, or a string, in which case it must be a path
|
||||||
|
to a CA bundle to use. Defaults to ``True``.
|
||||||
|
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
|
||||||
|
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
|
||||||
|
Usage::
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> req = requests.request('GET', 'https://httpbin.org/get')
|
||||||
|
>>> req
|
||||||
|
<Response [200]>
|
||||||
|
"""
|
||||||
|
|
||||||
|
# By using the 'with' statement we are sure the session is closed, thus we
|
||||||
|
# avoid leaving sockets open which can trigger a ResourceWarning in some
|
||||||
|
# cases, and look like a memory leak in others.
|
||||||
|
with sessions.Session() as session:
|
||||||
|
return session.request(method=method, url=url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def get(url, params=None, **kwargs):
|
||||||
|
r"""Sends a GET request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param params: (optional) Dictionary, list of tuples or bytes to send
|
||||||
|
in the query string for the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("get", url, params=params, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def options(url, **kwargs):
|
||||||
|
r"""Sends an OPTIONS request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("options", url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def head(url, **kwargs):
|
||||||
|
r"""Sends a HEAD request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes. If
|
||||||
|
`allow_redirects` is not provided, it will be set to `False` (as
|
||||||
|
opposed to the default :meth:`request` behavior).
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
kwargs.setdefault("allow_redirects", False)
|
||||||
|
return request("head", url, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def post(url, data=None, json=None, **kwargs):
|
||||||
|
r"""Sends a POST request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("post", url, data=data, json=json, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def put(url, data=None, **kwargs):
|
||||||
|
r"""Sends a PUT request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("put", url, data=data, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def patch(url, data=None, **kwargs):
|
||||||
|
r"""Sends a PATCH request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) A JSON serializable Python object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("patch", url, data=data, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
def delete(url, **kwargs):
|
||||||
|
r"""Sends a DELETE request.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:return: :class:`Response <Response>` object
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return request("delete", url, **kwargs)
|
||||||
314
venv/lib/python3.12/site-packages/requests/auth.py
Normal file
314
venv/lib/python3.12/site-packages/requests/auth.py
Normal file
@@ -0,0 +1,314 @@
|
|||||||
|
"""
|
||||||
|
requests.auth
|
||||||
|
~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module contains the authentication handlers for Requests.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import hashlib
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
import threading
|
||||||
|
import time
|
||||||
|
import warnings
|
||||||
|
from base64 import b64encode
|
||||||
|
|
||||||
|
from ._internal_utils import to_native_string
|
||||||
|
from .compat import basestring, str, urlparse
|
||||||
|
from .cookies import extract_cookies_to_jar
|
||||||
|
from .utils import parse_dict_header
|
||||||
|
|
||||||
|
CONTENT_TYPE_FORM_URLENCODED = "application/x-www-form-urlencoded"
|
||||||
|
CONTENT_TYPE_MULTI_PART = "multipart/form-data"
|
||||||
|
|
||||||
|
|
||||||
|
def _basic_auth_str(username, password):
|
||||||
|
"""Returns a Basic Auth string."""
|
||||||
|
|
||||||
|
# "I want us to put a big-ol' comment on top of it that
|
||||||
|
# says that this behaviour is dumb but we need to preserve
|
||||||
|
# it because people are relying on it."
|
||||||
|
# - Lukasa
|
||||||
|
#
|
||||||
|
# These are here solely to maintain backwards compatibility
|
||||||
|
# for things like ints. This will be removed in 3.0.0.
|
||||||
|
if not isinstance(username, basestring):
|
||||||
|
warnings.warn(
|
||||||
|
"Non-string usernames will no longer be supported in Requests "
|
||||||
|
"3.0.0. Please convert the object you've passed in ({!r}) to "
|
||||||
|
"a string or bytes object in the near future to avoid "
|
||||||
|
"problems.".format(username),
|
||||||
|
category=DeprecationWarning,
|
||||||
|
)
|
||||||
|
username = str(username)
|
||||||
|
|
||||||
|
if not isinstance(password, basestring):
|
||||||
|
warnings.warn(
|
||||||
|
"Non-string passwords will no longer be supported in Requests "
|
||||||
|
"3.0.0. Please convert the object you've passed in ({!r}) to "
|
||||||
|
"a string or bytes object in the near future to avoid "
|
||||||
|
"problems.".format(type(password)),
|
||||||
|
category=DeprecationWarning,
|
||||||
|
)
|
||||||
|
password = str(password)
|
||||||
|
# -- End Removal --
|
||||||
|
|
||||||
|
if isinstance(username, str):
|
||||||
|
username = username.encode("latin1")
|
||||||
|
|
||||||
|
if isinstance(password, str):
|
||||||
|
password = password.encode("latin1")
|
||||||
|
|
||||||
|
authstr = "Basic " + to_native_string(
|
||||||
|
b64encode(b":".join((username, password))).strip()
|
||||||
|
)
|
||||||
|
|
||||||
|
return authstr
|
||||||
|
|
||||||
|
|
||||||
|
class AuthBase:
|
||||||
|
"""Base class that all auth implementations derive from"""
|
||||||
|
|
||||||
|
def __call__(self, r):
|
||||||
|
raise NotImplementedError("Auth hooks must be callable.")
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPBasicAuth(AuthBase):
|
||||||
|
"""Attaches HTTP Basic Authentication to the given Request object."""
|
||||||
|
|
||||||
|
def __init__(self, username, password):
|
||||||
|
self.username = username
|
||||||
|
self.password = password
|
||||||
|
|
||||||
|
def __eq__(self, other):
|
||||||
|
return all(
|
||||||
|
[
|
||||||
|
self.username == getattr(other, "username", None),
|
||||||
|
self.password == getattr(other, "password", None),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
def __ne__(self, other):
|
||||||
|
return not self == other
|
||||||
|
|
||||||
|
def __call__(self, r):
|
||||||
|
r.headers["Authorization"] = _basic_auth_str(self.username, self.password)
|
||||||
|
return r
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPProxyAuth(HTTPBasicAuth):
|
||||||
|
"""Attaches HTTP Proxy Authentication to a given Request object."""
|
||||||
|
|
||||||
|
def __call__(self, r):
|
||||||
|
r.headers["Proxy-Authorization"] = _basic_auth_str(self.username, self.password)
|
||||||
|
return r
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPDigestAuth(AuthBase):
|
||||||
|
"""Attaches HTTP Digest Authentication to the given Request object."""
|
||||||
|
|
||||||
|
def __init__(self, username, password):
|
||||||
|
self.username = username
|
||||||
|
self.password = password
|
||||||
|
# Keep state in per-thread local storage
|
||||||
|
self._thread_local = threading.local()
|
||||||
|
|
||||||
|
def init_per_thread_state(self):
|
||||||
|
# Ensure state is initialized just once per-thread
|
||||||
|
if not hasattr(self._thread_local, "init"):
|
||||||
|
self._thread_local.init = True
|
||||||
|
self._thread_local.last_nonce = ""
|
||||||
|
self._thread_local.nonce_count = 0
|
||||||
|
self._thread_local.chal = {}
|
||||||
|
self._thread_local.pos = None
|
||||||
|
self._thread_local.num_401_calls = None
|
||||||
|
|
||||||
|
def build_digest_header(self, method, url):
|
||||||
|
"""
|
||||||
|
:rtype: str
|
||||||
|
"""
|
||||||
|
|
||||||
|
realm = self._thread_local.chal["realm"]
|
||||||
|
nonce = self._thread_local.chal["nonce"]
|
||||||
|
qop = self._thread_local.chal.get("qop")
|
||||||
|
algorithm = self._thread_local.chal.get("algorithm")
|
||||||
|
opaque = self._thread_local.chal.get("opaque")
|
||||||
|
hash_utf8 = None
|
||||||
|
|
||||||
|
if algorithm is None:
|
||||||
|
_algorithm = "MD5"
|
||||||
|
else:
|
||||||
|
_algorithm = algorithm.upper()
|
||||||
|
# lambdas assume digest modules are imported at the top level
|
||||||
|
if _algorithm == "MD5" or _algorithm == "MD5-SESS":
|
||||||
|
|
||||||
|
def md5_utf8(x):
|
||||||
|
if isinstance(x, str):
|
||||||
|
x = x.encode("utf-8")
|
||||||
|
return hashlib.md5(x).hexdigest()
|
||||||
|
|
||||||
|
hash_utf8 = md5_utf8
|
||||||
|
elif _algorithm == "SHA":
|
||||||
|
|
||||||
|
def sha_utf8(x):
|
||||||
|
if isinstance(x, str):
|
||||||
|
x = x.encode("utf-8")
|
||||||
|
return hashlib.sha1(x).hexdigest()
|
||||||
|
|
||||||
|
hash_utf8 = sha_utf8
|
||||||
|
elif _algorithm == "SHA-256":
|
||||||
|
|
||||||
|
def sha256_utf8(x):
|
||||||
|
if isinstance(x, str):
|
||||||
|
x = x.encode("utf-8")
|
||||||
|
return hashlib.sha256(x).hexdigest()
|
||||||
|
|
||||||
|
hash_utf8 = sha256_utf8
|
||||||
|
elif _algorithm == "SHA-512":
|
||||||
|
|
||||||
|
def sha512_utf8(x):
|
||||||
|
if isinstance(x, str):
|
||||||
|
x = x.encode("utf-8")
|
||||||
|
return hashlib.sha512(x).hexdigest()
|
||||||
|
|
||||||
|
hash_utf8 = sha512_utf8
|
||||||
|
|
||||||
|
KD = lambda s, d: hash_utf8(f"{s}:{d}") # noqa:E731
|
||||||
|
|
||||||
|
if hash_utf8 is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
# XXX not implemented yet
|
||||||
|
entdig = None
|
||||||
|
p_parsed = urlparse(url)
|
||||||
|
#: path is request-uri defined in RFC 2616 which should not be empty
|
||||||
|
path = p_parsed.path or "/"
|
||||||
|
if p_parsed.query:
|
||||||
|
path += f"?{p_parsed.query}"
|
||||||
|
|
||||||
|
A1 = f"{self.username}:{realm}:{self.password}"
|
||||||
|
A2 = f"{method}:{path}"
|
||||||
|
|
||||||
|
HA1 = hash_utf8(A1)
|
||||||
|
HA2 = hash_utf8(A2)
|
||||||
|
|
||||||
|
if nonce == self._thread_local.last_nonce:
|
||||||
|
self._thread_local.nonce_count += 1
|
||||||
|
else:
|
||||||
|
self._thread_local.nonce_count = 1
|
||||||
|
ncvalue = f"{self._thread_local.nonce_count:08x}"
|
||||||
|
s = str(self._thread_local.nonce_count).encode("utf-8")
|
||||||
|
s += nonce.encode("utf-8")
|
||||||
|
s += time.ctime().encode("utf-8")
|
||||||
|
s += os.urandom(8)
|
||||||
|
|
||||||
|
cnonce = hashlib.sha1(s).hexdigest()[:16]
|
||||||
|
if _algorithm == "MD5-SESS":
|
||||||
|
HA1 = hash_utf8(f"{HA1}:{nonce}:{cnonce}")
|
||||||
|
|
||||||
|
if not qop:
|
||||||
|
respdig = KD(HA1, f"{nonce}:{HA2}")
|
||||||
|
elif qop == "auth" or "auth" in qop.split(","):
|
||||||
|
noncebit = f"{nonce}:{ncvalue}:{cnonce}:auth:{HA2}"
|
||||||
|
respdig = KD(HA1, noncebit)
|
||||||
|
else:
|
||||||
|
# XXX handle auth-int.
|
||||||
|
return None
|
||||||
|
|
||||||
|
self._thread_local.last_nonce = nonce
|
||||||
|
|
||||||
|
# XXX should the partial digests be encoded too?
|
||||||
|
base = (
|
||||||
|
f'username="{self.username}", realm="{realm}", nonce="{nonce}", '
|
||||||
|
f'uri="{path}", response="{respdig}"'
|
||||||
|
)
|
||||||
|
if opaque:
|
||||||
|
base += f', opaque="{opaque}"'
|
||||||
|
if algorithm:
|
||||||
|
base += f', algorithm="{algorithm}"'
|
||||||
|
if entdig:
|
||||||
|
base += f', digest="{entdig}"'
|
||||||
|
if qop:
|
||||||
|
base += f', qop="auth", nc={ncvalue}, cnonce="{cnonce}"'
|
||||||
|
|
||||||
|
return f"Digest {base}"
|
||||||
|
|
||||||
|
def handle_redirect(self, r, **kwargs):
|
||||||
|
"""Reset num_401_calls counter on redirects."""
|
||||||
|
if r.is_redirect:
|
||||||
|
self._thread_local.num_401_calls = 1
|
||||||
|
|
||||||
|
def handle_401(self, r, **kwargs):
|
||||||
|
"""
|
||||||
|
Takes the given response and tries digest-auth, if needed.
|
||||||
|
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
# If response is not 4xx, do not auth
|
||||||
|
# See https://github.com/psf/requests/issues/3772
|
||||||
|
if not 400 <= r.status_code < 500:
|
||||||
|
self._thread_local.num_401_calls = 1
|
||||||
|
return r
|
||||||
|
|
||||||
|
if self._thread_local.pos is not None:
|
||||||
|
# Rewind the file position indicator of the body to where
|
||||||
|
# it was to resend the request.
|
||||||
|
r.request.body.seek(self._thread_local.pos)
|
||||||
|
s_auth = r.headers.get("www-authenticate", "")
|
||||||
|
|
||||||
|
if "digest" in s_auth.lower() and self._thread_local.num_401_calls < 2:
|
||||||
|
self._thread_local.num_401_calls += 1
|
||||||
|
pat = re.compile(r"digest ", flags=re.IGNORECASE)
|
||||||
|
self._thread_local.chal = parse_dict_header(pat.sub("", s_auth, count=1))
|
||||||
|
|
||||||
|
# Consume content and release the original connection
|
||||||
|
# to allow our new request to reuse the same one.
|
||||||
|
r.content
|
||||||
|
r.close()
|
||||||
|
prep = r.request.copy()
|
||||||
|
extract_cookies_to_jar(prep._cookies, r.request, r.raw)
|
||||||
|
prep.prepare_cookies(prep._cookies)
|
||||||
|
|
||||||
|
prep.headers["Authorization"] = self.build_digest_header(
|
||||||
|
prep.method, prep.url
|
||||||
|
)
|
||||||
|
_r = r.connection.send(prep, **kwargs)
|
||||||
|
_r.history.append(r)
|
||||||
|
_r.request = prep
|
||||||
|
|
||||||
|
return _r
|
||||||
|
|
||||||
|
self._thread_local.num_401_calls = 1
|
||||||
|
return r
|
||||||
|
|
||||||
|
def __call__(self, r):
|
||||||
|
# Initialize per-thread state, if needed
|
||||||
|
self.init_per_thread_state()
|
||||||
|
# If we have a saved nonce, skip the 401
|
||||||
|
if self._thread_local.last_nonce:
|
||||||
|
r.headers["Authorization"] = self.build_digest_header(r.method, r.url)
|
||||||
|
try:
|
||||||
|
self._thread_local.pos = r.body.tell()
|
||||||
|
except AttributeError:
|
||||||
|
# In the case of HTTPDigestAuth being reused and the body of
|
||||||
|
# the previous request was a file-like object, pos has the
|
||||||
|
# file position of the previous body. Ensure it's set to
|
||||||
|
# None.
|
||||||
|
self._thread_local.pos = None
|
||||||
|
r.register_hook("response", self.handle_401)
|
||||||
|
r.register_hook("response", self.handle_redirect)
|
||||||
|
self._thread_local.num_401_calls = 1
|
||||||
|
|
||||||
|
return r
|
||||||
|
|
||||||
|
def __eq__(self, other):
|
||||||
|
return all(
|
||||||
|
[
|
||||||
|
self.username == getattr(other, "username", None),
|
||||||
|
self.password == getattr(other, "password", None),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
def __ne__(self, other):
|
||||||
|
return not self == other
|
||||||
17
venv/lib/python3.12/site-packages/requests/certs.py
Normal file
17
venv/lib/python3.12/site-packages/requests/certs.py
Normal file
@@ -0,0 +1,17 @@
|
|||||||
|
#!/usr/bin/env python
|
||||||
|
|
||||||
|
"""
|
||||||
|
requests.certs
|
||||||
|
~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module returns the preferred default CA certificate bundle. There is
|
||||||
|
only one — the one from the certifi package.
|
||||||
|
|
||||||
|
If you are packaging Requests, e.g., for a Linux distribution or a managed
|
||||||
|
environment, you can change the definition of where() to return a separately
|
||||||
|
packaged CA bundle.
|
||||||
|
"""
|
||||||
|
from certifi import where
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
print(where())
|
||||||
106
venv/lib/python3.12/site-packages/requests/compat.py
Normal file
106
venv/lib/python3.12/site-packages/requests/compat.py
Normal file
@@ -0,0 +1,106 @@
|
|||||||
|
"""
|
||||||
|
requests.compat
|
||||||
|
~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module previously handled import compatibility issues
|
||||||
|
between Python 2 and Python 3. It remains for backwards
|
||||||
|
compatibility until the next major version.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import importlib
|
||||||
|
import sys
|
||||||
|
|
||||||
|
# -------
|
||||||
|
# urllib3
|
||||||
|
# -------
|
||||||
|
from urllib3 import __version__ as urllib3_version
|
||||||
|
|
||||||
|
# Detect which major version of urllib3 is being used.
|
||||||
|
try:
|
||||||
|
is_urllib3_1 = int(urllib3_version.split(".")[0]) == 1
|
||||||
|
except (TypeError, AttributeError):
|
||||||
|
# If we can't discern a version, prefer old functionality.
|
||||||
|
is_urllib3_1 = True
|
||||||
|
|
||||||
|
# -------------------
|
||||||
|
# Character Detection
|
||||||
|
# -------------------
|
||||||
|
|
||||||
|
|
||||||
|
def _resolve_char_detection():
|
||||||
|
"""Find supported character detection libraries."""
|
||||||
|
chardet = None
|
||||||
|
for lib in ("chardet", "charset_normalizer"):
|
||||||
|
if chardet is None:
|
||||||
|
try:
|
||||||
|
chardet = importlib.import_module(lib)
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
return chardet
|
||||||
|
|
||||||
|
|
||||||
|
chardet = _resolve_char_detection()
|
||||||
|
|
||||||
|
# -------
|
||||||
|
# Pythons
|
||||||
|
# -------
|
||||||
|
|
||||||
|
# Syntax sugar.
|
||||||
|
_ver = sys.version_info
|
||||||
|
|
||||||
|
#: Python 2.x?
|
||||||
|
is_py2 = _ver[0] == 2
|
||||||
|
|
||||||
|
#: Python 3.x?
|
||||||
|
is_py3 = _ver[0] == 3
|
||||||
|
|
||||||
|
# json/simplejson module import resolution
|
||||||
|
has_simplejson = False
|
||||||
|
try:
|
||||||
|
import simplejson as json
|
||||||
|
|
||||||
|
has_simplejson = True
|
||||||
|
except ImportError:
|
||||||
|
import json
|
||||||
|
|
||||||
|
if has_simplejson:
|
||||||
|
from simplejson import JSONDecodeError
|
||||||
|
else:
|
||||||
|
from json import JSONDecodeError
|
||||||
|
|
||||||
|
# Keep OrderedDict for backwards compatibility.
|
||||||
|
from collections import OrderedDict
|
||||||
|
from collections.abc import Callable, Mapping, MutableMapping
|
||||||
|
from http import cookiejar as cookielib
|
||||||
|
from http.cookies import Morsel
|
||||||
|
from io import StringIO
|
||||||
|
|
||||||
|
# --------------
|
||||||
|
# Legacy Imports
|
||||||
|
# --------------
|
||||||
|
from urllib.parse import (
|
||||||
|
quote,
|
||||||
|
quote_plus,
|
||||||
|
unquote,
|
||||||
|
unquote_plus,
|
||||||
|
urldefrag,
|
||||||
|
urlencode,
|
||||||
|
urljoin,
|
||||||
|
urlparse,
|
||||||
|
urlsplit,
|
||||||
|
urlunparse,
|
||||||
|
)
|
||||||
|
from urllib.request import (
|
||||||
|
getproxies,
|
||||||
|
getproxies_environment,
|
||||||
|
parse_http_list,
|
||||||
|
proxy_bypass,
|
||||||
|
proxy_bypass_environment,
|
||||||
|
)
|
||||||
|
|
||||||
|
builtin_str = str
|
||||||
|
str = str
|
||||||
|
bytes = bytes
|
||||||
|
basestring = (str, bytes)
|
||||||
|
numeric_types = (int, float)
|
||||||
|
integer_types = (int,)
|
||||||
561
venv/lib/python3.12/site-packages/requests/cookies.py
Normal file
561
venv/lib/python3.12/site-packages/requests/cookies.py
Normal file
@@ -0,0 +1,561 @@
|
|||||||
|
"""
|
||||||
|
requests.cookies
|
||||||
|
~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
Compatibility code to be able to use `http.cookiejar.CookieJar` with requests.
|
||||||
|
|
||||||
|
requests.utils imports from here, so be careful with imports.
|
||||||
|
"""
|
||||||
|
|
||||||
|
import calendar
|
||||||
|
import copy
|
||||||
|
import time
|
||||||
|
|
||||||
|
from ._internal_utils import to_native_string
|
||||||
|
from .compat import Morsel, MutableMapping, cookielib, urlparse, urlunparse
|
||||||
|
|
||||||
|
try:
|
||||||
|
import threading
|
||||||
|
except ImportError:
|
||||||
|
import dummy_threading as threading
|
||||||
|
|
||||||
|
|
||||||
|
class MockRequest:
|
||||||
|
"""Wraps a `requests.Request` to mimic a `urllib2.Request`.
|
||||||
|
|
||||||
|
The code in `http.cookiejar.CookieJar` expects this interface in order to correctly
|
||||||
|
manage cookie policies, i.e., determine whether a cookie can be set, given the
|
||||||
|
domains of the request and the cookie.
|
||||||
|
|
||||||
|
The original request object is read-only. The client is responsible for collecting
|
||||||
|
the new headers via `get_new_headers()` and interpreting them appropriately. You
|
||||||
|
probably want `get_cookie_header`, defined below.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, request):
|
||||||
|
self._r = request
|
||||||
|
self._new_headers = {}
|
||||||
|
self.type = urlparse(self._r.url).scheme
|
||||||
|
|
||||||
|
def get_type(self):
|
||||||
|
return self.type
|
||||||
|
|
||||||
|
def get_host(self):
|
||||||
|
return urlparse(self._r.url).netloc
|
||||||
|
|
||||||
|
def get_origin_req_host(self):
|
||||||
|
return self.get_host()
|
||||||
|
|
||||||
|
def get_full_url(self):
|
||||||
|
# Only return the response's URL if the user hadn't set the Host
|
||||||
|
# header
|
||||||
|
if not self._r.headers.get("Host"):
|
||||||
|
return self._r.url
|
||||||
|
# If they did set it, retrieve it and reconstruct the expected domain
|
||||||
|
host = to_native_string(self._r.headers["Host"], encoding="utf-8")
|
||||||
|
parsed = urlparse(self._r.url)
|
||||||
|
# Reconstruct the URL as we expect it
|
||||||
|
return urlunparse(
|
||||||
|
[
|
||||||
|
parsed.scheme,
|
||||||
|
host,
|
||||||
|
parsed.path,
|
||||||
|
parsed.params,
|
||||||
|
parsed.query,
|
||||||
|
parsed.fragment,
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
def is_unverifiable(self):
|
||||||
|
return True
|
||||||
|
|
||||||
|
def has_header(self, name):
|
||||||
|
return name in self._r.headers or name in self._new_headers
|
||||||
|
|
||||||
|
def get_header(self, name, default=None):
|
||||||
|
return self._r.headers.get(name, self._new_headers.get(name, default))
|
||||||
|
|
||||||
|
def add_header(self, key, val):
|
||||||
|
"""cookiejar has no legitimate use for this method; add it back if you find one."""
|
||||||
|
raise NotImplementedError(
|
||||||
|
"Cookie headers should be added with add_unredirected_header()"
|
||||||
|
)
|
||||||
|
|
||||||
|
def add_unredirected_header(self, name, value):
|
||||||
|
self._new_headers[name] = value
|
||||||
|
|
||||||
|
def get_new_headers(self):
|
||||||
|
return self._new_headers
|
||||||
|
|
||||||
|
@property
|
||||||
|
def unverifiable(self):
|
||||||
|
return self.is_unverifiable()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def origin_req_host(self):
|
||||||
|
return self.get_origin_req_host()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def host(self):
|
||||||
|
return self.get_host()
|
||||||
|
|
||||||
|
|
||||||
|
class MockResponse:
|
||||||
|
"""Wraps a `httplib.HTTPMessage` to mimic a `urllib.addinfourl`.
|
||||||
|
|
||||||
|
...what? Basically, expose the parsed HTTP headers from the server response
|
||||||
|
the way `http.cookiejar` expects to see them.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, headers):
|
||||||
|
"""Make a MockResponse for `cookiejar` to read.
|
||||||
|
|
||||||
|
:param headers: a httplib.HTTPMessage or analogous carrying the headers
|
||||||
|
"""
|
||||||
|
self._headers = headers
|
||||||
|
|
||||||
|
def info(self):
|
||||||
|
return self._headers
|
||||||
|
|
||||||
|
def getheaders(self, name):
|
||||||
|
self._headers.getheaders(name)
|
||||||
|
|
||||||
|
|
||||||
|
def extract_cookies_to_jar(jar, request, response):
|
||||||
|
"""Extract the cookies from the response into a CookieJar.
|
||||||
|
|
||||||
|
:param jar: http.cookiejar.CookieJar (not necessarily a RequestsCookieJar)
|
||||||
|
:param request: our own requests.Request object
|
||||||
|
:param response: urllib3.HTTPResponse object
|
||||||
|
"""
|
||||||
|
if not (hasattr(response, "_original_response") and response._original_response):
|
||||||
|
return
|
||||||
|
# the _original_response field is the wrapped httplib.HTTPResponse object,
|
||||||
|
req = MockRequest(request)
|
||||||
|
# pull out the HTTPMessage with the headers and put it in the mock:
|
||||||
|
res = MockResponse(response._original_response.msg)
|
||||||
|
jar.extract_cookies(res, req)
|
||||||
|
|
||||||
|
|
||||||
|
def get_cookie_header(jar, request):
|
||||||
|
"""
|
||||||
|
Produce an appropriate Cookie header string to be sent with `request`, or None.
|
||||||
|
|
||||||
|
:rtype: str
|
||||||
|
"""
|
||||||
|
r = MockRequest(request)
|
||||||
|
jar.add_cookie_header(r)
|
||||||
|
return r.get_new_headers().get("Cookie")
|
||||||
|
|
||||||
|
|
||||||
|
def remove_cookie_by_name(cookiejar, name, domain=None, path=None):
|
||||||
|
"""Unsets a cookie by name, by default over all domains and paths.
|
||||||
|
|
||||||
|
Wraps CookieJar.clear(), is O(n).
|
||||||
|
"""
|
||||||
|
clearables = []
|
||||||
|
for cookie in cookiejar:
|
||||||
|
if cookie.name != name:
|
||||||
|
continue
|
||||||
|
if domain is not None and domain != cookie.domain:
|
||||||
|
continue
|
||||||
|
if path is not None and path != cookie.path:
|
||||||
|
continue
|
||||||
|
clearables.append((cookie.domain, cookie.path, cookie.name))
|
||||||
|
|
||||||
|
for domain, path, name in clearables:
|
||||||
|
cookiejar.clear(domain, path, name)
|
||||||
|
|
||||||
|
|
||||||
|
class CookieConflictError(RuntimeError):
|
||||||
|
"""There are two cookies that meet the criteria specified in the cookie jar.
|
||||||
|
Use .get and .set and include domain and path args in order to be more specific.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class RequestsCookieJar(cookielib.CookieJar, MutableMapping):
|
||||||
|
"""Compatibility class; is a http.cookiejar.CookieJar, but exposes a dict
|
||||||
|
interface.
|
||||||
|
|
||||||
|
This is the CookieJar we create by default for requests and sessions that
|
||||||
|
don't specify one, since some clients may expect response.cookies and
|
||||||
|
session.cookies to support dict operations.
|
||||||
|
|
||||||
|
Requests does not use the dict interface internally; it's just for
|
||||||
|
compatibility with external client code. All requests code should work
|
||||||
|
out of the box with externally provided instances of ``CookieJar``, e.g.
|
||||||
|
``LWPCookieJar`` and ``FileCookieJar``.
|
||||||
|
|
||||||
|
Unlike a regular CookieJar, this class is pickleable.
|
||||||
|
|
||||||
|
.. warning:: dictionary operations that are normally O(1) may be O(n).
|
||||||
|
"""
|
||||||
|
|
||||||
|
def get(self, name, default=None, domain=None, path=None):
|
||||||
|
"""Dict-like get() that also supports optional domain and path args in
|
||||||
|
order to resolve naming collisions from using one cookie jar over
|
||||||
|
multiple domains.
|
||||||
|
|
||||||
|
.. warning:: operation is O(n), not O(1).
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
return self._find_no_duplicates(name, domain, path)
|
||||||
|
except KeyError:
|
||||||
|
return default
|
||||||
|
|
||||||
|
def set(self, name, value, **kwargs):
|
||||||
|
"""Dict-like set() that also supports optional domain and path args in
|
||||||
|
order to resolve naming collisions from using one cookie jar over
|
||||||
|
multiple domains.
|
||||||
|
"""
|
||||||
|
# support client code that unsets cookies by assignment of a None value:
|
||||||
|
if value is None:
|
||||||
|
remove_cookie_by_name(
|
||||||
|
self, name, domain=kwargs.get("domain"), path=kwargs.get("path")
|
||||||
|
)
|
||||||
|
return
|
||||||
|
|
||||||
|
if isinstance(value, Morsel):
|
||||||
|
c = morsel_to_cookie(value)
|
||||||
|
else:
|
||||||
|
c = create_cookie(name, value, **kwargs)
|
||||||
|
self.set_cookie(c)
|
||||||
|
return c
|
||||||
|
|
||||||
|
def iterkeys(self):
|
||||||
|
"""Dict-like iterkeys() that returns an iterator of names of cookies
|
||||||
|
from the jar.
|
||||||
|
|
||||||
|
.. seealso:: itervalues() and iteritems().
|
||||||
|
"""
|
||||||
|
for cookie in iter(self):
|
||||||
|
yield cookie.name
|
||||||
|
|
||||||
|
def keys(self):
|
||||||
|
"""Dict-like keys() that returns a list of names of cookies from the
|
||||||
|
jar.
|
||||||
|
|
||||||
|
.. seealso:: values() and items().
|
||||||
|
"""
|
||||||
|
return list(self.iterkeys())
|
||||||
|
|
||||||
|
def itervalues(self):
|
||||||
|
"""Dict-like itervalues() that returns an iterator of values of cookies
|
||||||
|
from the jar.
|
||||||
|
|
||||||
|
.. seealso:: iterkeys() and iteritems().
|
||||||
|
"""
|
||||||
|
for cookie in iter(self):
|
||||||
|
yield cookie.value
|
||||||
|
|
||||||
|
def values(self):
|
||||||
|
"""Dict-like values() that returns a list of values of cookies from the
|
||||||
|
jar.
|
||||||
|
|
||||||
|
.. seealso:: keys() and items().
|
||||||
|
"""
|
||||||
|
return list(self.itervalues())
|
||||||
|
|
||||||
|
def iteritems(self):
|
||||||
|
"""Dict-like iteritems() that returns an iterator of name-value tuples
|
||||||
|
from the jar.
|
||||||
|
|
||||||
|
.. seealso:: iterkeys() and itervalues().
|
||||||
|
"""
|
||||||
|
for cookie in iter(self):
|
||||||
|
yield cookie.name, cookie.value
|
||||||
|
|
||||||
|
def items(self):
|
||||||
|
"""Dict-like items() that returns a list of name-value tuples from the
|
||||||
|
jar. Allows client-code to call ``dict(RequestsCookieJar)`` and get a
|
||||||
|
vanilla python dict of key value pairs.
|
||||||
|
|
||||||
|
.. seealso:: keys() and values().
|
||||||
|
"""
|
||||||
|
return list(self.iteritems())
|
||||||
|
|
||||||
|
def list_domains(self):
|
||||||
|
"""Utility method to list all the domains in the jar."""
|
||||||
|
domains = []
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.domain not in domains:
|
||||||
|
domains.append(cookie.domain)
|
||||||
|
return domains
|
||||||
|
|
||||||
|
def list_paths(self):
|
||||||
|
"""Utility method to list all the paths in the jar."""
|
||||||
|
paths = []
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.path not in paths:
|
||||||
|
paths.append(cookie.path)
|
||||||
|
return paths
|
||||||
|
|
||||||
|
def multiple_domains(self):
|
||||||
|
"""Returns True if there are multiple domains in the jar.
|
||||||
|
Returns False otherwise.
|
||||||
|
|
||||||
|
:rtype: bool
|
||||||
|
"""
|
||||||
|
domains = []
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.domain is not None and cookie.domain in domains:
|
||||||
|
return True
|
||||||
|
domains.append(cookie.domain)
|
||||||
|
return False # there is only one domain in jar
|
||||||
|
|
||||||
|
def get_dict(self, domain=None, path=None):
|
||||||
|
"""Takes as an argument an optional domain and path and returns a plain
|
||||||
|
old Python dict of name-value pairs of cookies that meet the
|
||||||
|
requirements.
|
||||||
|
|
||||||
|
:rtype: dict
|
||||||
|
"""
|
||||||
|
dictionary = {}
|
||||||
|
for cookie in iter(self):
|
||||||
|
if (domain is None or cookie.domain == domain) and (
|
||||||
|
path is None or cookie.path == path
|
||||||
|
):
|
||||||
|
dictionary[cookie.name] = cookie.value
|
||||||
|
return dictionary
|
||||||
|
|
||||||
|
def __contains__(self, name):
|
||||||
|
try:
|
||||||
|
return super().__contains__(name)
|
||||||
|
except CookieConflictError:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def __getitem__(self, name):
|
||||||
|
"""Dict-like __getitem__() for compatibility with client code. Throws
|
||||||
|
exception if there are more than one cookie with name. In that case,
|
||||||
|
use the more explicit get() method instead.
|
||||||
|
|
||||||
|
.. warning:: operation is O(n), not O(1).
|
||||||
|
"""
|
||||||
|
return self._find_no_duplicates(name)
|
||||||
|
|
||||||
|
def __setitem__(self, name, value):
|
||||||
|
"""Dict-like __setitem__ for compatibility with client code. Throws
|
||||||
|
exception if there is already a cookie of that name in the jar. In that
|
||||||
|
case, use the more explicit set() method instead.
|
||||||
|
"""
|
||||||
|
self.set(name, value)
|
||||||
|
|
||||||
|
def __delitem__(self, name):
|
||||||
|
"""Deletes a cookie given a name. Wraps ``http.cookiejar.CookieJar``'s
|
||||||
|
``remove_cookie_by_name()``.
|
||||||
|
"""
|
||||||
|
remove_cookie_by_name(self, name)
|
||||||
|
|
||||||
|
def set_cookie(self, cookie, *args, **kwargs):
|
||||||
|
if (
|
||||||
|
hasattr(cookie.value, "startswith")
|
||||||
|
and cookie.value.startswith('"')
|
||||||
|
and cookie.value.endswith('"')
|
||||||
|
):
|
||||||
|
cookie.value = cookie.value.replace('\\"', "")
|
||||||
|
return super().set_cookie(cookie, *args, **kwargs)
|
||||||
|
|
||||||
|
def update(self, other):
|
||||||
|
"""Updates this jar with cookies from another CookieJar or dict-like"""
|
||||||
|
if isinstance(other, cookielib.CookieJar):
|
||||||
|
for cookie in other:
|
||||||
|
self.set_cookie(copy.copy(cookie))
|
||||||
|
else:
|
||||||
|
super().update(other)
|
||||||
|
|
||||||
|
def _find(self, name, domain=None, path=None):
|
||||||
|
"""Requests uses this method internally to get cookie values.
|
||||||
|
|
||||||
|
If there are conflicting cookies, _find arbitrarily chooses one.
|
||||||
|
See _find_no_duplicates if you want an exception thrown if there are
|
||||||
|
conflicting cookies.
|
||||||
|
|
||||||
|
:param name: a string containing name of cookie
|
||||||
|
:param domain: (optional) string containing domain of cookie
|
||||||
|
:param path: (optional) string containing path of cookie
|
||||||
|
:return: cookie.value
|
||||||
|
"""
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.name == name:
|
||||||
|
if domain is None or cookie.domain == domain:
|
||||||
|
if path is None or cookie.path == path:
|
||||||
|
return cookie.value
|
||||||
|
|
||||||
|
raise KeyError(f"name={name!r}, domain={domain!r}, path={path!r}")
|
||||||
|
|
||||||
|
def _find_no_duplicates(self, name, domain=None, path=None):
|
||||||
|
"""Both ``__get_item__`` and ``get`` call this function: it's never
|
||||||
|
used elsewhere in Requests.
|
||||||
|
|
||||||
|
:param name: a string containing name of cookie
|
||||||
|
:param domain: (optional) string containing domain of cookie
|
||||||
|
:param path: (optional) string containing path of cookie
|
||||||
|
:raises KeyError: if cookie is not found
|
||||||
|
:raises CookieConflictError: if there are multiple cookies
|
||||||
|
that match name and optionally domain and path
|
||||||
|
:return: cookie.value
|
||||||
|
"""
|
||||||
|
toReturn = None
|
||||||
|
for cookie in iter(self):
|
||||||
|
if cookie.name == name:
|
||||||
|
if domain is None or cookie.domain == domain:
|
||||||
|
if path is None or cookie.path == path:
|
||||||
|
if toReturn is not None:
|
||||||
|
# if there are multiple cookies that meet passed in criteria
|
||||||
|
raise CookieConflictError(
|
||||||
|
f"There are multiple cookies with name, {name!r}"
|
||||||
|
)
|
||||||
|
# we will eventually return this as long as no cookie conflict
|
||||||
|
toReturn = cookie.value
|
||||||
|
|
||||||
|
if toReturn:
|
||||||
|
return toReturn
|
||||||
|
raise KeyError(f"name={name!r}, domain={domain!r}, path={path!r}")
|
||||||
|
|
||||||
|
def __getstate__(self):
|
||||||
|
"""Unlike a normal CookieJar, this class is pickleable."""
|
||||||
|
state = self.__dict__.copy()
|
||||||
|
# remove the unpickleable RLock object
|
||||||
|
state.pop("_cookies_lock")
|
||||||
|
return state
|
||||||
|
|
||||||
|
def __setstate__(self, state):
|
||||||
|
"""Unlike a normal CookieJar, this class is pickleable."""
|
||||||
|
self.__dict__.update(state)
|
||||||
|
if "_cookies_lock" not in self.__dict__:
|
||||||
|
self._cookies_lock = threading.RLock()
|
||||||
|
|
||||||
|
def copy(self):
|
||||||
|
"""Return a copy of this RequestsCookieJar."""
|
||||||
|
new_cj = RequestsCookieJar()
|
||||||
|
new_cj.set_policy(self.get_policy())
|
||||||
|
new_cj.update(self)
|
||||||
|
return new_cj
|
||||||
|
|
||||||
|
def get_policy(self):
|
||||||
|
"""Return the CookiePolicy instance used."""
|
||||||
|
return self._policy
|
||||||
|
|
||||||
|
|
||||||
|
def _copy_cookie_jar(jar):
|
||||||
|
if jar is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
if hasattr(jar, "copy"):
|
||||||
|
# We're dealing with an instance of RequestsCookieJar
|
||||||
|
return jar.copy()
|
||||||
|
# We're dealing with a generic CookieJar instance
|
||||||
|
new_jar = copy.copy(jar)
|
||||||
|
new_jar.clear()
|
||||||
|
for cookie in jar:
|
||||||
|
new_jar.set_cookie(copy.copy(cookie))
|
||||||
|
return new_jar
|
||||||
|
|
||||||
|
|
||||||
|
def create_cookie(name, value, **kwargs):
|
||||||
|
"""Make a cookie from underspecified parameters.
|
||||||
|
|
||||||
|
By default, the pair of `name` and `value` will be set for the domain ''
|
||||||
|
and sent on every request (this is sometimes called a "supercookie").
|
||||||
|
"""
|
||||||
|
result = {
|
||||||
|
"version": 0,
|
||||||
|
"name": name,
|
||||||
|
"value": value,
|
||||||
|
"port": None,
|
||||||
|
"domain": "",
|
||||||
|
"path": "/",
|
||||||
|
"secure": False,
|
||||||
|
"expires": None,
|
||||||
|
"discard": True,
|
||||||
|
"comment": None,
|
||||||
|
"comment_url": None,
|
||||||
|
"rest": {"HttpOnly": None},
|
||||||
|
"rfc2109": False,
|
||||||
|
}
|
||||||
|
|
||||||
|
badargs = set(kwargs) - set(result)
|
||||||
|
if badargs:
|
||||||
|
raise TypeError(
|
||||||
|
f"create_cookie() got unexpected keyword arguments: {list(badargs)}"
|
||||||
|
)
|
||||||
|
|
||||||
|
result.update(kwargs)
|
||||||
|
result["port_specified"] = bool(result["port"])
|
||||||
|
result["domain_specified"] = bool(result["domain"])
|
||||||
|
result["domain_initial_dot"] = result["domain"].startswith(".")
|
||||||
|
result["path_specified"] = bool(result["path"])
|
||||||
|
|
||||||
|
return cookielib.Cookie(**result)
|
||||||
|
|
||||||
|
|
||||||
|
def morsel_to_cookie(morsel):
|
||||||
|
"""Convert a Morsel object into a Cookie containing the one k/v pair."""
|
||||||
|
|
||||||
|
expires = None
|
||||||
|
if morsel["max-age"]:
|
||||||
|
try:
|
||||||
|
expires = int(time.time() + int(morsel["max-age"]))
|
||||||
|
except ValueError:
|
||||||
|
raise TypeError(f"max-age: {morsel['max-age']} must be integer")
|
||||||
|
elif morsel["expires"]:
|
||||||
|
time_template = "%a, %d-%b-%Y %H:%M:%S GMT"
|
||||||
|
expires = calendar.timegm(time.strptime(morsel["expires"], time_template))
|
||||||
|
return create_cookie(
|
||||||
|
comment=morsel["comment"],
|
||||||
|
comment_url=bool(morsel["comment"]),
|
||||||
|
discard=False,
|
||||||
|
domain=morsel["domain"],
|
||||||
|
expires=expires,
|
||||||
|
name=morsel.key,
|
||||||
|
path=morsel["path"],
|
||||||
|
port=None,
|
||||||
|
rest={"HttpOnly": morsel["httponly"]},
|
||||||
|
rfc2109=False,
|
||||||
|
secure=bool(morsel["secure"]),
|
||||||
|
value=morsel.value,
|
||||||
|
version=morsel["version"] or 0,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def cookiejar_from_dict(cookie_dict, cookiejar=None, overwrite=True):
|
||||||
|
"""Returns a CookieJar from a key/value dictionary.
|
||||||
|
|
||||||
|
:param cookie_dict: Dict of key/values to insert into CookieJar.
|
||||||
|
:param cookiejar: (optional) A cookiejar to add the cookies to.
|
||||||
|
:param overwrite: (optional) If False, will not replace cookies
|
||||||
|
already in the jar with new ones.
|
||||||
|
:rtype: CookieJar
|
||||||
|
"""
|
||||||
|
if cookiejar is None:
|
||||||
|
cookiejar = RequestsCookieJar()
|
||||||
|
|
||||||
|
if cookie_dict is not None:
|
||||||
|
names_from_jar = [cookie.name for cookie in cookiejar]
|
||||||
|
for name in cookie_dict:
|
||||||
|
if overwrite or (name not in names_from_jar):
|
||||||
|
cookiejar.set_cookie(create_cookie(name, cookie_dict[name]))
|
||||||
|
|
||||||
|
return cookiejar
|
||||||
|
|
||||||
|
|
||||||
|
def merge_cookies(cookiejar, cookies):
|
||||||
|
"""Add cookies to cookiejar and returns a merged CookieJar.
|
||||||
|
|
||||||
|
:param cookiejar: CookieJar object to add the cookies to.
|
||||||
|
:param cookies: Dictionary or CookieJar object to be added.
|
||||||
|
:rtype: CookieJar
|
||||||
|
"""
|
||||||
|
if not isinstance(cookiejar, cookielib.CookieJar):
|
||||||
|
raise ValueError("You can only merge into CookieJar")
|
||||||
|
|
||||||
|
if isinstance(cookies, dict):
|
||||||
|
cookiejar = cookiejar_from_dict(cookies, cookiejar=cookiejar, overwrite=False)
|
||||||
|
elif isinstance(cookies, cookielib.CookieJar):
|
||||||
|
try:
|
||||||
|
cookiejar.update(cookies)
|
||||||
|
except AttributeError:
|
||||||
|
for cookie_in_jar in cookies:
|
||||||
|
cookiejar.set_cookie(cookie_in_jar)
|
||||||
|
|
||||||
|
return cookiejar
|
||||||
151
venv/lib/python3.12/site-packages/requests/exceptions.py
Normal file
151
venv/lib/python3.12/site-packages/requests/exceptions.py
Normal file
@@ -0,0 +1,151 @@
|
|||||||
|
"""
|
||||||
|
requests.exceptions
|
||||||
|
~~~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module contains the set of Requests' exceptions.
|
||||||
|
"""
|
||||||
|
from urllib3.exceptions import HTTPError as BaseHTTPError
|
||||||
|
|
||||||
|
from .compat import JSONDecodeError as CompatJSONDecodeError
|
||||||
|
|
||||||
|
|
||||||
|
class RequestException(IOError):
|
||||||
|
"""There was an ambiguous exception that occurred while handling your
|
||||||
|
request.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, *args, **kwargs):
|
||||||
|
"""Initialize RequestException with `request` and `response` objects."""
|
||||||
|
response = kwargs.pop("response", None)
|
||||||
|
self.response = response
|
||||||
|
self.request = kwargs.pop("request", None)
|
||||||
|
if response is not None and not self.request and hasattr(response, "request"):
|
||||||
|
self.request = self.response.request
|
||||||
|
super().__init__(*args, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidJSONError(RequestException):
|
||||||
|
"""A JSON error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class JSONDecodeError(InvalidJSONError, CompatJSONDecodeError):
|
||||||
|
"""Couldn't decode the text into json"""
|
||||||
|
|
||||||
|
def __init__(self, *args, **kwargs):
|
||||||
|
"""
|
||||||
|
Construct the JSONDecodeError instance first with all
|
||||||
|
args. Then use it's args to construct the IOError so that
|
||||||
|
the json specific args aren't used as IOError specific args
|
||||||
|
and the error message from JSONDecodeError is preserved.
|
||||||
|
"""
|
||||||
|
CompatJSONDecodeError.__init__(self, *args)
|
||||||
|
InvalidJSONError.__init__(self, *self.args, **kwargs)
|
||||||
|
|
||||||
|
def __reduce__(self):
|
||||||
|
"""
|
||||||
|
The __reduce__ method called when pickling the object must
|
||||||
|
be the one from the JSONDecodeError (be it json/simplejson)
|
||||||
|
as it expects all the arguments for instantiation, not just
|
||||||
|
one like the IOError, and the MRO would by default call the
|
||||||
|
__reduce__ method from the IOError due to the inheritance order.
|
||||||
|
"""
|
||||||
|
return CompatJSONDecodeError.__reduce__(self)
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPError(RequestException):
|
||||||
|
"""An HTTP error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class ConnectionError(RequestException):
|
||||||
|
"""A Connection error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class ProxyError(ConnectionError):
|
||||||
|
"""A proxy error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class SSLError(ConnectionError):
|
||||||
|
"""An SSL error occurred."""
|
||||||
|
|
||||||
|
|
||||||
|
class Timeout(RequestException):
|
||||||
|
"""The request timed out.
|
||||||
|
|
||||||
|
Catching this error will catch both
|
||||||
|
:exc:`~requests.exceptions.ConnectTimeout` and
|
||||||
|
:exc:`~requests.exceptions.ReadTimeout` errors.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class ConnectTimeout(ConnectionError, Timeout):
|
||||||
|
"""The request timed out while trying to connect to the remote server.
|
||||||
|
|
||||||
|
Requests that produced this error are safe to retry.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class ReadTimeout(Timeout):
|
||||||
|
"""The server did not send any data in the allotted amount of time."""
|
||||||
|
|
||||||
|
|
||||||
|
class URLRequired(RequestException):
|
||||||
|
"""A valid URL is required to make a request."""
|
||||||
|
|
||||||
|
|
||||||
|
class TooManyRedirects(RequestException):
|
||||||
|
"""Too many redirects."""
|
||||||
|
|
||||||
|
|
||||||
|
class MissingSchema(RequestException, ValueError):
|
||||||
|
"""The URL scheme (e.g. http or https) is missing."""
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidSchema(RequestException, ValueError):
|
||||||
|
"""The URL scheme provided is either invalid or unsupported."""
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidURL(RequestException, ValueError):
|
||||||
|
"""The URL provided was somehow invalid."""
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidHeader(RequestException, ValueError):
|
||||||
|
"""The header value provided was somehow invalid."""
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidProxyURL(InvalidURL):
|
||||||
|
"""The proxy URL provided is invalid."""
|
||||||
|
|
||||||
|
|
||||||
|
class ChunkedEncodingError(RequestException):
|
||||||
|
"""The server declared chunked encoding but sent an invalid chunk."""
|
||||||
|
|
||||||
|
|
||||||
|
class ContentDecodingError(RequestException, BaseHTTPError):
|
||||||
|
"""Failed to decode response content."""
|
||||||
|
|
||||||
|
|
||||||
|
class StreamConsumedError(RequestException, TypeError):
|
||||||
|
"""The content for this response was already consumed."""
|
||||||
|
|
||||||
|
|
||||||
|
class RetryError(RequestException):
|
||||||
|
"""Custom retries logic failed"""
|
||||||
|
|
||||||
|
|
||||||
|
class UnrewindableBodyError(RequestException):
|
||||||
|
"""Requests encountered an error when trying to rewind a body."""
|
||||||
|
|
||||||
|
|
||||||
|
# Warnings
|
||||||
|
|
||||||
|
|
||||||
|
class RequestsWarning(Warning):
|
||||||
|
"""Base warning for Requests."""
|
||||||
|
|
||||||
|
|
||||||
|
class FileModeWarning(RequestsWarning, DeprecationWarning):
|
||||||
|
"""A file was opened in text mode, but Requests determined its binary length."""
|
||||||
|
|
||||||
|
|
||||||
|
class RequestsDependencyWarning(RequestsWarning):
|
||||||
|
"""An imported dependency doesn't match the expected version range."""
|
||||||
134
venv/lib/python3.12/site-packages/requests/help.py
Normal file
134
venv/lib/python3.12/site-packages/requests/help.py
Normal file
@@ -0,0 +1,134 @@
|
|||||||
|
"""Module containing bug report helper(s)."""
|
||||||
|
|
||||||
|
import json
|
||||||
|
import platform
|
||||||
|
import ssl
|
||||||
|
import sys
|
||||||
|
|
||||||
|
import idna
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
from . import __version__ as requests_version
|
||||||
|
|
||||||
|
try:
|
||||||
|
import charset_normalizer
|
||||||
|
except ImportError:
|
||||||
|
charset_normalizer = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
import chardet
|
||||||
|
except ImportError:
|
||||||
|
chardet = None
|
||||||
|
|
||||||
|
try:
|
||||||
|
from urllib3.contrib import pyopenssl
|
||||||
|
except ImportError:
|
||||||
|
pyopenssl = None
|
||||||
|
OpenSSL = None
|
||||||
|
cryptography = None
|
||||||
|
else:
|
||||||
|
import cryptography
|
||||||
|
import OpenSSL
|
||||||
|
|
||||||
|
|
||||||
|
def _implementation():
|
||||||
|
"""Return a dict with the Python implementation and version.
|
||||||
|
|
||||||
|
Provide both the name and the version of the Python implementation
|
||||||
|
currently running. For example, on CPython 3.10.3 it will return
|
||||||
|
{'name': 'CPython', 'version': '3.10.3'}.
|
||||||
|
|
||||||
|
This function works best on CPython and PyPy: in particular, it probably
|
||||||
|
doesn't work for Jython or IronPython. Future investigation should be done
|
||||||
|
to work out the correct shape of the code for those platforms.
|
||||||
|
"""
|
||||||
|
implementation = platform.python_implementation()
|
||||||
|
|
||||||
|
if implementation == "CPython":
|
||||||
|
implementation_version = platform.python_version()
|
||||||
|
elif implementation == "PyPy":
|
||||||
|
implementation_version = "{}.{}.{}".format(
|
||||||
|
sys.pypy_version_info.major,
|
||||||
|
sys.pypy_version_info.minor,
|
||||||
|
sys.pypy_version_info.micro,
|
||||||
|
)
|
||||||
|
if sys.pypy_version_info.releaselevel != "final":
|
||||||
|
implementation_version = "".join(
|
||||||
|
[implementation_version, sys.pypy_version_info.releaselevel]
|
||||||
|
)
|
||||||
|
elif implementation == "Jython":
|
||||||
|
implementation_version = platform.python_version() # Complete Guess
|
||||||
|
elif implementation == "IronPython":
|
||||||
|
implementation_version = platform.python_version() # Complete Guess
|
||||||
|
else:
|
||||||
|
implementation_version = "Unknown"
|
||||||
|
|
||||||
|
return {"name": implementation, "version": implementation_version}
|
||||||
|
|
||||||
|
|
||||||
|
def info():
|
||||||
|
"""Generate information for a bug report."""
|
||||||
|
try:
|
||||||
|
platform_info = {
|
||||||
|
"system": platform.system(),
|
||||||
|
"release": platform.release(),
|
||||||
|
}
|
||||||
|
except OSError:
|
||||||
|
platform_info = {
|
||||||
|
"system": "Unknown",
|
||||||
|
"release": "Unknown",
|
||||||
|
}
|
||||||
|
|
||||||
|
implementation_info = _implementation()
|
||||||
|
urllib3_info = {"version": urllib3.__version__}
|
||||||
|
charset_normalizer_info = {"version": None}
|
||||||
|
chardet_info = {"version": None}
|
||||||
|
if charset_normalizer:
|
||||||
|
charset_normalizer_info = {"version": charset_normalizer.__version__}
|
||||||
|
if chardet:
|
||||||
|
chardet_info = {"version": chardet.__version__}
|
||||||
|
|
||||||
|
pyopenssl_info = {
|
||||||
|
"version": None,
|
||||||
|
"openssl_version": "",
|
||||||
|
}
|
||||||
|
if OpenSSL:
|
||||||
|
pyopenssl_info = {
|
||||||
|
"version": OpenSSL.__version__,
|
||||||
|
"openssl_version": f"{OpenSSL.SSL.OPENSSL_VERSION_NUMBER:x}",
|
||||||
|
}
|
||||||
|
cryptography_info = {
|
||||||
|
"version": getattr(cryptography, "__version__", ""),
|
||||||
|
}
|
||||||
|
idna_info = {
|
||||||
|
"version": getattr(idna, "__version__", ""),
|
||||||
|
}
|
||||||
|
|
||||||
|
system_ssl = ssl.OPENSSL_VERSION_NUMBER
|
||||||
|
system_ssl_info = {"version": f"{system_ssl:x}" if system_ssl is not None else ""}
|
||||||
|
|
||||||
|
return {
|
||||||
|
"platform": platform_info,
|
||||||
|
"implementation": implementation_info,
|
||||||
|
"system_ssl": system_ssl_info,
|
||||||
|
"using_pyopenssl": pyopenssl is not None,
|
||||||
|
"using_charset_normalizer": chardet is None,
|
||||||
|
"pyOpenSSL": pyopenssl_info,
|
||||||
|
"urllib3": urllib3_info,
|
||||||
|
"chardet": chardet_info,
|
||||||
|
"charset_normalizer": charset_normalizer_info,
|
||||||
|
"cryptography": cryptography_info,
|
||||||
|
"idna": idna_info,
|
||||||
|
"requests": {
|
||||||
|
"version": requests_version,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
"""Pretty-print the bug information as JSON."""
|
||||||
|
print(json.dumps(info(), sort_keys=True, indent=2))
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
main()
|
||||||
33
venv/lib/python3.12/site-packages/requests/hooks.py
Normal file
33
venv/lib/python3.12/site-packages/requests/hooks.py
Normal file
@@ -0,0 +1,33 @@
|
|||||||
|
"""
|
||||||
|
requests.hooks
|
||||||
|
~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module provides the capabilities for the Requests hooks system.
|
||||||
|
|
||||||
|
Available hooks:
|
||||||
|
|
||||||
|
``response``:
|
||||||
|
The response generated from a Request.
|
||||||
|
"""
|
||||||
|
HOOKS = ["response"]
|
||||||
|
|
||||||
|
|
||||||
|
def default_hooks():
|
||||||
|
return {event: [] for event in HOOKS}
|
||||||
|
|
||||||
|
|
||||||
|
# TODO: response is the only one
|
||||||
|
|
||||||
|
|
||||||
|
def dispatch_hook(key, hooks, hook_data, **kwargs):
|
||||||
|
"""Dispatches a hook dictionary on a given piece of data."""
|
||||||
|
hooks = hooks or {}
|
||||||
|
hooks = hooks.get(key)
|
||||||
|
if hooks:
|
||||||
|
if hasattr(hooks, "__call__"):
|
||||||
|
hooks = [hooks]
|
||||||
|
for hook in hooks:
|
||||||
|
_hook_data = hook(hook_data, **kwargs)
|
||||||
|
if _hook_data is not None:
|
||||||
|
hook_data = _hook_data
|
||||||
|
return hook_data
|
||||||
1039
venv/lib/python3.12/site-packages/requests/models.py
Normal file
1039
venv/lib/python3.12/site-packages/requests/models.py
Normal file
File diff suppressed because it is too large
Load Diff
23
venv/lib/python3.12/site-packages/requests/packages.py
Normal file
23
venv/lib/python3.12/site-packages/requests/packages.py
Normal file
@@ -0,0 +1,23 @@
|
|||||||
|
import sys
|
||||||
|
|
||||||
|
from .compat import chardet
|
||||||
|
|
||||||
|
# This code exists for backwards compatibility reasons.
|
||||||
|
# I don't like it either. Just look the other way. :)
|
||||||
|
|
||||||
|
for package in ("urllib3", "idna"):
|
||||||
|
locals()[package] = __import__(package)
|
||||||
|
# This traversal is apparently necessary such that the identities are
|
||||||
|
# preserved (requests.packages.urllib3.* is urllib3.*)
|
||||||
|
for mod in list(sys.modules):
|
||||||
|
if mod == package or mod.startswith(f"{package}."):
|
||||||
|
sys.modules[f"requests.packages.{mod}"] = sys.modules[mod]
|
||||||
|
|
||||||
|
if chardet is not None:
|
||||||
|
target = chardet.__name__
|
||||||
|
for mod in list(sys.modules):
|
||||||
|
if mod == target or mod.startswith(f"{target}."):
|
||||||
|
imported_mod = sys.modules[mod]
|
||||||
|
sys.modules[f"requests.packages.{mod}"] = imported_mod
|
||||||
|
mod = mod.replace(target, "chardet")
|
||||||
|
sys.modules[f"requests.packages.{mod}"] = imported_mod
|
||||||
831
venv/lib/python3.12/site-packages/requests/sessions.py
Normal file
831
venv/lib/python3.12/site-packages/requests/sessions.py
Normal file
@@ -0,0 +1,831 @@
|
|||||||
|
"""
|
||||||
|
requests.sessions
|
||||||
|
~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
This module provides a Session object to manage and persist settings across
|
||||||
|
requests (cookies, auth, proxies).
|
||||||
|
"""
|
||||||
|
import os
|
||||||
|
import sys
|
||||||
|
import time
|
||||||
|
from collections import OrderedDict
|
||||||
|
from datetime import timedelta
|
||||||
|
|
||||||
|
from ._internal_utils import to_native_string
|
||||||
|
from .adapters import HTTPAdapter
|
||||||
|
from .auth import _basic_auth_str
|
||||||
|
from .compat import Mapping, cookielib, urljoin, urlparse
|
||||||
|
from .cookies import (
|
||||||
|
RequestsCookieJar,
|
||||||
|
cookiejar_from_dict,
|
||||||
|
extract_cookies_to_jar,
|
||||||
|
merge_cookies,
|
||||||
|
)
|
||||||
|
from .exceptions import (
|
||||||
|
ChunkedEncodingError,
|
||||||
|
ContentDecodingError,
|
||||||
|
InvalidSchema,
|
||||||
|
TooManyRedirects,
|
||||||
|
)
|
||||||
|
from .hooks import default_hooks, dispatch_hook
|
||||||
|
|
||||||
|
# formerly defined here, reexposed here for backward compatibility
|
||||||
|
from .models import ( # noqa: F401
|
||||||
|
DEFAULT_REDIRECT_LIMIT,
|
||||||
|
REDIRECT_STATI,
|
||||||
|
PreparedRequest,
|
||||||
|
Request,
|
||||||
|
)
|
||||||
|
from .status_codes import codes
|
||||||
|
from .structures import CaseInsensitiveDict
|
||||||
|
from .utils import ( # noqa: F401
|
||||||
|
DEFAULT_PORTS,
|
||||||
|
default_headers,
|
||||||
|
get_auth_from_url,
|
||||||
|
get_environ_proxies,
|
||||||
|
get_netrc_auth,
|
||||||
|
requote_uri,
|
||||||
|
resolve_proxies,
|
||||||
|
rewind_body,
|
||||||
|
should_bypass_proxies,
|
||||||
|
to_key_val_list,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Preferred clock, based on which one is more accurate on a given system.
|
||||||
|
if sys.platform == "win32":
|
||||||
|
preferred_clock = time.perf_counter
|
||||||
|
else:
|
||||||
|
preferred_clock = time.time
|
||||||
|
|
||||||
|
|
||||||
|
def merge_setting(request_setting, session_setting, dict_class=OrderedDict):
|
||||||
|
"""Determines appropriate setting for a given request, taking into account
|
||||||
|
the explicit setting on that request, and the setting in the session. If a
|
||||||
|
setting is a dictionary, they will be merged together using `dict_class`
|
||||||
|
"""
|
||||||
|
|
||||||
|
if session_setting is None:
|
||||||
|
return request_setting
|
||||||
|
|
||||||
|
if request_setting is None:
|
||||||
|
return session_setting
|
||||||
|
|
||||||
|
# Bypass if not a dictionary (e.g. verify)
|
||||||
|
if not (
|
||||||
|
isinstance(session_setting, Mapping) and isinstance(request_setting, Mapping)
|
||||||
|
):
|
||||||
|
return request_setting
|
||||||
|
|
||||||
|
merged_setting = dict_class(to_key_val_list(session_setting))
|
||||||
|
merged_setting.update(to_key_val_list(request_setting))
|
||||||
|
|
||||||
|
# Remove keys that are set to None. Extract keys first to avoid altering
|
||||||
|
# the dictionary during iteration.
|
||||||
|
none_keys = [k for (k, v) in merged_setting.items() if v is None]
|
||||||
|
for key in none_keys:
|
||||||
|
del merged_setting[key]
|
||||||
|
|
||||||
|
return merged_setting
|
||||||
|
|
||||||
|
|
||||||
|
def merge_hooks(request_hooks, session_hooks, dict_class=OrderedDict):
|
||||||
|
"""Properly merges both requests and session hooks.
|
||||||
|
|
||||||
|
This is necessary because when request_hooks == {'response': []}, the
|
||||||
|
merge breaks Session hooks entirely.
|
||||||
|
"""
|
||||||
|
if session_hooks is None or session_hooks.get("response") == []:
|
||||||
|
return request_hooks
|
||||||
|
|
||||||
|
if request_hooks is None or request_hooks.get("response") == []:
|
||||||
|
return session_hooks
|
||||||
|
|
||||||
|
return merge_setting(request_hooks, session_hooks, dict_class)
|
||||||
|
|
||||||
|
|
||||||
|
class SessionRedirectMixin:
|
||||||
|
def get_redirect_target(self, resp):
|
||||||
|
"""Receives a Response. Returns a redirect URI or ``None``"""
|
||||||
|
# Due to the nature of how requests processes redirects this method will
|
||||||
|
# be called at least once upon the original response and at least twice
|
||||||
|
# on each subsequent redirect response (if any).
|
||||||
|
# If a custom mixin is used to handle this logic, it may be advantageous
|
||||||
|
# to cache the redirect location onto the response object as a private
|
||||||
|
# attribute.
|
||||||
|
if resp.is_redirect:
|
||||||
|
location = resp.headers["location"]
|
||||||
|
# Currently the underlying http module on py3 decode headers
|
||||||
|
# in latin1, but empirical evidence suggests that latin1 is very
|
||||||
|
# rarely used with non-ASCII characters in HTTP headers.
|
||||||
|
# It is more likely to get UTF8 header rather than latin1.
|
||||||
|
# This causes incorrect handling of UTF8 encoded location headers.
|
||||||
|
# To solve this, we re-encode the location in latin1.
|
||||||
|
location = location.encode("latin1")
|
||||||
|
return to_native_string(location, "utf8")
|
||||||
|
return None
|
||||||
|
|
||||||
|
def should_strip_auth(self, old_url, new_url):
|
||||||
|
"""Decide whether Authorization header should be removed when redirecting"""
|
||||||
|
old_parsed = urlparse(old_url)
|
||||||
|
new_parsed = urlparse(new_url)
|
||||||
|
if old_parsed.hostname != new_parsed.hostname:
|
||||||
|
return True
|
||||||
|
# Special case: allow http -> https redirect when using the standard
|
||||||
|
# ports. This isn't specified by RFC 7235, but is kept to avoid
|
||||||
|
# breaking backwards compatibility with older versions of requests
|
||||||
|
# that allowed any redirects on the same host.
|
||||||
|
if (
|
||||||
|
old_parsed.scheme == "http"
|
||||||
|
and old_parsed.port in (80, None)
|
||||||
|
and new_parsed.scheme == "https"
|
||||||
|
and new_parsed.port in (443, None)
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Handle default port usage corresponding to scheme.
|
||||||
|
changed_port = old_parsed.port != new_parsed.port
|
||||||
|
changed_scheme = old_parsed.scheme != new_parsed.scheme
|
||||||
|
default_port = (DEFAULT_PORTS.get(old_parsed.scheme, None), None)
|
||||||
|
if (
|
||||||
|
not changed_scheme
|
||||||
|
and old_parsed.port in default_port
|
||||||
|
and new_parsed.port in default_port
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Standard case: root URI must match
|
||||||
|
return changed_port or changed_scheme
|
||||||
|
|
||||||
|
def resolve_redirects(
|
||||||
|
self,
|
||||||
|
resp,
|
||||||
|
req,
|
||||||
|
stream=False,
|
||||||
|
timeout=None,
|
||||||
|
verify=True,
|
||||||
|
cert=None,
|
||||||
|
proxies=None,
|
||||||
|
yield_requests=False,
|
||||||
|
**adapter_kwargs,
|
||||||
|
):
|
||||||
|
"""Receives a Response. Returns a generator of Responses or Requests."""
|
||||||
|
|
||||||
|
hist = [] # keep track of history
|
||||||
|
|
||||||
|
url = self.get_redirect_target(resp)
|
||||||
|
previous_fragment = urlparse(req.url).fragment
|
||||||
|
while url:
|
||||||
|
prepared_request = req.copy()
|
||||||
|
|
||||||
|
# Update history and keep track of redirects.
|
||||||
|
# resp.history must ignore the original request in this loop
|
||||||
|
hist.append(resp)
|
||||||
|
resp.history = hist[1:]
|
||||||
|
|
||||||
|
try:
|
||||||
|
resp.content # Consume socket so it can be released
|
||||||
|
except (ChunkedEncodingError, ContentDecodingError, RuntimeError):
|
||||||
|
resp.raw.read(decode_content=False)
|
||||||
|
|
||||||
|
if len(resp.history) >= self.max_redirects:
|
||||||
|
raise TooManyRedirects(
|
||||||
|
f"Exceeded {self.max_redirects} redirects.", response=resp
|
||||||
|
)
|
||||||
|
|
||||||
|
# Release the connection back into the pool.
|
||||||
|
resp.close()
|
||||||
|
|
||||||
|
# Handle redirection without scheme (see: RFC 1808 Section 4)
|
||||||
|
if url.startswith("//"):
|
||||||
|
parsed_rurl = urlparse(resp.url)
|
||||||
|
url = ":".join([to_native_string(parsed_rurl.scheme), url])
|
||||||
|
|
||||||
|
# Normalize url case and attach previous fragment if needed (RFC 7231 7.1.2)
|
||||||
|
parsed = urlparse(url)
|
||||||
|
if parsed.fragment == "" and previous_fragment:
|
||||||
|
parsed = parsed._replace(fragment=previous_fragment)
|
||||||
|
elif parsed.fragment:
|
||||||
|
previous_fragment = parsed.fragment
|
||||||
|
url = parsed.geturl()
|
||||||
|
|
||||||
|
# Facilitate relative 'location' headers, as allowed by RFC 7231.
|
||||||
|
# (e.g. '/path/to/resource' instead of 'http://domain.tld/path/to/resource')
|
||||||
|
# Compliant with RFC3986, we percent encode the url.
|
||||||
|
if not parsed.netloc:
|
||||||
|
url = urljoin(resp.url, requote_uri(url))
|
||||||
|
else:
|
||||||
|
url = requote_uri(url)
|
||||||
|
|
||||||
|
prepared_request.url = to_native_string(url)
|
||||||
|
|
||||||
|
self.rebuild_method(prepared_request, resp)
|
||||||
|
|
||||||
|
# https://github.com/psf/requests/issues/1084
|
||||||
|
if resp.status_code not in (
|
||||||
|
codes.temporary_redirect,
|
||||||
|
codes.permanent_redirect,
|
||||||
|
):
|
||||||
|
# https://github.com/psf/requests/issues/3490
|
||||||
|
purged_headers = ("Content-Length", "Content-Type", "Transfer-Encoding")
|
||||||
|
for header in purged_headers:
|
||||||
|
prepared_request.headers.pop(header, None)
|
||||||
|
prepared_request.body = None
|
||||||
|
|
||||||
|
headers = prepared_request.headers
|
||||||
|
headers.pop("Cookie", None)
|
||||||
|
|
||||||
|
# Extract any cookies sent on the response to the cookiejar
|
||||||
|
# in the new request. Because we've mutated our copied prepared
|
||||||
|
# request, use the old one that we haven't yet touched.
|
||||||
|
extract_cookies_to_jar(prepared_request._cookies, req, resp.raw)
|
||||||
|
merge_cookies(prepared_request._cookies, self.cookies)
|
||||||
|
prepared_request.prepare_cookies(prepared_request._cookies)
|
||||||
|
|
||||||
|
# Rebuild auth and proxy information.
|
||||||
|
proxies = self.rebuild_proxies(prepared_request, proxies)
|
||||||
|
self.rebuild_auth(prepared_request, resp)
|
||||||
|
|
||||||
|
# A failed tell() sets `_body_position` to `object()`. This non-None
|
||||||
|
# value ensures `rewindable` will be True, allowing us to raise an
|
||||||
|
# UnrewindableBodyError, instead of hanging the connection.
|
||||||
|
rewindable = prepared_request._body_position is not None and (
|
||||||
|
"Content-Length" in headers or "Transfer-Encoding" in headers
|
||||||
|
)
|
||||||
|
|
||||||
|
# Attempt to rewind consumed file-like object.
|
||||||
|
if rewindable:
|
||||||
|
rewind_body(prepared_request)
|
||||||
|
|
||||||
|
# Override the original request.
|
||||||
|
req = prepared_request
|
||||||
|
|
||||||
|
if yield_requests:
|
||||||
|
yield req
|
||||||
|
else:
|
||||||
|
resp = self.send(
|
||||||
|
req,
|
||||||
|
stream=stream,
|
||||||
|
timeout=timeout,
|
||||||
|
verify=verify,
|
||||||
|
cert=cert,
|
||||||
|
proxies=proxies,
|
||||||
|
allow_redirects=False,
|
||||||
|
**adapter_kwargs,
|
||||||
|
)
|
||||||
|
|
||||||
|
extract_cookies_to_jar(self.cookies, prepared_request, resp.raw)
|
||||||
|
|
||||||
|
# extract redirect url, if any, for the next loop
|
||||||
|
url = self.get_redirect_target(resp)
|
||||||
|
yield resp
|
||||||
|
|
||||||
|
def rebuild_auth(self, prepared_request, response):
|
||||||
|
"""When being redirected we may want to strip authentication from the
|
||||||
|
request to avoid leaking credentials. This method intelligently removes
|
||||||
|
and reapplies authentication where possible to avoid credential loss.
|
||||||
|
"""
|
||||||
|
headers = prepared_request.headers
|
||||||
|
url = prepared_request.url
|
||||||
|
|
||||||
|
if "Authorization" in headers and self.should_strip_auth(
|
||||||
|
response.request.url, url
|
||||||
|
):
|
||||||
|
# If we get redirected to a new host, we should strip out any
|
||||||
|
# authentication headers.
|
||||||
|
del headers["Authorization"]
|
||||||
|
|
||||||
|
# .netrc might have more auth for us on our new host.
|
||||||
|
new_auth = get_netrc_auth(url) if self.trust_env else None
|
||||||
|
if new_auth is not None:
|
||||||
|
prepared_request.prepare_auth(new_auth)
|
||||||
|
|
||||||
|
def rebuild_proxies(self, prepared_request, proxies):
|
||||||
|
"""This method re-evaluates the proxy configuration by considering the
|
||||||
|
environment variables. If we are redirected to a URL covered by
|
||||||
|
NO_PROXY, we strip the proxy configuration. Otherwise, we set missing
|
||||||
|
proxy keys for this URL (in case they were stripped by a previous
|
||||||
|
redirect).
|
||||||
|
|
||||||
|
This method also replaces the Proxy-Authorization header where
|
||||||
|
necessary.
|
||||||
|
|
||||||
|
:rtype: dict
|
||||||
|
"""
|
||||||
|
headers = prepared_request.headers
|
||||||
|
scheme = urlparse(prepared_request.url).scheme
|
||||||
|
new_proxies = resolve_proxies(prepared_request, proxies, self.trust_env)
|
||||||
|
|
||||||
|
if "Proxy-Authorization" in headers:
|
||||||
|
del headers["Proxy-Authorization"]
|
||||||
|
|
||||||
|
try:
|
||||||
|
username, password = get_auth_from_url(new_proxies[scheme])
|
||||||
|
except KeyError:
|
||||||
|
username, password = None, None
|
||||||
|
|
||||||
|
# urllib3 handles proxy authorization for us in the standard adapter.
|
||||||
|
# Avoid appending this to TLS tunneled requests where it may be leaked.
|
||||||
|
if not scheme.startswith("https") and username and password:
|
||||||
|
headers["Proxy-Authorization"] = _basic_auth_str(username, password)
|
||||||
|
|
||||||
|
return new_proxies
|
||||||
|
|
||||||
|
def rebuild_method(self, prepared_request, response):
|
||||||
|
"""When being redirected we may want to change the method of the request
|
||||||
|
based on certain specs or browser behavior.
|
||||||
|
"""
|
||||||
|
method = prepared_request.method
|
||||||
|
|
||||||
|
# https://tools.ietf.org/html/rfc7231#section-6.4.4
|
||||||
|
if response.status_code == codes.see_other and method != "HEAD":
|
||||||
|
method = "GET"
|
||||||
|
|
||||||
|
# Do what the browsers do, despite standards...
|
||||||
|
# First, turn 302s into GETs.
|
||||||
|
if response.status_code == codes.found and method != "HEAD":
|
||||||
|
method = "GET"
|
||||||
|
|
||||||
|
# Second, if a POST is responded to with a 301, turn it into a GET.
|
||||||
|
# This bizarre behaviour is explained in Issue 1704.
|
||||||
|
if response.status_code == codes.moved and method == "POST":
|
||||||
|
method = "GET"
|
||||||
|
|
||||||
|
prepared_request.method = method
|
||||||
|
|
||||||
|
|
||||||
|
class Session(SessionRedirectMixin):
|
||||||
|
"""A Requests session.
|
||||||
|
|
||||||
|
Provides cookie persistence, connection-pooling, and configuration.
|
||||||
|
|
||||||
|
Basic Usage::
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> s = requests.Session()
|
||||||
|
>>> s.get('https://httpbin.org/get')
|
||||||
|
<Response [200]>
|
||||||
|
|
||||||
|
Or as a context manager::
|
||||||
|
|
||||||
|
>>> with requests.Session() as s:
|
||||||
|
... s.get('https://httpbin.org/get')
|
||||||
|
<Response [200]>
|
||||||
|
"""
|
||||||
|
|
||||||
|
__attrs__ = [
|
||||||
|
"headers",
|
||||||
|
"cookies",
|
||||||
|
"auth",
|
||||||
|
"proxies",
|
||||||
|
"hooks",
|
||||||
|
"params",
|
||||||
|
"verify",
|
||||||
|
"cert",
|
||||||
|
"adapters",
|
||||||
|
"stream",
|
||||||
|
"trust_env",
|
||||||
|
"max_redirects",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
#: A case-insensitive dictionary of headers to be sent on each
|
||||||
|
#: :class:`Request <Request>` sent from this
|
||||||
|
#: :class:`Session <Session>`.
|
||||||
|
self.headers = default_headers()
|
||||||
|
|
||||||
|
#: Default Authentication tuple or object to attach to
|
||||||
|
#: :class:`Request <Request>`.
|
||||||
|
self.auth = None
|
||||||
|
|
||||||
|
#: Dictionary mapping protocol or protocol and host to the URL of the proxy
|
||||||
|
#: (e.g. {'http': 'foo.bar:3128', 'http://host.name': 'foo.bar:4012'}) to
|
||||||
|
#: be used on each :class:`Request <Request>`.
|
||||||
|
self.proxies = {}
|
||||||
|
|
||||||
|
#: Event-handling hooks.
|
||||||
|
self.hooks = default_hooks()
|
||||||
|
|
||||||
|
#: Dictionary of querystring data to attach to each
|
||||||
|
#: :class:`Request <Request>`. The dictionary values may be lists for
|
||||||
|
#: representing multivalued query parameters.
|
||||||
|
self.params = {}
|
||||||
|
|
||||||
|
#: Stream response content default.
|
||||||
|
self.stream = False
|
||||||
|
|
||||||
|
#: SSL Verification default.
|
||||||
|
#: Defaults to `True`, requiring requests to verify the TLS certificate at the
|
||||||
|
#: remote end.
|
||||||
|
#: If verify is set to `False`, requests will accept any TLS certificate
|
||||||
|
#: presented by the server, and will ignore hostname mismatches and/or
|
||||||
|
#: expired certificates, which will make your application vulnerable to
|
||||||
|
#: man-in-the-middle (MitM) attacks.
|
||||||
|
#: Only set this to `False` for testing.
|
||||||
|
self.verify = True
|
||||||
|
|
||||||
|
#: SSL client certificate default, if String, path to ssl client
|
||||||
|
#: cert file (.pem). If Tuple, ('cert', 'key') pair.
|
||||||
|
self.cert = None
|
||||||
|
|
||||||
|
#: Maximum number of redirects allowed. If the request exceeds this
|
||||||
|
#: limit, a :class:`TooManyRedirects` exception is raised.
|
||||||
|
#: This defaults to requests.models.DEFAULT_REDIRECT_LIMIT, which is
|
||||||
|
#: 30.
|
||||||
|
self.max_redirects = DEFAULT_REDIRECT_LIMIT
|
||||||
|
|
||||||
|
#: Trust environment settings for proxy configuration, default
|
||||||
|
#: authentication and similar.
|
||||||
|
self.trust_env = True
|
||||||
|
|
||||||
|
#: A CookieJar containing all currently outstanding cookies set on this
|
||||||
|
#: session. By default it is a
|
||||||
|
#: :class:`RequestsCookieJar <requests.cookies.RequestsCookieJar>`, but
|
||||||
|
#: may be any other ``cookielib.CookieJar`` compatible object.
|
||||||
|
self.cookies = cookiejar_from_dict({})
|
||||||
|
|
||||||
|
# Default connection adapters.
|
||||||
|
self.adapters = OrderedDict()
|
||||||
|
self.mount("https://", HTTPAdapter())
|
||||||
|
self.mount("http://", HTTPAdapter())
|
||||||
|
|
||||||
|
def __enter__(self):
|
||||||
|
return self
|
||||||
|
|
||||||
|
def __exit__(self, *args):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
def prepare_request(self, request):
|
||||||
|
"""Constructs a :class:`PreparedRequest <PreparedRequest>` for
|
||||||
|
transmission and returns it. The :class:`PreparedRequest` has settings
|
||||||
|
merged from the :class:`Request <Request>` instance and those of the
|
||||||
|
:class:`Session`.
|
||||||
|
|
||||||
|
:param request: :class:`Request` instance to prepare with this
|
||||||
|
session's settings.
|
||||||
|
:rtype: requests.PreparedRequest
|
||||||
|
"""
|
||||||
|
cookies = request.cookies or {}
|
||||||
|
|
||||||
|
# Bootstrap CookieJar.
|
||||||
|
if not isinstance(cookies, cookielib.CookieJar):
|
||||||
|
cookies = cookiejar_from_dict(cookies)
|
||||||
|
|
||||||
|
# Merge with session cookies
|
||||||
|
merged_cookies = merge_cookies(
|
||||||
|
merge_cookies(RequestsCookieJar(), self.cookies), cookies
|
||||||
|
)
|
||||||
|
|
||||||
|
# Set environment's basic authentication if not explicitly set.
|
||||||
|
auth = request.auth
|
||||||
|
if self.trust_env and not auth and not self.auth:
|
||||||
|
auth = get_netrc_auth(request.url)
|
||||||
|
|
||||||
|
p = PreparedRequest()
|
||||||
|
p.prepare(
|
||||||
|
method=request.method.upper(),
|
||||||
|
url=request.url,
|
||||||
|
files=request.files,
|
||||||
|
data=request.data,
|
||||||
|
json=request.json,
|
||||||
|
headers=merge_setting(
|
||||||
|
request.headers, self.headers, dict_class=CaseInsensitiveDict
|
||||||
|
),
|
||||||
|
params=merge_setting(request.params, self.params),
|
||||||
|
auth=merge_setting(auth, self.auth),
|
||||||
|
cookies=merged_cookies,
|
||||||
|
hooks=merge_hooks(request.hooks, self.hooks),
|
||||||
|
)
|
||||||
|
return p
|
||||||
|
|
||||||
|
def request(
|
||||||
|
self,
|
||||||
|
method,
|
||||||
|
url,
|
||||||
|
params=None,
|
||||||
|
data=None,
|
||||||
|
headers=None,
|
||||||
|
cookies=None,
|
||||||
|
files=None,
|
||||||
|
auth=None,
|
||||||
|
timeout=None,
|
||||||
|
allow_redirects=True,
|
||||||
|
proxies=None,
|
||||||
|
hooks=None,
|
||||||
|
stream=None,
|
||||||
|
verify=None,
|
||||||
|
cert=None,
|
||||||
|
json=None,
|
||||||
|
):
|
||||||
|
"""Constructs a :class:`Request <Request>`, prepares it and sends it.
|
||||||
|
Returns :class:`Response <Response>` object.
|
||||||
|
|
||||||
|
:param method: method for the new :class:`Request` object.
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param params: (optional) Dictionary or bytes to be sent in the query
|
||||||
|
string for the :class:`Request`.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) json to send in the body of the
|
||||||
|
:class:`Request`.
|
||||||
|
:param headers: (optional) Dictionary of HTTP Headers to send with the
|
||||||
|
:class:`Request`.
|
||||||
|
:param cookies: (optional) Dict or CookieJar object to send with the
|
||||||
|
:class:`Request`.
|
||||||
|
:param files: (optional) Dictionary of ``'filename': file-like-objects``
|
||||||
|
for multipart encoding upload.
|
||||||
|
:param auth: (optional) Auth tuple or callable to enable
|
||||||
|
Basic/Digest/Custom HTTP Auth.
|
||||||
|
:param timeout: (optional) How many seconds to wait for the server to send
|
||||||
|
data before giving up, as a float, or a :ref:`(connect timeout,
|
||||||
|
read timeout) <timeouts>` tuple.
|
||||||
|
:type timeout: float or tuple
|
||||||
|
:param allow_redirects: (optional) Set to True by default.
|
||||||
|
:type allow_redirects: bool
|
||||||
|
:param proxies: (optional) Dictionary mapping protocol or protocol and
|
||||||
|
hostname to the URL of the proxy.
|
||||||
|
:param hooks: (optional) Dictionary mapping hook name to one event or
|
||||||
|
list of events, event must be callable.
|
||||||
|
:param stream: (optional) whether to immediately download the response
|
||||||
|
content. Defaults to ``False``.
|
||||||
|
:param verify: (optional) Either a boolean, in which case it controls whether we verify
|
||||||
|
the server's TLS certificate, or a string, in which case it must be a path
|
||||||
|
to a CA bundle to use. Defaults to ``True``. When set to
|
||||||
|
``False``, requests will accept any TLS certificate presented by
|
||||||
|
the server, and will ignore hostname mismatches and/or expired
|
||||||
|
certificates, which will make your application vulnerable to
|
||||||
|
man-in-the-middle (MitM) attacks. Setting verify to ``False``
|
||||||
|
may be useful during local development or testing.
|
||||||
|
:param cert: (optional) if String, path to ssl client cert file (.pem).
|
||||||
|
If Tuple, ('cert', 'key') pair.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
# Create the Request.
|
||||||
|
req = Request(
|
||||||
|
method=method.upper(),
|
||||||
|
url=url,
|
||||||
|
headers=headers,
|
||||||
|
files=files,
|
||||||
|
data=data or {},
|
||||||
|
json=json,
|
||||||
|
params=params or {},
|
||||||
|
auth=auth,
|
||||||
|
cookies=cookies,
|
||||||
|
hooks=hooks,
|
||||||
|
)
|
||||||
|
prep = self.prepare_request(req)
|
||||||
|
|
||||||
|
proxies = proxies or {}
|
||||||
|
|
||||||
|
settings = self.merge_environment_settings(
|
||||||
|
prep.url, proxies, stream, verify, cert
|
||||||
|
)
|
||||||
|
|
||||||
|
# Send the request.
|
||||||
|
send_kwargs = {
|
||||||
|
"timeout": timeout,
|
||||||
|
"allow_redirects": allow_redirects,
|
||||||
|
}
|
||||||
|
send_kwargs.update(settings)
|
||||||
|
resp = self.send(prep, **send_kwargs)
|
||||||
|
|
||||||
|
return resp
|
||||||
|
|
||||||
|
def get(self, url, **kwargs):
|
||||||
|
r"""Sends a GET request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
kwargs.setdefault("allow_redirects", True)
|
||||||
|
return self.request("GET", url, **kwargs)
|
||||||
|
|
||||||
|
def options(self, url, **kwargs):
|
||||||
|
r"""Sends a OPTIONS request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
kwargs.setdefault("allow_redirects", True)
|
||||||
|
return self.request("OPTIONS", url, **kwargs)
|
||||||
|
|
||||||
|
def head(self, url, **kwargs):
|
||||||
|
r"""Sends a HEAD request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
kwargs.setdefault("allow_redirects", False)
|
||||||
|
return self.request("HEAD", url, **kwargs)
|
||||||
|
|
||||||
|
def post(self, url, data=None, json=None, **kwargs):
|
||||||
|
r"""Sends a POST request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param json: (optional) json to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.request("POST", url, data=data, json=json, **kwargs)
|
||||||
|
|
||||||
|
def put(self, url, data=None, **kwargs):
|
||||||
|
r"""Sends a PUT request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.request("PUT", url, data=data, **kwargs)
|
||||||
|
|
||||||
|
def patch(self, url, data=None, **kwargs):
|
||||||
|
r"""Sends a PATCH request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param data: (optional) Dictionary, list of tuples, bytes, or file-like
|
||||||
|
object to send in the body of the :class:`Request`.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.request("PATCH", url, data=data, **kwargs)
|
||||||
|
|
||||||
|
def delete(self, url, **kwargs):
|
||||||
|
r"""Sends a DELETE request. Returns :class:`Response` object.
|
||||||
|
|
||||||
|
:param url: URL for the new :class:`Request` object.
|
||||||
|
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
|
||||||
|
return self.request("DELETE", url, **kwargs)
|
||||||
|
|
||||||
|
def send(self, request, **kwargs):
|
||||||
|
"""Send a given PreparedRequest.
|
||||||
|
|
||||||
|
:rtype: requests.Response
|
||||||
|
"""
|
||||||
|
# Set defaults that the hooks can utilize to ensure they always have
|
||||||
|
# the correct parameters to reproduce the previous request.
|
||||||
|
kwargs.setdefault("stream", self.stream)
|
||||||
|
kwargs.setdefault("verify", self.verify)
|
||||||
|
kwargs.setdefault("cert", self.cert)
|
||||||
|
if "proxies" not in kwargs:
|
||||||
|
kwargs["proxies"] = resolve_proxies(request, self.proxies, self.trust_env)
|
||||||
|
|
||||||
|
# It's possible that users might accidentally send a Request object.
|
||||||
|
# Guard against that specific failure case.
|
||||||
|
if isinstance(request, Request):
|
||||||
|
raise ValueError("You can only send PreparedRequests.")
|
||||||
|
|
||||||
|
# Set up variables needed for resolve_redirects and dispatching of hooks
|
||||||
|
allow_redirects = kwargs.pop("allow_redirects", True)
|
||||||
|
stream = kwargs.get("stream")
|
||||||
|
hooks = request.hooks
|
||||||
|
|
||||||
|
# Get the appropriate adapter to use
|
||||||
|
adapter = self.get_adapter(url=request.url)
|
||||||
|
|
||||||
|
# Start time (approximately) of the request
|
||||||
|
start = preferred_clock()
|
||||||
|
|
||||||
|
# Send the request
|
||||||
|
r = adapter.send(request, **kwargs)
|
||||||
|
|
||||||
|
# Total elapsed time of the request (approximately)
|
||||||
|
elapsed = preferred_clock() - start
|
||||||
|
r.elapsed = timedelta(seconds=elapsed)
|
||||||
|
|
||||||
|
# Response manipulation hooks
|
||||||
|
r = dispatch_hook("response", hooks, r, **kwargs)
|
||||||
|
|
||||||
|
# Persist cookies
|
||||||
|
if r.history:
|
||||||
|
# If the hooks create history then we want those cookies too
|
||||||
|
for resp in r.history:
|
||||||
|
extract_cookies_to_jar(self.cookies, resp.request, resp.raw)
|
||||||
|
|
||||||
|
extract_cookies_to_jar(self.cookies, request, r.raw)
|
||||||
|
|
||||||
|
# Resolve redirects if allowed.
|
||||||
|
if allow_redirects:
|
||||||
|
# Redirect resolving generator.
|
||||||
|
gen = self.resolve_redirects(r, request, **kwargs)
|
||||||
|
history = [resp for resp in gen]
|
||||||
|
else:
|
||||||
|
history = []
|
||||||
|
|
||||||
|
# Shuffle things around if there's history.
|
||||||
|
if history:
|
||||||
|
# Insert the first (original) request at the start
|
||||||
|
history.insert(0, r)
|
||||||
|
# Get the last request made
|
||||||
|
r = history.pop()
|
||||||
|
r.history = history
|
||||||
|
|
||||||
|
# If redirects aren't being followed, store the response on the Request for Response.next().
|
||||||
|
if not allow_redirects:
|
||||||
|
try:
|
||||||
|
r._next = next(
|
||||||
|
self.resolve_redirects(r, request, yield_requests=True, **kwargs)
|
||||||
|
)
|
||||||
|
except StopIteration:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if not stream:
|
||||||
|
r.content
|
||||||
|
|
||||||
|
return r
|
||||||
|
|
||||||
|
def merge_environment_settings(self, url, proxies, stream, verify, cert):
|
||||||
|
"""
|
||||||
|
Check the environment and merge it with some settings.
|
||||||
|
|
||||||
|
:rtype: dict
|
||||||
|
"""
|
||||||
|
# Gather clues from the surrounding environment.
|
||||||
|
if self.trust_env:
|
||||||
|
# Set environment's proxies.
|
||||||
|
no_proxy = proxies.get("no_proxy") if proxies is not None else None
|
||||||
|
env_proxies = get_environ_proxies(url, no_proxy=no_proxy)
|
||||||
|
for k, v in env_proxies.items():
|
||||||
|
proxies.setdefault(k, v)
|
||||||
|
|
||||||
|
# Look for requests environment configuration
|
||||||
|
# and be compatible with cURL.
|
||||||
|
if verify is True or verify is None:
|
||||||
|
verify = (
|
||||||
|
os.environ.get("REQUESTS_CA_BUNDLE")
|
||||||
|
or os.environ.get("CURL_CA_BUNDLE")
|
||||||
|
or verify
|
||||||
|
)
|
||||||
|
|
||||||
|
# Merge all the kwargs.
|
||||||
|
proxies = merge_setting(proxies, self.proxies)
|
||||||
|
stream = merge_setting(stream, self.stream)
|
||||||
|
verify = merge_setting(verify, self.verify)
|
||||||
|
cert = merge_setting(cert, self.cert)
|
||||||
|
|
||||||
|
return {"proxies": proxies, "stream": stream, "verify": verify, "cert": cert}
|
||||||
|
|
||||||
|
def get_adapter(self, url):
|
||||||
|
"""
|
||||||
|
Returns the appropriate connection adapter for the given URL.
|
||||||
|
|
||||||
|
:rtype: requests.adapters.BaseAdapter
|
||||||
|
"""
|
||||||
|
for prefix, adapter in self.adapters.items():
|
||||||
|
if url.lower().startswith(prefix.lower()):
|
||||||
|
return adapter
|
||||||
|
|
||||||
|
# Nothing matches :-/
|
||||||
|
raise InvalidSchema(f"No connection adapters were found for {url!r}")
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
"""Closes all adapters and as such the session"""
|
||||||
|
for v in self.adapters.values():
|
||||||
|
v.close()
|
||||||
|
|
||||||
|
def mount(self, prefix, adapter):
|
||||||
|
"""Registers a connection adapter to a prefix.
|
||||||
|
|
||||||
|
Adapters are sorted in descending order by prefix length.
|
||||||
|
"""
|
||||||
|
self.adapters[prefix] = adapter
|
||||||
|
keys_to_move = [k for k in self.adapters if len(k) < len(prefix)]
|
||||||
|
|
||||||
|
for key in keys_to_move:
|
||||||
|
self.adapters[key] = self.adapters.pop(key)
|
||||||
|
|
||||||
|
def __getstate__(self):
|
||||||
|
state = {attr: getattr(self, attr, None) for attr in self.__attrs__}
|
||||||
|
return state
|
||||||
|
|
||||||
|
def __setstate__(self, state):
|
||||||
|
for attr, value in state.items():
|
||||||
|
setattr(self, attr, value)
|
||||||
|
|
||||||
|
|
||||||
|
def session():
|
||||||
|
"""
|
||||||
|
Returns a :class:`Session` for context-management.
|
||||||
|
|
||||||
|
.. deprecated:: 1.0.0
|
||||||
|
|
||||||
|
This method has been deprecated since version 1.0.0 and is only kept for
|
||||||
|
backwards compatibility. New code should use :class:`~requests.sessions.Session`
|
||||||
|
to create a session. This may be removed at a future date.
|
||||||
|
|
||||||
|
:rtype: Session
|
||||||
|
"""
|
||||||
|
return Session()
|
||||||
128
venv/lib/python3.12/site-packages/requests/status_codes.py
Normal file
128
venv/lib/python3.12/site-packages/requests/status_codes.py
Normal file
@@ -0,0 +1,128 @@
|
|||||||
|
r"""
|
||||||
|
The ``codes`` object defines a mapping from common names for HTTP statuses
|
||||||
|
to their numerical codes, accessible either as attributes or as dictionary
|
||||||
|
items.
|
||||||
|
|
||||||
|
Example::
|
||||||
|
|
||||||
|
>>> import requests
|
||||||
|
>>> requests.codes['temporary_redirect']
|
||||||
|
307
|
||||||
|
>>> requests.codes.teapot
|
||||||
|
418
|
||||||
|
>>> requests.codes['\o/']
|
||||||
|
200
|
||||||
|
|
||||||
|
Some codes have multiple names, and both upper- and lower-case versions of
|
||||||
|
the names are allowed. For example, ``codes.ok``, ``codes.OK``, and
|
||||||
|
``codes.okay`` all correspond to the HTTP status code 200.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from .structures import LookupDict
|
||||||
|
|
||||||
|
_codes = {
|
||||||
|
# Informational.
|
||||||
|
100: ("continue",),
|
||||||
|
101: ("switching_protocols",),
|
||||||
|
102: ("processing", "early-hints"),
|
||||||
|
103: ("checkpoint",),
|
||||||
|
122: ("uri_too_long", "request_uri_too_long"),
|
||||||
|
200: ("ok", "okay", "all_ok", "all_okay", "all_good", "\\o/", "✓"),
|
||||||
|
201: ("created",),
|
||||||
|
202: ("accepted",),
|
||||||
|
203: ("non_authoritative_info", "non_authoritative_information"),
|
||||||
|
204: ("no_content",),
|
||||||
|
205: ("reset_content", "reset"),
|
||||||
|
206: ("partial_content", "partial"),
|
||||||
|
207: ("multi_status", "multiple_status", "multi_stati", "multiple_stati"),
|
||||||
|
208: ("already_reported",),
|
||||||
|
226: ("im_used",),
|
||||||
|
# Redirection.
|
||||||
|
300: ("multiple_choices",),
|
||||||
|
301: ("moved_permanently", "moved", "\\o-"),
|
||||||
|
302: ("found",),
|
||||||
|
303: ("see_other", "other"),
|
||||||
|
304: ("not_modified",),
|
||||||
|
305: ("use_proxy",),
|
||||||
|
306: ("switch_proxy",),
|
||||||
|
307: ("temporary_redirect", "temporary_moved", "temporary"),
|
||||||
|
308: (
|
||||||
|
"permanent_redirect",
|
||||||
|
"resume_incomplete",
|
||||||
|
"resume",
|
||||||
|
), # "resume" and "resume_incomplete" to be removed in 3.0
|
||||||
|
# Client Error.
|
||||||
|
400: ("bad_request", "bad"),
|
||||||
|
401: ("unauthorized",),
|
||||||
|
402: ("payment_required", "payment"),
|
||||||
|
403: ("forbidden",),
|
||||||
|
404: ("not_found", "-o-"),
|
||||||
|
405: ("method_not_allowed", "not_allowed"),
|
||||||
|
406: ("not_acceptable",),
|
||||||
|
407: ("proxy_authentication_required", "proxy_auth", "proxy_authentication"),
|
||||||
|
408: ("request_timeout", "timeout"),
|
||||||
|
409: ("conflict",),
|
||||||
|
410: ("gone",),
|
||||||
|
411: ("length_required",),
|
||||||
|
412: ("precondition_failed", "precondition"),
|
||||||
|
413: ("request_entity_too_large", "content_too_large"),
|
||||||
|
414: ("request_uri_too_large", "uri_too_long"),
|
||||||
|
415: ("unsupported_media_type", "unsupported_media", "media_type"),
|
||||||
|
416: (
|
||||||
|
"requested_range_not_satisfiable",
|
||||||
|
"requested_range",
|
||||||
|
"range_not_satisfiable",
|
||||||
|
),
|
||||||
|
417: ("expectation_failed",),
|
||||||
|
418: ("im_a_teapot", "teapot", "i_am_a_teapot"),
|
||||||
|
421: ("misdirected_request",),
|
||||||
|
422: ("unprocessable_entity", "unprocessable", "unprocessable_content"),
|
||||||
|
423: ("locked",),
|
||||||
|
424: ("failed_dependency", "dependency"),
|
||||||
|
425: ("unordered_collection", "unordered", "too_early"),
|
||||||
|
426: ("upgrade_required", "upgrade"),
|
||||||
|
428: ("precondition_required", "precondition"),
|
||||||
|
429: ("too_many_requests", "too_many"),
|
||||||
|
431: ("header_fields_too_large", "fields_too_large"),
|
||||||
|
444: ("no_response", "none"),
|
||||||
|
449: ("retry_with", "retry"),
|
||||||
|
450: ("blocked_by_windows_parental_controls", "parental_controls"),
|
||||||
|
451: ("unavailable_for_legal_reasons", "legal_reasons"),
|
||||||
|
499: ("client_closed_request",),
|
||||||
|
# Server Error.
|
||||||
|
500: ("internal_server_error", "server_error", "/o\\", "✗"),
|
||||||
|
501: ("not_implemented",),
|
||||||
|
502: ("bad_gateway",),
|
||||||
|
503: ("service_unavailable", "unavailable"),
|
||||||
|
504: ("gateway_timeout",),
|
||||||
|
505: ("http_version_not_supported", "http_version"),
|
||||||
|
506: ("variant_also_negotiates",),
|
||||||
|
507: ("insufficient_storage",),
|
||||||
|
509: ("bandwidth_limit_exceeded", "bandwidth"),
|
||||||
|
510: ("not_extended",),
|
||||||
|
511: ("network_authentication_required", "network_auth", "network_authentication"),
|
||||||
|
}
|
||||||
|
|
||||||
|
codes = LookupDict(name="status_codes")
|
||||||
|
|
||||||
|
|
||||||
|
def _init():
|
||||||
|
for code, titles in _codes.items():
|
||||||
|
for title in titles:
|
||||||
|
setattr(codes, title, code)
|
||||||
|
if not title.startswith(("\\", "/")):
|
||||||
|
setattr(codes, title.upper(), code)
|
||||||
|
|
||||||
|
def doc(code):
|
||||||
|
names = ", ".join(f"``{n}``" for n in _codes[code])
|
||||||
|
return "* %d: %s" % (code, names)
|
||||||
|
|
||||||
|
global __doc__
|
||||||
|
__doc__ = (
|
||||||
|
__doc__ + "\n" + "\n".join(doc(code) for code in sorted(_codes))
|
||||||
|
if __doc__ is not None
|
||||||
|
else None
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
_init()
|
||||||
99
venv/lib/python3.12/site-packages/requests/structures.py
Normal file
99
venv/lib/python3.12/site-packages/requests/structures.py
Normal file
@@ -0,0 +1,99 @@
|
|||||||
|
"""
|
||||||
|
requests.structures
|
||||||
|
~~~~~~~~~~~~~~~~~~~
|
||||||
|
|
||||||
|
Data structures that power Requests.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from collections import OrderedDict
|
||||||
|
|
||||||
|
from .compat import Mapping, MutableMapping
|
||||||
|
|
||||||
|
|
||||||
|
class CaseInsensitiveDict(MutableMapping):
|
||||||
|
"""A case-insensitive ``dict``-like object.
|
||||||
|
|
||||||
|
Implements all methods and operations of
|
||||||
|
``MutableMapping`` as well as dict's ``copy``. Also
|
||||||
|
provides ``lower_items``.
|
||||||
|
|
||||||
|
All keys are expected to be strings. The structure remembers the
|
||||||
|
case of the last key to be set, and ``iter(instance)``,
|
||||||
|
``keys()``, ``items()``, ``iterkeys()``, and ``iteritems()``
|
||||||
|
will contain case-sensitive keys. However, querying and contains
|
||||||
|
testing is case insensitive::
|
||||||
|
|
||||||
|
cid = CaseInsensitiveDict()
|
||||||
|
cid['Accept'] = 'application/json'
|
||||||
|
cid['aCCEPT'] == 'application/json' # True
|
||||||
|
list(cid) == ['Accept'] # True
|
||||||
|
|
||||||
|
For example, ``headers['content-encoding']`` will return the
|
||||||
|
value of a ``'Content-Encoding'`` response header, regardless
|
||||||
|
of how the header name was originally stored.
|
||||||
|
|
||||||
|
If the constructor, ``.update``, or equality comparison
|
||||||
|
operations are given keys that have equal ``.lower()``s, the
|
||||||
|
behavior is undefined.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, data=None, **kwargs):
|
||||||
|
self._store = OrderedDict()
|
||||||
|
if data is None:
|
||||||
|
data = {}
|
||||||
|
self.update(data, **kwargs)
|
||||||
|
|
||||||
|
def __setitem__(self, key, value):
|
||||||
|
# Use the lowercased key for lookups, but store the actual
|
||||||
|
# key alongside the value.
|
||||||
|
self._store[key.lower()] = (key, value)
|
||||||
|
|
||||||
|
def __getitem__(self, key):
|
||||||
|
return self._store[key.lower()][1]
|
||||||
|
|
||||||
|
def __delitem__(self, key):
|
||||||
|
del self._store[key.lower()]
|
||||||
|
|
||||||
|
def __iter__(self):
|
||||||
|
return (casedkey for casedkey, mappedvalue in self._store.values())
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return len(self._store)
|
||||||
|
|
||||||
|
def lower_items(self):
|
||||||
|
"""Like iteritems(), but with all lowercase keys."""
|
||||||
|
return ((lowerkey, keyval[1]) for (lowerkey, keyval) in self._store.items())
|
||||||
|
|
||||||
|
def __eq__(self, other):
|
||||||
|
if isinstance(other, Mapping):
|
||||||
|
other = CaseInsensitiveDict(other)
|
||||||
|
else:
|
||||||
|
return NotImplemented
|
||||||
|
# Compare insensitively
|
||||||
|
return dict(self.lower_items()) == dict(other.lower_items())
|
||||||
|
|
||||||
|
# Copy is required
|
||||||
|
def copy(self):
|
||||||
|
return CaseInsensitiveDict(self._store.values())
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return str(dict(self.items()))
|
||||||
|
|
||||||
|
|
||||||
|
class LookupDict(dict):
|
||||||
|
"""Dictionary lookup object."""
|
||||||
|
|
||||||
|
def __init__(self, name=None):
|
||||||
|
self.name = name
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
def __repr__(self):
|
||||||
|
return f"<lookup '{self.name}'>"
|
||||||
|
|
||||||
|
def __getitem__(self, key):
|
||||||
|
# We allow fall-through here, so values default to None
|
||||||
|
|
||||||
|
return self.__dict__.get(key, None)
|
||||||
|
|
||||||
|
def get(self, key, default=None):
|
||||||
|
return self.__dict__.get(key, default)
|
||||||
1086
venv/lib/python3.12/site-packages/requests/utils.py
Normal file
1086
venv/lib/python3.12/site-packages/requests/utils.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1 @@
|
|||||||
|
pip
|
||||||
@@ -0,0 +1,154 @@
|
|||||||
|
Metadata-Version: 2.4
|
||||||
|
Name: urllib3
|
||||||
|
Version: 2.5.0
|
||||||
|
Summary: HTTP library with thread-safe connection pooling, file post, and more.
|
||||||
|
Project-URL: Changelog, https://github.com/urllib3/urllib3/blob/main/CHANGES.rst
|
||||||
|
Project-URL: Documentation, https://urllib3.readthedocs.io
|
||||||
|
Project-URL: Code, https://github.com/urllib3/urllib3
|
||||||
|
Project-URL: Issue tracker, https://github.com/urllib3/urllib3/issues
|
||||||
|
Author-email: Andrey Petrov <andrey.petrov@shazow.net>
|
||||||
|
Maintainer-email: Seth Michael Larson <sethmichaellarson@gmail.com>, Quentin Pradet <quentin@pradet.me>, Illia Volochii <illia.volochii@gmail.com>
|
||||||
|
License-Expression: MIT
|
||||||
|
License-File: LICENSE.txt
|
||||||
|
Keywords: filepost,http,httplib,https,pooling,ssl,threadsafe,urllib
|
||||||
|
Classifier: Environment :: Web Environment
|
||||||
|
Classifier: Intended Audience :: Developers
|
||||||
|
Classifier: Operating System :: OS Independent
|
||||||
|
Classifier: Programming Language :: Python
|
||||||
|
Classifier: Programming Language :: Python :: 3
|
||||||
|
Classifier: Programming Language :: Python :: 3 :: Only
|
||||||
|
Classifier: Programming Language :: Python :: 3.9
|
||||||
|
Classifier: Programming Language :: Python :: 3.10
|
||||||
|
Classifier: Programming Language :: Python :: 3.11
|
||||||
|
Classifier: Programming Language :: Python :: 3.12
|
||||||
|
Classifier: Programming Language :: Python :: 3.13
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: CPython
|
||||||
|
Classifier: Programming Language :: Python :: Implementation :: PyPy
|
||||||
|
Classifier: Topic :: Internet :: WWW/HTTP
|
||||||
|
Classifier: Topic :: Software Development :: Libraries
|
||||||
|
Requires-Python: >=3.9
|
||||||
|
Provides-Extra: brotli
|
||||||
|
Requires-Dist: brotli>=1.0.9; (platform_python_implementation == 'CPython') and extra == 'brotli'
|
||||||
|
Requires-Dist: brotlicffi>=0.8.0; (platform_python_implementation != 'CPython') and extra == 'brotli'
|
||||||
|
Provides-Extra: h2
|
||||||
|
Requires-Dist: h2<5,>=4; extra == 'h2'
|
||||||
|
Provides-Extra: socks
|
||||||
|
Requires-Dist: pysocks!=1.5.7,<2.0,>=1.5.6; extra == 'socks'
|
||||||
|
Provides-Extra: zstd
|
||||||
|
Requires-Dist: zstandard>=0.18.0; extra == 'zstd'
|
||||||
|
Description-Content-Type: text/markdown
|
||||||
|
|
||||||
|
<h1 align="center">
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
</h1>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://pypi.org/project/urllib3"><img alt="PyPI Version" src="https://img.shields.io/pypi/v/urllib3.svg?maxAge=86400" /></a>
|
||||||
|
<a href="https://pypi.org/project/urllib3"><img alt="Python Versions" src="https://img.shields.io/pypi/pyversions/urllib3.svg?maxAge=86400" /></a>
|
||||||
|
<a href="https://discord.gg/urllib3"><img alt="Join our Discord" src="https://img.shields.io/discord/756342717725933608?color=%237289da&label=discord" /></a>
|
||||||
|
<a href="https://github.com/urllib3/urllib3/actions?query=workflow%3ACI"><img alt="Coverage Status" src="https://img.shields.io/badge/coverage-100%25-success" /></a>
|
||||||
|
<a href="https://github.com/urllib3/urllib3/actions/workflows/ci.yml?query=branch%3Amain"><img alt="Build Status on GitHub" src="https://github.com/urllib3/urllib3/actions/workflows/ci.yml/badge.svg?branch:main&workflow:CI" /></a>
|
||||||
|
<a href="https://urllib3.readthedocs.io"><img alt="Documentation Status" src="https://readthedocs.org/projects/urllib3/badge/?version=latest" /></a><br>
|
||||||
|
<a href="https://deps.dev/pypi/urllib3"><img alt="OpenSSF Scorecard" src="https://api.securityscorecards.dev/projects/github.com/urllib3/urllib3/badge" /></a>
|
||||||
|
<a href="https://slsa.dev"><img alt="SLSA 3" src="https://slsa.dev/images/gh-badge-level3.svg" /></a>
|
||||||
|
<a href="https://bestpractices.coreinfrastructure.org/projects/6227"><img alt="CII Best Practices" src="https://bestpractices.coreinfrastructure.org/projects/6227/badge" /></a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
urllib3 is a powerful, *user-friendly* HTTP client for Python. Much of the
|
||||||
|
Python ecosystem already uses urllib3 and you should too.
|
||||||
|
urllib3 brings many critical features that are missing from the Python
|
||||||
|
standard libraries:
|
||||||
|
|
||||||
|
- Thread safety.
|
||||||
|
- Connection pooling.
|
||||||
|
- Client-side SSL/TLS verification.
|
||||||
|
- File uploads with multipart encoding.
|
||||||
|
- Helpers for retrying requests and dealing with HTTP redirects.
|
||||||
|
- Support for gzip, deflate, brotli, and zstd encoding.
|
||||||
|
- Proxy support for HTTP and SOCKS.
|
||||||
|
- 100% test coverage.
|
||||||
|
|
||||||
|
urllib3 is powerful and easy to use:
|
||||||
|
|
||||||
|
```python3
|
||||||
|
>>> import urllib3
|
||||||
|
>>> resp = urllib3.request("GET", "http://httpbin.org/robots.txt")
|
||||||
|
>>> resp.status
|
||||||
|
200
|
||||||
|
>>> resp.data
|
||||||
|
b"User-agent: *\nDisallow: /deny\n"
|
||||||
|
```
|
||||||
|
|
||||||
|
## Installing
|
||||||
|
|
||||||
|
urllib3 can be installed with [pip](https://pip.pypa.io):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ python -m pip install urllib3
|
||||||
|
```
|
||||||
|
|
||||||
|
Alternatively, you can grab the latest source code from [GitHub](https://github.com/urllib3/urllib3):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ git clone https://github.com/urllib3/urllib3.git
|
||||||
|
$ cd urllib3
|
||||||
|
$ pip install .
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Documentation
|
||||||
|
|
||||||
|
urllib3 has usage and reference documentation at [urllib3.readthedocs.io](https://urllib3.readthedocs.io).
|
||||||
|
|
||||||
|
|
||||||
|
## Community
|
||||||
|
|
||||||
|
urllib3 has a [community Discord channel](https://discord.gg/urllib3) for asking questions and
|
||||||
|
collaborating with other contributors. Drop by and say hello 👋
|
||||||
|
|
||||||
|
|
||||||
|
## Contributing
|
||||||
|
|
||||||
|
urllib3 happily accepts contributions. Please see our
|
||||||
|
[contributing documentation](https://urllib3.readthedocs.io/en/latest/contributing.html)
|
||||||
|
for some tips on getting started.
|
||||||
|
|
||||||
|
|
||||||
|
## Security Disclosures
|
||||||
|
|
||||||
|
To report a security vulnerability, please use the
|
||||||
|
[Tidelift security contact](https://tidelift.com/security).
|
||||||
|
Tidelift will coordinate the fix and disclosure with maintainers.
|
||||||
|
|
||||||
|
|
||||||
|
## Maintainers
|
||||||
|
|
||||||
|
- [@sethmlarson](https://github.com/sethmlarson) (Seth M. Larson)
|
||||||
|
- [@pquentin](https://github.com/pquentin) (Quentin Pradet)
|
||||||
|
- [@illia-v](https://github.com/illia-v) (Illia Volochii)
|
||||||
|
- [@theacodes](https://github.com/theacodes) (Thea Flowers)
|
||||||
|
- [@haikuginger](https://github.com/haikuginger) (Jess Shapiro)
|
||||||
|
- [@lukasa](https://github.com/lukasa) (Cory Benfield)
|
||||||
|
- [@sigmavirus24](https://github.com/sigmavirus24) (Ian Stapleton Cordasco)
|
||||||
|
- [@shazow](https://github.com/shazow) (Andrey Petrov)
|
||||||
|
|
||||||
|
👋
|
||||||
|
|
||||||
|
|
||||||
|
## Sponsorship
|
||||||
|
|
||||||
|
If your company benefits from this library, please consider [sponsoring its
|
||||||
|
development](https://urllib3.readthedocs.io/en/latest/sponsors.html).
|
||||||
|
|
||||||
|
|
||||||
|
## For Enterprise
|
||||||
|
|
||||||
|
Professional support for urllib3 is available as part of the [Tidelift
|
||||||
|
Subscription][1]. Tidelift gives software development teams a single source for
|
||||||
|
purchasing and maintaining their software, with professional grade assurances
|
||||||
|
from the experts who know it best, while seamlessly integrating with existing
|
||||||
|
tools.
|
||||||
|
|
||||||
|
[1]: https://tidelift.com/subscription/pkg/pypi-urllib3?utm_source=pypi-urllib3&utm_medium=referral&utm_campaign=readme
|
||||||
@@ -0,0 +1,79 @@
|
|||||||
|
urllib3-2.5.0.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
|
||||||
|
urllib3-2.5.0.dist-info/METADATA,sha256=maYkTIZt0a-lkEC-hMZWbCBmcGZyJcYOeRk4_nuTrNc,6461
|
||||||
|
urllib3-2.5.0.dist-info/RECORD,,
|
||||||
|
urllib3-2.5.0.dist-info/WHEEL,sha256=qtCwoSJWgHk21S1Kb4ihdzI2rlJ1ZKaIurTj_ngOhyQ,87
|
||||||
|
urllib3-2.5.0.dist-info/licenses/LICENSE.txt,sha256=Ew46ZNX91dCWp1JpRjSn2d8oRGnehuVzIQAmgEHj1oY,1093
|
||||||
|
urllib3/__init__.py,sha256=JMo1tg1nIV1AeJ2vENC_Txfl0e5h6Gzl9DGVk1rWRbo,6979
|
||||||
|
urllib3/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/_base_connection.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/_collections.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/_request_methods.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/_version.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/connection.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/connectionpool.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/exceptions.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/fields.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/filepost.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/poolmanager.cpython-312.pyc,,
|
||||||
|
urllib3/__pycache__/response.cpython-312.pyc,,
|
||||||
|
urllib3/_base_connection.py,sha256=T1cwH3RhzsrBh6Bz3AOGVDboRsE7veijqZPXXQTR2Rg,5568
|
||||||
|
urllib3/_collections.py,sha256=tM7c6J1iKtWZYV_QGYb8-r7Nr1524Dehnsa0Ufh6_mU,17295
|
||||||
|
urllib3/_request_methods.py,sha256=gCeF85SO_UU4WoPwYHIoz_tw-eM_EVOkLFp8OFsC7DA,9931
|
||||||
|
urllib3/_version.py,sha256=ZlSUkBo_Pd90B6pM0GDO7l2vitQD3QCK3xPR_K0zFJA,511
|
||||||
|
urllib3/connection.py,sha256=iP4pgSJtpusXyYlejzNn-gih_wWCxMU-qy6OU1kaapc,42613
|
||||||
|
urllib3/connectionpool.py,sha256=ZEhudsa8BIubD2M0XoxBBsjxbsXwMgUScH7oQ9i-j1Y,43371
|
||||||
|
urllib3/contrib/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
||||||
|
urllib3/contrib/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/__pycache__/pyopenssl.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/__pycache__/socks.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__init__.py,sha256=u6KNgzjlFZbuAAXa_ybCR7gQ71VJESnF-IIdDA73brw,733
|
||||||
|
urllib3/contrib/emscripten/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__pycache__/connection.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__pycache__/fetch.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__pycache__/request.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/__pycache__/response.cpython-312.pyc,,
|
||||||
|
urllib3/contrib/emscripten/connection.py,sha256=j8DR_flE7hsoFhNfiqHLiaPaCsVbzG44jgahwvsQ52A,8771
|
||||||
|
urllib3/contrib/emscripten/emscripten_fetch_worker.js,sha256=CDfYF_9CDobtx2lGidyJ1zjDEvwNT5F-dchmVWXDh0E,3655
|
||||||
|
urllib3/contrib/emscripten/fetch.py,sha256=kco06lWoQ-fdFfN51-nzeTywPVBEHg89WIst33H3xcg,23484
|
||||||
|
urllib3/contrib/emscripten/request.py,sha256=mL28szy1KvE3NJhWor5jNmarp8gwplDU-7gwGZY5g0Q,566
|
||||||
|
urllib3/contrib/emscripten/response.py,sha256=7oVPENYZHuzEGRtG40HonpH5tAIYHsGcHPbJt2Z0U-Y,9507
|
||||||
|
urllib3/contrib/pyopenssl.py,sha256=Xp5Ym05VgXGhHa0C4wlutvHxY8SnKSS6WLb2t5Miu0s,19720
|
||||||
|
urllib3/contrib/socks.py,sha256=-iardc61GypsJzD6W6yuRS7KVCyfowcQrl_719H7lIM,7549
|
||||||
|
urllib3/exceptions.py,sha256=pziumHf0Vwx3z4gvUy7ou8nlM2yIYX0N3l3znEdeF5U,9938
|
||||||
|
urllib3/fields.py,sha256=FCf7UULSkf10cuTRUWTQESzxgl1WT8e2aCy3kfyZins,10829
|
||||||
|
urllib3/filepost.py,sha256=U8eNZ-mpKKHhrlbHEEiTxxgK16IejhEa7uz42yqA_dI,2388
|
||||||
|
urllib3/http2/__init__.py,sha256=xzrASH7R5ANRkPJOot5lGnATOq3KKuyXzI42rcnwmqs,1741
|
||||||
|
urllib3/http2/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/http2/__pycache__/connection.cpython-312.pyc,,
|
||||||
|
urllib3/http2/__pycache__/probe.cpython-312.pyc,,
|
||||||
|
urllib3/http2/connection.py,sha256=4DB0DkZEC3yIkhGjUDIHB17wrYCLaL0Ag5bDW2_mGPI,12694
|
||||||
|
urllib3/http2/probe.py,sha256=nnAkqbhAakOiF75rz7W0udZ38Eeh_uD8fjV74N73FEI,3014
|
||||||
|
urllib3/poolmanager.py,sha256=oKsgP1EsAI4OVgK9-9D3AYXZS5HYV8yKUSog-QbJ8Ts,23866
|
||||||
|
urllib3/py.typed,sha256=UaCuPFa3H8UAakbt-5G8SPacldTOGvJv18pPjUJ5gDY,93
|
||||||
|
urllib3/response.py,sha256=TVTSu6Q1U0U7hoHYMIRxxuh4zroeMo8b5EI4DOA13Eo,46480
|
||||||
|
urllib3/util/__init__.py,sha256=-qeS0QceivazvBEKDNFCAI-6ACcdDOE4TMvo7SLNlAQ,1001
|
||||||
|
urllib3/util/__pycache__/__init__.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/connection.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/proxy.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/request.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/response.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/retry.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/ssl_.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/ssl_match_hostname.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/ssltransport.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/timeout.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/url.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/util.cpython-312.pyc,,
|
||||||
|
urllib3/util/__pycache__/wait.cpython-312.pyc,,
|
||||||
|
urllib3/util/connection.py,sha256=JjO722lzHlzLXPTkr9ZWBdhseXnMVjMSb1DJLVrXSnQ,4444
|
||||||
|
urllib3/util/proxy.py,sha256=seP8-Q5B6bB0dMtwPj-YcZZQ30vHuLqRu-tI0JZ2fzs,1148
|
||||||
|
urllib3/util/request.py,sha256=XuAsEBT58DAZYUTwpMH5Hr3A1OPoMNvNIYIunbIqbc8,8411
|
||||||
|
urllib3/util/response.py,sha256=vQE639uoEhj1vpjEdxu5lNIhJCSUZkd7pqllUI0BZOA,3374
|
||||||
|
urllib3/util/retry.py,sha256=bj-2YUqblxLlv8THg5fxww-DM54XCbjgZXIQ71XioCY,18459
|
||||||
|
urllib3/util/ssl_.py,sha256=jxnQ3msYkVaokJVWqHNnAVdVtDdidrTHDeyk50gwqaQ,19786
|
||||||
|
urllib3/util/ssl_match_hostname.py,sha256=Di7DU7zokoltapT_F0Sj21ffYxwaS_cE5apOtwueeyA,5845
|
||||||
|
urllib3/util/ssltransport.py,sha256=Ez4O8pR_vT8dan_FvqBYS6dgDfBXEMfVfrzcdUoWfi4,8847
|
||||||
|
urllib3/util/timeout.py,sha256=4eT1FVeZZU7h7mYD1Jq2OXNe4fxekdNvhoWUkZusRpA,10346
|
||||||
|
urllib3/util/url.py,sha256=WRh-TMYXosmgp8m8lT4H5spoHw5yUjlcMCfU53AkoAs,15205
|
||||||
|
urllib3/util/util.py,sha256=j3lbZK1jPyiwD34T8IgJzdWEZVT-4E-0vYIJi9UjeNA,1146
|
||||||
|
urllib3/util/wait.py,sha256=_ph8IrUR3sqPqi0OopQgJUlH4wzkGeM5CiyA7XGGtmI,4423
|
||||||
@@ -0,0 +1,4 @@
|
|||||||
|
Wheel-Version: 1.0
|
||||||
|
Generator: hatchling 1.27.0
|
||||||
|
Root-Is-Purelib: true
|
||||||
|
Tag: py3-none-any
|
||||||
@@ -0,0 +1,21 @@
|
|||||||
|
MIT License
|
||||||
|
|
||||||
|
Copyright (c) 2008-2020 Andrey Petrov and contributors.
|
||||||
|
|
||||||
|
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||||
|
of this software and associated documentation files (the "Software"), to deal
|
||||||
|
in the Software without restriction, including without limitation the rights
|
||||||
|
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||||
|
copies of the Software, and to permit persons to whom the Software is
|
||||||
|
furnished to do so, subject to the following conditions:
|
||||||
|
|
||||||
|
The above copyright notice and this permission notice shall be included in all
|
||||||
|
copies or substantial portions of the Software.
|
||||||
|
|
||||||
|
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||||
|
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||||
|
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||||
|
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||||
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||||
|
SOFTWARE.
|
||||||
211
venv/lib/python3.12/site-packages/urllib3/__init__.py
Normal file
211
venv/lib/python3.12/site-packages/urllib3/__init__.py
Normal file
@@ -0,0 +1,211 @@
|
|||||||
|
"""
|
||||||
|
Python HTTP library with thread-safe connection pooling, file post support, user friendly, and more
|
||||||
|
"""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
# Set default logging handler to avoid "No handler found" warnings.
|
||||||
|
import logging
|
||||||
|
import sys
|
||||||
|
import typing
|
||||||
|
import warnings
|
||||||
|
from logging import NullHandler
|
||||||
|
|
||||||
|
from . import exceptions
|
||||||
|
from ._base_connection import _TYPE_BODY
|
||||||
|
from ._collections import HTTPHeaderDict
|
||||||
|
from ._version import __version__
|
||||||
|
from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool, connection_from_url
|
||||||
|
from .filepost import _TYPE_FIELDS, encode_multipart_formdata
|
||||||
|
from .poolmanager import PoolManager, ProxyManager, proxy_from_url
|
||||||
|
from .response import BaseHTTPResponse, HTTPResponse
|
||||||
|
from .util.request import make_headers
|
||||||
|
from .util.retry import Retry
|
||||||
|
from .util.timeout import Timeout
|
||||||
|
|
||||||
|
# Ensure that Python is compiled with OpenSSL 1.1.1+
|
||||||
|
# If the 'ssl' module isn't available at all that's
|
||||||
|
# fine, we only care if the module is available.
|
||||||
|
try:
|
||||||
|
import ssl
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
if not ssl.OPENSSL_VERSION.startswith("OpenSSL "): # Defensive:
|
||||||
|
warnings.warn(
|
||||||
|
"urllib3 v2 only supports OpenSSL 1.1.1+, currently "
|
||||||
|
f"the 'ssl' module is compiled with {ssl.OPENSSL_VERSION!r}. "
|
||||||
|
"See: https://github.com/urllib3/urllib3/issues/3020",
|
||||||
|
exceptions.NotOpenSSLWarning,
|
||||||
|
)
|
||||||
|
elif ssl.OPENSSL_VERSION_INFO < (1, 1, 1): # Defensive:
|
||||||
|
raise ImportError(
|
||||||
|
"urllib3 v2 only supports OpenSSL 1.1.1+, currently "
|
||||||
|
f"the 'ssl' module is compiled with {ssl.OPENSSL_VERSION!r}. "
|
||||||
|
"See: https://github.com/urllib3/urllib3/issues/2168"
|
||||||
|
)
|
||||||
|
|
||||||
|
__author__ = "Andrey Petrov (andrey.petrov@shazow.net)"
|
||||||
|
__license__ = "MIT"
|
||||||
|
__version__ = __version__
|
||||||
|
|
||||||
|
__all__ = (
|
||||||
|
"HTTPConnectionPool",
|
||||||
|
"HTTPHeaderDict",
|
||||||
|
"HTTPSConnectionPool",
|
||||||
|
"PoolManager",
|
||||||
|
"ProxyManager",
|
||||||
|
"HTTPResponse",
|
||||||
|
"Retry",
|
||||||
|
"Timeout",
|
||||||
|
"add_stderr_logger",
|
||||||
|
"connection_from_url",
|
||||||
|
"disable_warnings",
|
||||||
|
"encode_multipart_formdata",
|
||||||
|
"make_headers",
|
||||||
|
"proxy_from_url",
|
||||||
|
"request",
|
||||||
|
"BaseHTTPResponse",
|
||||||
|
)
|
||||||
|
|
||||||
|
logging.getLogger(__name__).addHandler(NullHandler())
|
||||||
|
|
||||||
|
|
||||||
|
def add_stderr_logger(
|
||||||
|
level: int = logging.DEBUG,
|
||||||
|
) -> logging.StreamHandler[typing.TextIO]:
|
||||||
|
"""
|
||||||
|
Helper for quickly adding a StreamHandler to the logger. Useful for
|
||||||
|
debugging.
|
||||||
|
|
||||||
|
Returns the handler after adding it.
|
||||||
|
"""
|
||||||
|
# This method needs to be in this __init__.py to get the __name__ correct
|
||||||
|
# even if urllib3 is vendored within another package.
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
handler = logging.StreamHandler()
|
||||||
|
handler.setFormatter(logging.Formatter("%(asctime)s %(levelname)s %(message)s"))
|
||||||
|
logger.addHandler(handler)
|
||||||
|
logger.setLevel(level)
|
||||||
|
logger.debug("Added a stderr logging handler to logger: %s", __name__)
|
||||||
|
return handler
|
||||||
|
|
||||||
|
|
||||||
|
# ... Clean up.
|
||||||
|
del NullHandler
|
||||||
|
|
||||||
|
|
||||||
|
# All warning filters *must* be appended unless you're really certain that they
|
||||||
|
# shouldn't be: otherwise, it's very hard for users to use most Python
|
||||||
|
# mechanisms to silence them.
|
||||||
|
# SecurityWarning's always go off by default.
|
||||||
|
warnings.simplefilter("always", exceptions.SecurityWarning, append=True)
|
||||||
|
# InsecurePlatformWarning's don't vary between requests, so we keep it default.
|
||||||
|
warnings.simplefilter("default", exceptions.InsecurePlatformWarning, append=True)
|
||||||
|
|
||||||
|
|
||||||
|
def disable_warnings(category: type[Warning] = exceptions.HTTPWarning) -> None:
|
||||||
|
"""
|
||||||
|
Helper for quickly disabling all urllib3 warnings.
|
||||||
|
"""
|
||||||
|
warnings.simplefilter("ignore", category)
|
||||||
|
|
||||||
|
|
||||||
|
_DEFAULT_POOL = PoolManager()
|
||||||
|
|
||||||
|
|
||||||
|
def request(
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
*,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
fields: _TYPE_FIELDS | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
preload_content: bool | None = True,
|
||||||
|
decode_content: bool | None = True,
|
||||||
|
redirect: bool | None = True,
|
||||||
|
retries: Retry | bool | int | None = None,
|
||||||
|
timeout: Timeout | float | int | None = 3,
|
||||||
|
json: typing.Any | None = None,
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
A convenience, top-level request method. It uses a module-global ``PoolManager`` instance.
|
||||||
|
Therefore, its side effects could be shared across dependencies relying on it.
|
||||||
|
To avoid side effects create a new ``PoolManager`` instance and use it instead.
|
||||||
|
The method does not accept low-level ``**urlopen_kw`` keyword arguments.
|
||||||
|
|
||||||
|
:param method:
|
||||||
|
HTTP request method (such as GET, POST, PUT, etc.)
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
The URL to perform the request on.
|
||||||
|
|
||||||
|
:param body:
|
||||||
|
Data to send in the request body, either :class:`str`, :class:`bytes`,
|
||||||
|
an iterable of :class:`str`/:class:`bytes`, or a file-like object.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Data to encode and send in the request body.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Dictionary of custom headers to send, such as User-Agent,
|
||||||
|
If-None-Match, etc.
|
||||||
|
|
||||||
|
:param bool preload_content:
|
||||||
|
If True, the response's body will be preloaded into memory.
|
||||||
|
|
||||||
|
:param bool decode_content:
|
||||||
|
If True, will attempt to decode the body based on the
|
||||||
|
'content-encoding' header.
|
||||||
|
|
||||||
|
:param redirect:
|
||||||
|
If True, automatically handle redirects (status codes 301, 302,
|
||||||
|
303, 307, 308). Each redirect counts as a retry. Disabling retries
|
||||||
|
will disable redirect, too.
|
||||||
|
|
||||||
|
:param retries:
|
||||||
|
Configure the number of retries to allow before raising a
|
||||||
|
:class:`~urllib3.exceptions.MaxRetryError` exception.
|
||||||
|
|
||||||
|
If ``None`` (default) will retry 3 times, see ``Retry.DEFAULT``. Pass a
|
||||||
|
:class:`~urllib3.util.retry.Retry` object for fine-grained control
|
||||||
|
over different types of retries.
|
||||||
|
Pass an integer number to retry connection errors that many times,
|
||||||
|
but no other types of errors. Pass zero to never retry.
|
||||||
|
|
||||||
|
If ``False``, then retries are disabled and any exception is raised
|
||||||
|
immediately. Also, instead of raising a MaxRetryError on redirects,
|
||||||
|
the redirect response will be returned.
|
||||||
|
|
||||||
|
:type retries: :class:`~urllib3.util.retry.Retry`, False, or an int.
|
||||||
|
|
||||||
|
:param timeout:
|
||||||
|
If specified, overrides the default timeout for this one
|
||||||
|
request. It may be a float (in seconds) or an instance of
|
||||||
|
:class:`urllib3.util.Timeout`.
|
||||||
|
|
||||||
|
:param json:
|
||||||
|
Data to encode and send as JSON with UTF-encoded in the request body.
|
||||||
|
The ``"Content-Type"`` header will be set to ``"application/json"``
|
||||||
|
unless specified otherwise.
|
||||||
|
"""
|
||||||
|
|
||||||
|
return _DEFAULT_POOL.request(
|
||||||
|
method,
|
||||||
|
url,
|
||||||
|
body=body,
|
||||||
|
fields=fields,
|
||||||
|
headers=headers,
|
||||||
|
preload_content=preload_content,
|
||||||
|
decode_content=decode_content,
|
||||||
|
redirect=redirect,
|
||||||
|
retries=retries,
|
||||||
|
timeout=timeout,
|
||||||
|
json=json,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
if sys.platform == "emscripten":
|
||||||
|
from .contrib.emscripten import inject_into_urllib3 # noqa: 401
|
||||||
|
|
||||||
|
inject_into_urllib3()
|
||||||
165
venv/lib/python3.12/site-packages/urllib3/_base_connection.py
Normal file
165
venv/lib/python3.12/site-packages/urllib3/_base_connection.py
Normal file
@@ -0,0 +1,165 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import typing
|
||||||
|
|
||||||
|
from .util.connection import _TYPE_SOCKET_OPTIONS
|
||||||
|
from .util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT
|
||||||
|
from .util.url import Url
|
||||||
|
|
||||||
|
_TYPE_BODY = typing.Union[bytes, typing.IO[typing.Any], typing.Iterable[bytes], str]
|
||||||
|
|
||||||
|
|
||||||
|
class ProxyConfig(typing.NamedTuple):
|
||||||
|
ssl_context: ssl.SSLContext | None
|
||||||
|
use_forwarding_for_https: bool
|
||||||
|
assert_hostname: None | str | typing.Literal[False]
|
||||||
|
assert_fingerprint: str | None
|
||||||
|
|
||||||
|
|
||||||
|
class _ResponseOptions(typing.NamedTuple):
|
||||||
|
# TODO: Remove this in favor of a better
|
||||||
|
# HTTP request/response lifecycle tracking.
|
||||||
|
request_method: str
|
||||||
|
request_url: str
|
||||||
|
preload_content: bool
|
||||||
|
decode_content: bool
|
||||||
|
enforce_content_length: bool
|
||||||
|
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
import ssl
|
||||||
|
from typing import Protocol
|
||||||
|
|
||||||
|
from .response import BaseHTTPResponse
|
||||||
|
|
||||||
|
class BaseHTTPConnection(Protocol):
|
||||||
|
default_port: typing.ClassVar[int]
|
||||||
|
default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]
|
||||||
|
|
||||||
|
host: str
|
||||||
|
port: int
|
||||||
|
timeout: None | (
|
||||||
|
float
|
||||||
|
) # Instance doesn't store _DEFAULT_TIMEOUT, must be resolved.
|
||||||
|
blocksize: int
|
||||||
|
source_address: tuple[str, int] | None
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None
|
||||||
|
|
||||||
|
proxy: Url | None
|
||||||
|
proxy_config: ProxyConfig | None
|
||||||
|
|
||||||
|
is_verified: bool
|
||||||
|
proxy_is_verified: bool | None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 8192,
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None = ...,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
) -> None: ...
|
||||||
|
|
||||||
|
def set_tunnel(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
scheme: str = "http",
|
||||||
|
) -> None: ...
|
||||||
|
|
||||||
|
def connect(self) -> None: ...
|
||||||
|
|
||||||
|
def request(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
# We know *at least* botocore is depending on the order of the
|
||||||
|
# first 3 parameters so to be safe we only mark the later ones
|
||||||
|
# as keyword-only to ensure we have space to extend.
|
||||||
|
*,
|
||||||
|
chunked: bool = False,
|
||||||
|
preload_content: bool = True,
|
||||||
|
decode_content: bool = True,
|
||||||
|
enforce_content_length: bool = True,
|
||||||
|
) -> None: ...
|
||||||
|
|
||||||
|
def getresponse(self) -> BaseHTTPResponse: ...
|
||||||
|
|
||||||
|
def close(self) -> None: ...
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_closed(self) -> bool:
|
||||||
|
"""Whether the connection either is brand new or has been previously closed.
|
||||||
|
If this property is True then both ``is_connected`` and ``has_connected_to_proxy``
|
||||||
|
properties must be False.
|
||||||
|
"""
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_connected(self) -> bool:
|
||||||
|
"""Whether the connection is actively connected to any origin (proxy or target)"""
|
||||||
|
|
||||||
|
@property
|
||||||
|
def has_connected_to_proxy(self) -> bool:
|
||||||
|
"""Whether the connection has successfully connected to its proxy.
|
||||||
|
This returns False if no proxy is in use. Used to determine whether
|
||||||
|
errors are coming from the proxy layer or from tunnelling to the target origin.
|
||||||
|
"""
|
||||||
|
|
||||||
|
class BaseHTTPSConnection(BaseHTTPConnection, Protocol):
|
||||||
|
default_port: typing.ClassVar[int]
|
||||||
|
default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]
|
||||||
|
|
||||||
|
# Certificate verification methods
|
||||||
|
cert_reqs: int | str | None
|
||||||
|
assert_hostname: None | str | typing.Literal[False]
|
||||||
|
assert_fingerprint: str | None
|
||||||
|
ssl_context: ssl.SSLContext | None
|
||||||
|
|
||||||
|
# Trusted CAs
|
||||||
|
ca_certs: str | None
|
||||||
|
ca_cert_dir: str | None
|
||||||
|
ca_cert_data: None | str | bytes
|
||||||
|
|
||||||
|
# TLS version
|
||||||
|
ssl_minimum_version: int | None
|
||||||
|
ssl_maximum_version: int | None
|
||||||
|
ssl_version: int | str | None # Deprecated
|
||||||
|
|
||||||
|
# Client certificates
|
||||||
|
cert_file: str | None
|
||||||
|
key_file: str | None
|
||||||
|
key_password: str | None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 16384,
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None = ...,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
cert_reqs: int | str | None = None,
|
||||||
|
assert_hostname: None | str | typing.Literal[False] = None,
|
||||||
|
assert_fingerprint: str | None = None,
|
||||||
|
server_hostname: str | None = None,
|
||||||
|
ssl_context: ssl.SSLContext | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
ssl_minimum_version: int | None = None,
|
||||||
|
ssl_maximum_version: int | None = None,
|
||||||
|
ssl_version: int | str | None = None, # Deprecated
|
||||||
|
cert_file: str | None = None,
|
||||||
|
key_file: str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
) -> None: ...
|
||||||
479
venv/lib/python3.12/site-packages/urllib3/_collections.py
Normal file
479
venv/lib/python3.12/site-packages/urllib3/_collections.py
Normal file
@@ -0,0 +1,479 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import typing
|
||||||
|
from collections import OrderedDict
|
||||||
|
from enum import Enum, auto
|
||||||
|
from threading import RLock
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
# We can only import Protocol if TYPE_CHECKING because it's a development
|
||||||
|
# dependency, and is not available at runtime.
|
||||||
|
from typing import Protocol
|
||||||
|
|
||||||
|
from typing_extensions import Self
|
||||||
|
|
||||||
|
class HasGettableStringKeys(Protocol):
|
||||||
|
def keys(self) -> typing.Iterator[str]: ...
|
||||||
|
|
||||||
|
def __getitem__(self, key: str) -> str: ...
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = ["RecentlyUsedContainer", "HTTPHeaderDict"]
|
||||||
|
|
||||||
|
|
||||||
|
# Key type
|
||||||
|
_KT = typing.TypeVar("_KT")
|
||||||
|
# Value type
|
||||||
|
_VT = typing.TypeVar("_VT")
|
||||||
|
# Default type
|
||||||
|
_DT = typing.TypeVar("_DT")
|
||||||
|
|
||||||
|
ValidHTTPHeaderSource = typing.Union[
|
||||||
|
"HTTPHeaderDict",
|
||||||
|
typing.Mapping[str, str],
|
||||||
|
typing.Iterable[tuple[str, str]],
|
||||||
|
"HasGettableStringKeys",
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
class _Sentinel(Enum):
|
||||||
|
not_passed = auto()
|
||||||
|
|
||||||
|
|
||||||
|
def ensure_can_construct_http_header_dict(
|
||||||
|
potential: object,
|
||||||
|
) -> ValidHTTPHeaderSource | None:
|
||||||
|
if isinstance(potential, HTTPHeaderDict):
|
||||||
|
return potential
|
||||||
|
elif isinstance(potential, typing.Mapping):
|
||||||
|
# Full runtime checking of the contents of a Mapping is expensive, so for the
|
||||||
|
# purposes of typechecking, we assume that any Mapping is the right shape.
|
||||||
|
return typing.cast(typing.Mapping[str, str], potential)
|
||||||
|
elif isinstance(potential, typing.Iterable):
|
||||||
|
# Similarly to Mapping, full runtime checking of the contents of an Iterable is
|
||||||
|
# expensive, so for the purposes of typechecking, we assume that any Iterable
|
||||||
|
# is the right shape.
|
||||||
|
return typing.cast(typing.Iterable[tuple[str, str]], potential)
|
||||||
|
elif hasattr(potential, "keys") and hasattr(potential, "__getitem__"):
|
||||||
|
return typing.cast("HasGettableStringKeys", potential)
|
||||||
|
else:
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
class RecentlyUsedContainer(typing.Generic[_KT, _VT], typing.MutableMapping[_KT, _VT]):
|
||||||
|
"""
|
||||||
|
Provides a thread-safe dict-like container which maintains up to
|
||||||
|
``maxsize`` keys while throwing away the least-recently-used keys beyond
|
||||||
|
``maxsize``.
|
||||||
|
|
||||||
|
:param maxsize:
|
||||||
|
Maximum number of recent elements to retain.
|
||||||
|
|
||||||
|
:param dispose_func:
|
||||||
|
Every time an item is evicted from the container,
|
||||||
|
``dispose_func(value)`` is called. Callback which will get called
|
||||||
|
"""
|
||||||
|
|
||||||
|
_container: typing.OrderedDict[_KT, _VT]
|
||||||
|
_maxsize: int
|
||||||
|
dispose_func: typing.Callable[[_VT], None] | None
|
||||||
|
lock: RLock
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
maxsize: int = 10,
|
||||||
|
dispose_func: typing.Callable[[_VT], None] | None = None,
|
||||||
|
) -> None:
|
||||||
|
super().__init__()
|
||||||
|
self._maxsize = maxsize
|
||||||
|
self.dispose_func = dispose_func
|
||||||
|
self._container = OrderedDict()
|
||||||
|
self.lock = RLock()
|
||||||
|
|
||||||
|
def __getitem__(self, key: _KT) -> _VT:
|
||||||
|
# Re-insert the item, moving it to the end of the eviction line.
|
||||||
|
with self.lock:
|
||||||
|
item = self._container.pop(key)
|
||||||
|
self._container[key] = item
|
||||||
|
return item
|
||||||
|
|
||||||
|
def __setitem__(self, key: _KT, value: _VT) -> None:
|
||||||
|
evicted_item = None
|
||||||
|
with self.lock:
|
||||||
|
# Possibly evict the existing value of 'key'
|
||||||
|
try:
|
||||||
|
# If the key exists, we'll overwrite it, which won't change the
|
||||||
|
# size of the pool. Because accessing a key should move it to
|
||||||
|
# the end of the eviction line, we pop it out first.
|
||||||
|
evicted_item = key, self._container.pop(key)
|
||||||
|
self._container[key] = value
|
||||||
|
except KeyError:
|
||||||
|
# When the key does not exist, we insert the value first so that
|
||||||
|
# evicting works in all cases, including when self._maxsize is 0
|
||||||
|
self._container[key] = value
|
||||||
|
if len(self._container) > self._maxsize:
|
||||||
|
# If we didn't evict an existing value, and we've hit our maximum
|
||||||
|
# size, then we have to evict the least recently used item from
|
||||||
|
# the beginning of the container.
|
||||||
|
evicted_item = self._container.popitem(last=False)
|
||||||
|
|
||||||
|
# After releasing the lock on the pool, dispose of any evicted value.
|
||||||
|
if evicted_item is not None and self.dispose_func:
|
||||||
|
_, evicted_value = evicted_item
|
||||||
|
self.dispose_func(evicted_value)
|
||||||
|
|
||||||
|
def __delitem__(self, key: _KT) -> None:
|
||||||
|
with self.lock:
|
||||||
|
value = self._container.pop(key)
|
||||||
|
|
||||||
|
if self.dispose_func:
|
||||||
|
self.dispose_func(value)
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
with self.lock:
|
||||||
|
return len(self._container)
|
||||||
|
|
||||||
|
def __iter__(self) -> typing.NoReturn:
|
||||||
|
raise NotImplementedError(
|
||||||
|
"Iteration over this class is unlikely to be threadsafe."
|
||||||
|
)
|
||||||
|
|
||||||
|
def clear(self) -> None:
|
||||||
|
with self.lock:
|
||||||
|
# Copy pointers to all values, then wipe the mapping
|
||||||
|
values = list(self._container.values())
|
||||||
|
self._container.clear()
|
||||||
|
|
||||||
|
if self.dispose_func:
|
||||||
|
for value in values:
|
||||||
|
self.dispose_func(value)
|
||||||
|
|
||||||
|
def keys(self) -> set[_KT]: # type: ignore[override]
|
||||||
|
with self.lock:
|
||||||
|
return set(self._container.keys())
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPHeaderDictItemView(set[tuple[str, str]]):
|
||||||
|
"""
|
||||||
|
HTTPHeaderDict is unusual for a Mapping[str, str] in that it has two modes of
|
||||||
|
address.
|
||||||
|
|
||||||
|
If we directly try to get an item with a particular name, we will get a string
|
||||||
|
back that is the concatenated version of all the values:
|
||||||
|
|
||||||
|
>>> d['X-Header-Name']
|
||||||
|
'Value1, Value2, Value3'
|
||||||
|
|
||||||
|
However, if we iterate over an HTTPHeaderDict's items, we will optionally combine
|
||||||
|
these values based on whether combine=True was called when building up the dictionary
|
||||||
|
|
||||||
|
>>> d = HTTPHeaderDict({"A": "1", "B": "foo"})
|
||||||
|
>>> d.add("A", "2", combine=True)
|
||||||
|
>>> d.add("B", "bar")
|
||||||
|
>>> list(d.items())
|
||||||
|
[
|
||||||
|
('A', '1, 2'),
|
||||||
|
('B', 'foo'),
|
||||||
|
('B', 'bar'),
|
||||||
|
]
|
||||||
|
|
||||||
|
This class conforms to the interface required by the MutableMapping ABC while
|
||||||
|
also giving us the nonstandard iteration behavior we want; items with duplicate
|
||||||
|
keys, ordered by time of first insertion.
|
||||||
|
"""
|
||||||
|
|
||||||
|
_headers: HTTPHeaderDict
|
||||||
|
|
||||||
|
def __init__(self, headers: HTTPHeaderDict) -> None:
|
||||||
|
self._headers = headers
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
return len(list(self._headers.iteritems()))
|
||||||
|
|
||||||
|
def __iter__(self) -> typing.Iterator[tuple[str, str]]:
|
||||||
|
return self._headers.iteritems()
|
||||||
|
|
||||||
|
def __contains__(self, item: object) -> bool:
|
||||||
|
if isinstance(item, tuple) and len(item) == 2:
|
||||||
|
passed_key, passed_val = item
|
||||||
|
if isinstance(passed_key, str) and isinstance(passed_val, str):
|
||||||
|
return self._headers._has_value_for_header(passed_key, passed_val)
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPHeaderDict(typing.MutableMapping[str, str]):
|
||||||
|
"""
|
||||||
|
:param headers:
|
||||||
|
An iterable of field-value pairs. Must not contain multiple field names
|
||||||
|
when compared case-insensitively.
|
||||||
|
|
||||||
|
:param kwargs:
|
||||||
|
Additional field-value pairs to pass in to ``dict.update``.
|
||||||
|
|
||||||
|
A ``dict`` like container for storing HTTP Headers.
|
||||||
|
|
||||||
|
Field names are stored and compared case-insensitively in compliance with
|
||||||
|
RFC 7230. Iteration provides the first case-sensitive key seen for each
|
||||||
|
case-insensitive pair.
|
||||||
|
|
||||||
|
Using ``__setitem__`` syntax overwrites fields that compare equal
|
||||||
|
case-insensitively in order to maintain ``dict``'s api. For fields that
|
||||||
|
compare equal, instead create a new ``HTTPHeaderDict`` and use ``.add``
|
||||||
|
in a loop.
|
||||||
|
|
||||||
|
If multiple fields that are equal case-insensitively are passed to the
|
||||||
|
constructor or ``.update``, the behavior is undefined and some will be
|
||||||
|
lost.
|
||||||
|
|
||||||
|
>>> headers = HTTPHeaderDict()
|
||||||
|
>>> headers.add('Set-Cookie', 'foo=bar')
|
||||||
|
>>> headers.add('set-cookie', 'baz=quxx')
|
||||||
|
>>> headers['content-length'] = '7'
|
||||||
|
>>> headers['SET-cookie']
|
||||||
|
'foo=bar, baz=quxx'
|
||||||
|
>>> headers['Content-Length']
|
||||||
|
'7'
|
||||||
|
"""
|
||||||
|
|
||||||
|
_container: typing.MutableMapping[str, list[str]]
|
||||||
|
|
||||||
|
def __init__(self, headers: ValidHTTPHeaderSource | None = None, **kwargs: str):
|
||||||
|
super().__init__()
|
||||||
|
self._container = {} # 'dict' is insert-ordered
|
||||||
|
if headers is not None:
|
||||||
|
if isinstance(headers, HTTPHeaderDict):
|
||||||
|
self._copy_from(headers)
|
||||||
|
else:
|
||||||
|
self.extend(headers)
|
||||||
|
if kwargs:
|
||||||
|
self.extend(kwargs)
|
||||||
|
|
||||||
|
def __setitem__(self, key: str, val: str) -> None:
|
||||||
|
# avoid a bytes/str comparison by decoding before httplib
|
||||||
|
if isinstance(key, bytes):
|
||||||
|
key = key.decode("latin-1")
|
||||||
|
self._container[key.lower()] = [key, val]
|
||||||
|
|
||||||
|
def __getitem__(self, key: str) -> str:
|
||||||
|
val = self._container[key.lower()]
|
||||||
|
return ", ".join(val[1:])
|
||||||
|
|
||||||
|
def __delitem__(self, key: str) -> None:
|
||||||
|
del self._container[key.lower()]
|
||||||
|
|
||||||
|
def __contains__(self, key: object) -> bool:
|
||||||
|
if isinstance(key, str):
|
||||||
|
return key.lower() in self._container
|
||||||
|
return False
|
||||||
|
|
||||||
|
def setdefault(self, key: str, default: str = "") -> str:
|
||||||
|
return super().setdefault(key, default)
|
||||||
|
|
||||||
|
def __eq__(self, other: object) -> bool:
|
||||||
|
maybe_constructable = ensure_can_construct_http_header_dict(other)
|
||||||
|
if maybe_constructable is None:
|
||||||
|
return False
|
||||||
|
else:
|
||||||
|
other_as_http_header_dict = type(self)(maybe_constructable)
|
||||||
|
|
||||||
|
return {k.lower(): v for k, v in self.itermerged()} == {
|
||||||
|
k.lower(): v for k, v in other_as_http_header_dict.itermerged()
|
||||||
|
}
|
||||||
|
|
||||||
|
def __ne__(self, other: object) -> bool:
|
||||||
|
return not self.__eq__(other)
|
||||||
|
|
||||||
|
def __len__(self) -> int:
|
||||||
|
return len(self._container)
|
||||||
|
|
||||||
|
def __iter__(self) -> typing.Iterator[str]:
|
||||||
|
# Only provide the originally cased names
|
||||||
|
for vals in self._container.values():
|
||||||
|
yield vals[0]
|
||||||
|
|
||||||
|
def discard(self, key: str) -> None:
|
||||||
|
try:
|
||||||
|
del self[key]
|
||||||
|
except KeyError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def add(self, key: str, val: str, *, combine: bool = False) -> None:
|
||||||
|
"""Adds a (name, value) pair, doesn't overwrite the value if it already
|
||||||
|
exists.
|
||||||
|
|
||||||
|
If this is called with combine=True, instead of adding a new header value
|
||||||
|
as a distinct item during iteration, this will instead append the value to
|
||||||
|
any existing header value with a comma. If no existing header value exists
|
||||||
|
for the key, then the value will simply be added, ignoring the combine parameter.
|
||||||
|
|
||||||
|
>>> headers = HTTPHeaderDict(foo='bar')
|
||||||
|
>>> headers.add('Foo', 'baz')
|
||||||
|
>>> headers['foo']
|
||||||
|
'bar, baz'
|
||||||
|
>>> list(headers.items())
|
||||||
|
[('foo', 'bar'), ('foo', 'baz')]
|
||||||
|
>>> headers.add('foo', 'quz', combine=True)
|
||||||
|
>>> list(headers.items())
|
||||||
|
[('foo', 'bar, baz, quz')]
|
||||||
|
"""
|
||||||
|
# avoid a bytes/str comparison by decoding before httplib
|
||||||
|
if isinstance(key, bytes):
|
||||||
|
key = key.decode("latin-1")
|
||||||
|
key_lower = key.lower()
|
||||||
|
new_vals = [key, val]
|
||||||
|
# Keep the common case aka no item present as fast as possible
|
||||||
|
vals = self._container.setdefault(key_lower, new_vals)
|
||||||
|
if new_vals is not vals:
|
||||||
|
# if there are values here, then there is at least the initial
|
||||||
|
# key/value pair
|
||||||
|
assert len(vals) >= 2
|
||||||
|
if combine:
|
||||||
|
vals[-1] = vals[-1] + ", " + val
|
||||||
|
else:
|
||||||
|
vals.append(val)
|
||||||
|
|
||||||
|
def extend(self, *args: ValidHTTPHeaderSource, **kwargs: str) -> None:
|
||||||
|
"""Generic import function for any type of header-like object.
|
||||||
|
Adapted version of MutableMapping.update in order to insert items
|
||||||
|
with self.add instead of self.__setitem__
|
||||||
|
"""
|
||||||
|
if len(args) > 1:
|
||||||
|
raise TypeError(
|
||||||
|
f"extend() takes at most 1 positional arguments ({len(args)} given)"
|
||||||
|
)
|
||||||
|
other = args[0] if len(args) >= 1 else ()
|
||||||
|
|
||||||
|
if isinstance(other, HTTPHeaderDict):
|
||||||
|
for key, val in other.iteritems():
|
||||||
|
self.add(key, val)
|
||||||
|
elif isinstance(other, typing.Mapping):
|
||||||
|
for key, val in other.items():
|
||||||
|
self.add(key, val)
|
||||||
|
elif isinstance(other, typing.Iterable):
|
||||||
|
other = typing.cast(typing.Iterable[tuple[str, str]], other)
|
||||||
|
for key, value in other:
|
||||||
|
self.add(key, value)
|
||||||
|
elif hasattr(other, "keys") and hasattr(other, "__getitem__"):
|
||||||
|
# THIS IS NOT A TYPESAFE BRANCH
|
||||||
|
# In this branch, the object has a `keys` attr but is not a Mapping or any of
|
||||||
|
# the other types indicated in the method signature. We do some stuff with
|
||||||
|
# it as though it partially implements the Mapping interface, but we're not
|
||||||
|
# doing that stuff safely AT ALL.
|
||||||
|
for key in other.keys():
|
||||||
|
self.add(key, other[key])
|
||||||
|
|
||||||
|
for key, value in kwargs.items():
|
||||||
|
self.add(key, value)
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def getlist(self, key: str) -> list[str]: ...
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def getlist(self, key: str, default: _DT) -> list[str] | _DT: ...
|
||||||
|
|
||||||
|
def getlist(
|
||||||
|
self, key: str, default: _Sentinel | _DT = _Sentinel.not_passed
|
||||||
|
) -> list[str] | _DT:
|
||||||
|
"""Returns a list of all the values for the named field. Returns an
|
||||||
|
empty list if the key doesn't exist."""
|
||||||
|
try:
|
||||||
|
vals = self._container[key.lower()]
|
||||||
|
except KeyError:
|
||||||
|
if default is _Sentinel.not_passed:
|
||||||
|
# _DT is unbound; empty list is instance of List[str]
|
||||||
|
return []
|
||||||
|
# _DT is bound; default is instance of _DT
|
||||||
|
return default
|
||||||
|
else:
|
||||||
|
# _DT may or may not be bound; vals[1:] is instance of List[str], which
|
||||||
|
# meets our external interface requirement of `Union[List[str], _DT]`.
|
||||||
|
return vals[1:]
|
||||||
|
|
||||||
|
def _prepare_for_method_change(self) -> Self:
|
||||||
|
"""
|
||||||
|
Remove content-specific header fields before changing the request
|
||||||
|
method to GET or HEAD according to RFC 9110, Section 15.4.
|
||||||
|
"""
|
||||||
|
content_specific_headers = [
|
||||||
|
"Content-Encoding",
|
||||||
|
"Content-Language",
|
||||||
|
"Content-Location",
|
||||||
|
"Content-Type",
|
||||||
|
"Content-Length",
|
||||||
|
"Digest",
|
||||||
|
"Last-Modified",
|
||||||
|
]
|
||||||
|
for header in content_specific_headers:
|
||||||
|
self.discard(header)
|
||||||
|
return self
|
||||||
|
|
||||||
|
# Backwards compatibility for httplib
|
||||||
|
getheaders = getlist
|
||||||
|
getallmatchingheaders = getlist
|
||||||
|
iget = getlist
|
||||||
|
|
||||||
|
# Backwards compatibility for http.cookiejar
|
||||||
|
get_all = getlist
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
return f"{type(self).__name__}({dict(self.itermerged())})"
|
||||||
|
|
||||||
|
def _copy_from(self, other: HTTPHeaderDict) -> None:
|
||||||
|
for key in other:
|
||||||
|
val = other.getlist(key)
|
||||||
|
self._container[key.lower()] = [key, *val]
|
||||||
|
|
||||||
|
def copy(self) -> Self:
|
||||||
|
clone = type(self)()
|
||||||
|
clone._copy_from(self)
|
||||||
|
return clone
|
||||||
|
|
||||||
|
def iteritems(self) -> typing.Iterator[tuple[str, str]]:
|
||||||
|
"""Iterate over all header lines, including duplicate ones."""
|
||||||
|
for key in self:
|
||||||
|
vals = self._container[key.lower()]
|
||||||
|
for val in vals[1:]:
|
||||||
|
yield vals[0], val
|
||||||
|
|
||||||
|
def itermerged(self) -> typing.Iterator[tuple[str, str]]:
|
||||||
|
"""Iterate over all headers, merging duplicate ones together."""
|
||||||
|
for key in self:
|
||||||
|
val = self._container[key.lower()]
|
||||||
|
yield val[0], ", ".join(val[1:])
|
||||||
|
|
||||||
|
def items(self) -> HTTPHeaderDictItemView: # type: ignore[override]
|
||||||
|
return HTTPHeaderDictItemView(self)
|
||||||
|
|
||||||
|
def _has_value_for_header(self, header_name: str, potential_value: str) -> bool:
|
||||||
|
if header_name in self:
|
||||||
|
return potential_value in self._container[header_name.lower()][1:]
|
||||||
|
return False
|
||||||
|
|
||||||
|
def __ior__(self, other: object) -> HTTPHeaderDict:
|
||||||
|
# Supports extending a header dict in-place using operator |=
|
||||||
|
# combining items with add instead of __setitem__
|
||||||
|
maybe_constructable = ensure_can_construct_http_header_dict(other)
|
||||||
|
if maybe_constructable is None:
|
||||||
|
return NotImplemented
|
||||||
|
self.extend(maybe_constructable)
|
||||||
|
return self
|
||||||
|
|
||||||
|
def __or__(self, other: object) -> Self:
|
||||||
|
# Supports merging header dicts using operator |
|
||||||
|
# combining items with add instead of __setitem__
|
||||||
|
maybe_constructable = ensure_can_construct_http_header_dict(other)
|
||||||
|
if maybe_constructable is None:
|
||||||
|
return NotImplemented
|
||||||
|
result = self.copy()
|
||||||
|
result.extend(maybe_constructable)
|
||||||
|
return result
|
||||||
|
|
||||||
|
def __ror__(self, other: object) -> Self:
|
||||||
|
# Supports merging header dicts using operator | when other is on left side
|
||||||
|
# combining items with add instead of __setitem__
|
||||||
|
maybe_constructable = ensure_can_construct_http_header_dict(other)
|
||||||
|
if maybe_constructable is None:
|
||||||
|
return NotImplemented
|
||||||
|
result = type(self)(maybe_constructable)
|
||||||
|
result.extend(self)
|
||||||
|
return result
|
||||||
278
venv/lib/python3.12/site-packages/urllib3/_request_methods.py
Normal file
278
venv/lib/python3.12/site-packages/urllib3/_request_methods.py
Normal file
@@ -0,0 +1,278 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import json as _json
|
||||||
|
import typing
|
||||||
|
from urllib.parse import urlencode
|
||||||
|
|
||||||
|
from ._base_connection import _TYPE_BODY
|
||||||
|
from ._collections import HTTPHeaderDict
|
||||||
|
from .filepost import _TYPE_FIELDS, encode_multipart_formdata
|
||||||
|
from .response import BaseHTTPResponse
|
||||||
|
|
||||||
|
__all__ = ["RequestMethods"]
|
||||||
|
|
||||||
|
_TYPE_ENCODE_URL_FIELDS = typing.Union[
|
||||||
|
typing.Sequence[tuple[str, typing.Union[str, bytes]]],
|
||||||
|
typing.Mapping[str, typing.Union[str, bytes]],
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
class RequestMethods:
|
||||||
|
"""
|
||||||
|
Convenience mixin for classes who implement a :meth:`urlopen` method, such
|
||||||
|
as :class:`urllib3.HTTPConnectionPool` and
|
||||||
|
:class:`urllib3.PoolManager`.
|
||||||
|
|
||||||
|
Provides behavior for making common types of HTTP request methods and
|
||||||
|
decides which type of request field encoding to use.
|
||||||
|
|
||||||
|
Specifically,
|
||||||
|
|
||||||
|
:meth:`.request_encode_url` is for sending requests whose fields are
|
||||||
|
encoded in the URL (such as GET, HEAD, DELETE).
|
||||||
|
|
||||||
|
:meth:`.request_encode_body` is for sending requests whose fields are
|
||||||
|
encoded in the *body* of the request using multipart or www-form-urlencoded
|
||||||
|
(such as for POST, PUT, PATCH).
|
||||||
|
|
||||||
|
:meth:`.request` is for making any kind of request, it will look up the
|
||||||
|
appropriate encoding format and use one of the above two methods to make
|
||||||
|
the request.
|
||||||
|
|
||||||
|
Initializer parameters:
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Headers to include with all requests, unless other headers are given
|
||||||
|
explicitly.
|
||||||
|
"""
|
||||||
|
|
||||||
|
_encode_url_methods = {"DELETE", "GET", "HEAD", "OPTIONS"}
|
||||||
|
|
||||||
|
def __init__(self, headers: typing.Mapping[str, str] | None = None) -> None:
|
||||||
|
self.headers = headers or {}
|
||||||
|
|
||||||
|
def urlopen(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
encode_multipart: bool = True,
|
||||||
|
multipart_boundary: str | None = None,
|
||||||
|
**kw: typing.Any,
|
||||||
|
) -> BaseHTTPResponse: # Abstract
|
||||||
|
raise NotImplementedError(
|
||||||
|
"Classes extending RequestMethods must implement "
|
||||||
|
"their own ``urlopen`` method."
|
||||||
|
)
|
||||||
|
|
||||||
|
def request(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
fields: _TYPE_FIELDS | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
json: typing.Any | None = None,
|
||||||
|
**urlopen_kw: typing.Any,
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
Make a request using :meth:`urlopen` with the appropriate encoding of
|
||||||
|
``fields`` based on the ``method`` used.
|
||||||
|
|
||||||
|
This is a convenience method that requires the least amount of manual
|
||||||
|
effort. It can be used in most situations, while still having the
|
||||||
|
option to drop down to more specific methods when necessary, such as
|
||||||
|
:meth:`request_encode_url`, :meth:`request_encode_body`,
|
||||||
|
or even the lowest level :meth:`urlopen`.
|
||||||
|
|
||||||
|
:param method:
|
||||||
|
HTTP request method (such as GET, POST, PUT, etc.)
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
The URL to perform the request on.
|
||||||
|
|
||||||
|
:param body:
|
||||||
|
Data to send in the request body, either :class:`str`, :class:`bytes`,
|
||||||
|
an iterable of :class:`str`/:class:`bytes`, or a file-like object.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Data to encode and send in the URL or request body, depending on ``method``.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Dictionary of custom headers to send, such as User-Agent,
|
||||||
|
If-None-Match, etc. If None, pool headers are used. If provided,
|
||||||
|
these headers completely replace any pool-specific headers.
|
||||||
|
|
||||||
|
:param json:
|
||||||
|
Data to encode and send as JSON with UTF-encoded in the request body.
|
||||||
|
The ``"Content-Type"`` header will be set to ``"application/json"``
|
||||||
|
unless specified otherwise.
|
||||||
|
"""
|
||||||
|
method = method.upper()
|
||||||
|
|
||||||
|
if json is not None and body is not None:
|
||||||
|
raise TypeError(
|
||||||
|
"request got values for both 'body' and 'json' parameters which are mutually exclusive"
|
||||||
|
)
|
||||||
|
|
||||||
|
if json is not None:
|
||||||
|
if headers is None:
|
||||||
|
headers = self.headers
|
||||||
|
|
||||||
|
if not ("content-type" in map(str.lower, headers.keys())):
|
||||||
|
headers = HTTPHeaderDict(headers)
|
||||||
|
headers["Content-Type"] = "application/json"
|
||||||
|
|
||||||
|
body = _json.dumps(json, separators=(",", ":"), ensure_ascii=False).encode(
|
||||||
|
"utf-8"
|
||||||
|
)
|
||||||
|
|
||||||
|
if body is not None:
|
||||||
|
urlopen_kw["body"] = body
|
||||||
|
|
||||||
|
if method in self._encode_url_methods:
|
||||||
|
return self.request_encode_url(
|
||||||
|
method,
|
||||||
|
url,
|
||||||
|
fields=fields, # type: ignore[arg-type]
|
||||||
|
headers=headers,
|
||||||
|
**urlopen_kw,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
return self.request_encode_body(
|
||||||
|
method, url, fields=fields, headers=headers, **urlopen_kw
|
||||||
|
)
|
||||||
|
|
||||||
|
def request_encode_url(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
fields: _TYPE_ENCODE_URL_FIELDS | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
**urlopen_kw: str,
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
Make a request using :meth:`urlopen` with the ``fields`` encoded in
|
||||||
|
the url. This is useful for request methods like GET, HEAD, DELETE, etc.
|
||||||
|
|
||||||
|
:param method:
|
||||||
|
HTTP request method (such as GET, POST, PUT, etc.)
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
The URL to perform the request on.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Data to encode and send in the URL.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Dictionary of custom headers to send, such as User-Agent,
|
||||||
|
If-None-Match, etc. If None, pool headers are used. If provided,
|
||||||
|
these headers completely replace any pool-specific headers.
|
||||||
|
"""
|
||||||
|
if headers is None:
|
||||||
|
headers = self.headers
|
||||||
|
|
||||||
|
extra_kw: dict[str, typing.Any] = {"headers": headers}
|
||||||
|
extra_kw.update(urlopen_kw)
|
||||||
|
|
||||||
|
if fields:
|
||||||
|
url += "?" + urlencode(fields)
|
||||||
|
|
||||||
|
return self.urlopen(method, url, **extra_kw)
|
||||||
|
|
||||||
|
def request_encode_body(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
fields: _TYPE_FIELDS | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
encode_multipart: bool = True,
|
||||||
|
multipart_boundary: str | None = None,
|
||||||
|
**urlopen_kw: str,
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
Make a request using :meth:`urlopen` with the ``fields`` encoded in
|
||||||
|
the body. This is useful for request methods like POST, PUT, PATCH, etc.
|
||||||
|
|
||||||
|
When ``encode_multipart=True`` (default), then
|
||||||
|
:func:`urllib3.encode_multipart_formdata` is used to encode
|
||||||
|
the payload with the appropriate content type. Otherwise
|
||||||
|
:func:`urllib.parse.urlencode` is used with the
|
||||||
|
'application/x-www-form-urlencoded' content type.
|
||||||
|
|
||||||
|
Multipart encoding must be used when posting files, and it's reasonably
|
||||||
|
safe to use it in other times too. However, it may break request
|
||||||
|
signing, such as with OAuth.
|
||||||
|
|
||||||
|
Supports an optional ``fields`` parameter of key/value strings AND
|
||||||
|
key/filetuple. A filetuple is a (filename, data, MIME type) tuple where
|
||||||
|
the MIME type is optional. For example::
|
||||||
|
|
||||||
|
fields = {
|
||||||
|
'foo': 'bar',
|
||||||
|
'fakefile': ('foofile.txt', 'contents of foofile'),
|
||||||
|
'realfile': ('barfile.txt', open('realfile').read()),
|
||||||
|
'typedfile': ('bazfile.bin', open('bazfile').read(),
|
||||||
|
'image/jpeg'),
|
||||||
|
'nonamefile': 'contents of nonamefile field',
|
||||||
|
}
|
||||||
|
|
||||||
|
When uploading a file, providing a filename (the first parameter of the
|
||||||
|
tuple) is optional but recommended to best mimic behavior of browsers.
|
||||||
|
|
||||||
|
Note that if ``headers`` are supplied, the 'Content-Type' header will
|
||||||
|
be overwritten because it depends on the dynamic random boundary string
|
||||||
|
which is used to compose the body of the request. The random boundary
|
||||||
|
string can be explicitly set with the ``multipart_boundary`` parameter.
|
||||||
|
|
||||||
|
:param method:
|
||||||
|
HTTP request method (such as GET, POST, PUT, etc.)
|
||||||
|
|
||||||
|
:param url:
|
||||||
|
The URL to perform the request on.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Data to encode and send in the request body.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Dictionary of custom headers to send, such as User-Agent,
|
||||||
|
If-None-Match, etc. If None, pool headers are used. If provided,
|
||||||
|
these headers completely replace any pool-specific headers.
|
||||||
|
|
||||||
|
:param encode_multipart:
|
||||||
|
If True, encode the ``fields`` using the multipart/form-data MIME
|
||||||
|
format.
|
||||||
|
|
||||||
|
:param multipart_boundary:
|
||||||
|
If not specified, then a random boundary will be generated using
|
||||||
|
:func:`urllib3.filepost.choose_boundary`.
|
||||||
|
"""
|
||||||
|
if headers is None:
|
||||||
|
headers = self.headers
|
||||||
|
|
||||||
|
extra_kw: dict[str, typing.Any] = {"headers": HTTPHeaderDict(headers)}
|
||||||
|
body: bytes | str
|
||||||
|
|
||||||
|
if fields:
|
||||||
|
if "body" in urlopen_kw:
|
||||||
|
raise TypeError(
|
||||||
|
"request got values for both 'fields' and 'body', can only specify one."
|
||||||
|
)
|
||||||
|
|
||||||
|
if encode_multipart:
|
||||||
|
body, content_type = encode_multipart_formdata(
|
||||||
|
fields, boundary=multipart_boundary
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
body, content_type = (
|
||||||
|
urlencode(fields), # type: ignore[arg-type]
|
||||||
|
"application/x-www-form-urlencoded",
|
||||||
|
)
|
||||||
|
|
||||||
|
extra_kw["body"] = body
|
||||||
|
extra_kw["headers"].setdefault("Content-Type", content_type)
|
||||||
|
|
||||||
|
extra_kw.update(urlopen_kw)
|
||||||
|
|
||||||
|
return self.urlopen(method, url, **extra_kw)
|
||||||
21
venv/lib/python3.12/site-packages/urllib3/_version.py
Normal file
21
venv/lib/python3.12/site-packages/urllib3/_version.py
Normal file
@@ -0,0 +1,21 @@
|
|||||||
|
# file generated by setuptools-scm
|
||||||
|
# don't change, don't track in version control
|
||||||
|
|
||||||
|
__all__ = ["__version__", "__version_tuple__", "version", "version_tuple"]
|
||||||
|
|
||||||
|
TYPE_CHECKING = False
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from typing import Tuple
|
||||||
|
from typing import Union
|
||||||
|
|
||||||
|
VERSION_TUPLE = Tuple[Union[int, str], ...]
|
||||||
|
else:
|
||||||
|
VERSION_TUPLE = object
|
||||||
|
|
||||||
|
version: str
|
||||||
|
__version__: str
|
||||||
|
__version_tuple__: VERSION_TUPLE
|
||||||
|
version_tuple: VERSION_TUPLE
|
||||||
|
|
||||||
|
__version__ = version = '2.5.0'
|
||||||
|
__version_tuple__ = version_tuple = (2, 5, 0)
|
||||||
1093
venv/lib/python3.12/site-packages/urllib3/connection.py
Normal file
1093
venv/lib/python3.12/site-packages/urllib3/connection.py
Normal file
File diff suppressed because it is too large
Load Diff
1178
venv/lib/python3.12/site-packages/urllib3/connectionpool.py
Normal file
1178
venv/lib/python3.12/site-packages/urllib3/connectionpool.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,16 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import urllib3.connection
|
||||||
|
|
||||||
|
from ...connectionpool import HTTPConnectionPool, HTTPSConnectionPool
|
||||||
|
from .connection import EmscriptenHTTPConnection, EmscriptenHTTPSConnection
|
||||||
|
|
||||||
|
|
||||||
|
def inject_into_urllib3() -> None:
|
||||||
|
# override connection classes to use emscripten specific classes
|
||||||
|
# n.b. mypy complains about the overriding of classes below
|
||||||
|
# if it isn't ignored
|
||||||
|
HTTPConnectionPool.ConnectionCls = EmscriptenHTTPConnection
|
||||||
|
HTTPSConnectionPool.ConnectionCls = EmscriptenHTTPSConnection
|
||||||
|
urllib3.connection.HTTPConnection = EmscriptenHTTPConnection # type: ignore[misc,assignment]
|
||||||
|
urllib3.connection.HTTPSConnection = EmscriptenHTTPSConnection # type: ignore[misc,assignment]
|
||||||
@@ -0,0 +1,255 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import os
|
||||||
|
import typing
|
||||||
|
|
||||||
|
# use http.client.HTTPException for consistency with non-emscripten
|
||||||
|
from http.client import HTTPException as HTTPException # noqa: F401
|
||||||
|
from http.client import ResponseNotReady
|
||||||
|
|
||||||
|
from ..._base_connection import _TYPE_BODY
|
||||||
|
from ...connection import HTTPConnection, ProxyConfig, port_by_scheme
|
||||||
|
from ...exceptions import TimeoutError
|
||||||
|
from ...response import BaseHTTPResponse
|
||||||
|
from ...util.connection import _TYPE_SOCKET_OPTIONS
|
||||||
|
from ...util.timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT
|
||||||
|
from ...util.url import Url
|
||||||
|
from .fetch import _RequestError, _TimeoutError, send_request, send_streaming_request
|
||||||
|
from .request import EmscriptenRequest
|
||||||
|
from .response import EmscriptenHttpResponseWrapper, EmscriptenResponse
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from ..._base_connection import BaseHTTPConnection, BaseHTTPSConnection
|
||||||
|
|
||||||
|
|
||||||
|
class EmscriptenHTTPConnection:
|
||||||
|
default_port: typing.ClassVar[int] = port_by_scheme["http"]
|
||||||
|
default_socket_options: typing.ClassVar[_TYPE_SOCKET_OPTIONS]
|
||||||
|
|
||||||
|
timeout: None | (float)
|
||||||
|
|
||||||
|
host: str
|
||||||
|
port: int
|
||||||
|
blocksize: int
|
||||||
|
source_address: tuple[str, int] | None
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None
|
||||||
|
|
||||||
|
proxy: Url | None
|
||||||
|
proxy_config: ProxyConfig | None
|
||||||
|
|
||||||
|
is_verified: bool = False
|
||||||
|
proxy_is_verified: bool | None = None
|
||||||
|
|
||||||
|
_response: EmscriptenResponse | None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int = 0,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 8192,
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None = None,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
) -> None:
|
||||||
|
self.host = host
|
||||||
|
self.port = port
|
||||||
|
self.timeout = timeout if isinstance(timeout, float) else 0.0
|
||||||
|
self.scheme = "http"
|
||||||
|
self._closed = True
|
||||||
|
self._response = None
|
||||||
|
# ignore these things because we don't
|
||||||
|
# have control over that stuff
|
||||||
|
self.proxy = None
|
||||||
|
self.proxy_config = None
|
||||||
|
self.blocksize = blocksize
|
||||||
|
self.source_address = None
|
||||||
|
self.socket_options = None
|
||||||
|
self.is_verified = False
|
||||||
|
|
||||||
|
def set_tunnel(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = 0,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
scheme: str = "http",
|
||||||
|
) -> None:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def connect(self) -> None:
|
||||||
|
pass
|
||||||
|
|
||||||
|
def request(
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
# We know *at least* botocore is depending on the order of the
|
||||||
|
# first 3 parameters so to be safe we only mark the later ones
|
||||||
|
# as keyword-only to ensure we have space to extend.
|
||||||
|
*,
|
||||||
|
chunked: bool = False,
|
||||||
|
preload_content: bool = True,
|
||||||
|
decode_content: bool = True,
|
||||||
|
enforce_content_length: bool = True,
|
||||||
|
) -> None:
|
||||||
|
self._closed = False
|
||||||
|
if url.startswith("/"):
|
||||||
|
# no scheme / host / port included, make a full url
|
||||||
|
url = f"{self.scheme}://{self.host}:{self.port}" + url
|
||||||
|
request = EmscriptenRequest(
|
||||||
|
url=url,
|
||||||
|
method=method,
|
||||||
|
timeout=self.timeout if self.timeout else 0,
|
||||||
|
decode_content=decode_content,
|
||||||
|
)
|
||||||
|
request.set_body(body)
|
||||||
|
if headers:
|
||||||
|
for k, v in headers.items():
|
||||||
|
request.set_header(k, v)
|
||||||
|
self._response = None
|
||||||
|
try:
|
||||||
|
if not preload_content:
|
||||||
|
self._response = send_streaming_request(request)
|
||||||
|
if self._response is None:
|
||||||
|
self._response = send_request(request)
|
||||||
|
except _TimeoutError as e:
|
||||||
|
raise TimeoutError(e.message) from e
|
||||||
|
except _RequestError as e:
|
||||||
|
raise HTTPException(e.message) from e
|
||||||
|
|
||||||
|
def getresponse(self) -> BaseHTTPResponse:
|
||||||
|
if self._response is not None:
|
||||||
|
return EmscriptenHttpResponseWrapper(
|
||||||
|
internal_response=self._response,
|
||||||
|
url=self._response.request.url,
|
||||||
|
connection=self,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ResponseNotReady()
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
self._closed = True
|
||||||
|
self._response = None
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_closed(self) -> bool:
|
||||||
|
"""Whether the connection either is brand new or has been previously closed.
|
||||||
|
If this property is True then both ``is_connected`` and ``has_connected_to_proxy``
|
||||||
|
properties must be False.
|
||||||
|
"""
|
||||||
|
return self._closed
|
||||||
|
|
||||||
|
@property
|
||||||
|
def is_connected(self) -> bool:
|
||||||
|
"""Whether the connection is actively connected to any origin (proxy or target)"""
|
||||||
|
return True
|
||||||
|
|
||||||
|
@property
|
||||||
|
def has_connected_to_proxy(self) -> bool:
|
||||||
|
"""Whether the connection has successfully connected to its proxy.
|
||||||
|
This returns False if no proxy is in use. Used to determine whether
|
||||||
|
errors are coming from the proxy layer or from tunnelling to the target origin.
|
||||||
|
"""
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
class EmscriptenHTTPSConnection(EmscriptenHTTPConnection):
|
||||||
|
default_port = port_by_scheme["https"]
|
||||||
|
# all this is basically ignored, as browser handles https
|
||||||
|
cert_reqs: int | str | None = None
|
||||||
|
ca_certs: str | None = None
|
||||||
|
ca_cert_dir: str | None = None
|
||||||
|
ca_cert_data: None | str | bytes = None
|
||||||
|
cert_file: str | None
|
||||||
|
key_file: str | None
|
||||||
|
key_password: str | None
|
||||||
|
ssl_context: typing.Any | None
|
||||||
|
ssl_version: int | str | None = None
|
||||||
|
ssl_minimum_version: int | None = None
|
||||||
|
ssl_maximum_version: int | None = None
|
||||||
|
assert_hostname: None | str | typing.Literal[False]
|
||||||
|
assert_fingerprint: str | None = None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int = 0,
|
||||||
|
*,
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
blocksize: int = 16384,
|
||||||
|
socket_options: (
|
||||||
|
None | _TYPE_SOCKET_OPTIONS
|
||||||
|
) = HTTPConnection.default_socket_options,
|
||||||
|
proxy: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
cert_reqs: int | str | None = None,
|
||||||
|
assert_hostname: None | str | typing.Literal[False] = None,
|
||||||
|
assert_fingerprint: str | None = None,
|
||||||
|
server_hostname: str | None = None,
|
||||||
|
ssl_context: typing.Any | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
ssl_minimum_version: int | None = None,
|
||||||
|
ssl_maximum_version: int | None = None,
|
||||||
|
ssl_version: int | str | None = None, # Deprecated
|
||||||
|
cert_file: str | None = None,
|
||||||
|
key_file: str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
) -> None:
|
||||||
|
super().__init__(
|
||||||
|
host,
|
||||||
|
port=port,
|
||||||
|
timeout=timeout,
|
||||||
|
source_address=source_address,
|
||||||
|
blocksize=blocksize,
|
||||||
|
socket_options=socket_options,
|
||||||
|
proxy=proxy,
|
||||||
|
proxy_config=proxy_config,
|
||||||
|
)
|
||||||
|
self.scheme = "https"
|
||||||
|
|
||||||
|
self.key_file = key_file
|
||||||
|
self.cert_file = cert_file
|
||||||
|
self.key_password = key_password
|
||||||
|
self.ssl_context = ssl_context
|
||||||
|
self.server_hostname = server_hostname
|
||||||
|
self.assert_hostname = assert_hostname
|
||||||
|
self.assert_fingerprint = assert_fingerprint
|
||||||
|
self.ssl_version = ssl_version
|
||||||
|
self.ssl_minimum_version = ssl_minimum_version
|
||||||
|
self.ssl_maximum_version = ssl_maximum_version
|
||||||
|
self.ca_certs = ca_certs and os.path.expanduser(ca_certs)
|
||||||
|
self.ca_cert_dir = ca_cert_dir and os.path.expanduser(ca_cert_dir)
|
||||||
|
self.ca_cert_data = ca_cert_data
|
||||||
|
|
||||||
|
self.cert_reqs = None
|
||||||
|
|
||||||
|
# The browser will automatically verify all requests.
|
||||||
|
# We have no control over that setting.
|
||||||
|
self.is_verified = True
|
||||||
|
|
||||||
|
def set_cert(
|
||||||
|
self,
|
||||||
|
key_file: str | None = None,
|
||||||
|
cert_file: str | None = None,
|
||||||
|
cert_reqs: int | str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
assert_hostname: None | str | typing.Literal[False] = None,
|
||||||
|
assert_fingerprint: str | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
) -> None:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
# verify that this class implements BaseHTTP(s) connection correctly
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
_supports_http_protocol: BaseHTTPConnection = EmscriptenHTTPConnection("", 0)
|
||||||
|
_supports_https_protocol: BaseHTTPSConnection = EmscriptenHTTPSConnection("", 0)
|
||||||
@@ -0,0 +1,110 @@
|
|||||||
|
let Status = {
|
||||||
|
SUCCESS_HEADER: -1,
|
||||||
|
SUCCESS_EOF: -2,
|
||||||
|
ERROR_TIMEOUT: -3,
|
||||||
|
ERROR_EXCEPTION: -4,
|
||||||
|
};
|
||||||
|
|
||||||
|
let connections = {};
|
||||||
|
let nextConnectionID = 1;
|
||||||
|
const encoder = new TextEncoder();
|
||||||
|
|
||||||
|
self.addEventListener("message", async function (event) {
|
||||||
|
if (event.data.close) {
|
||||||
|
let connectionID = event.data.close;
|
||||||
|
delete connections[connectionID];
|
||||||
|
return;
|
||||||
|
} else if (event.data.getMore) {
|
||||||
|
let connectionID = event.data.getMore;
|
||||||
|
let { curOffset, value, reader, intBuffer, byteBuffer } =
|
||||||
|
connections[connectionID];
|
||||||
|
// if we still have some in buffer, then just send it back straight away
|
||||||
|
if (!value || curOffset >= value.length) {
|
||||||
|
// read another buffer if required
|
||||||
|
try {
|
||||||
|
let readResponse = await reader.read();
|
||||||
|
|
||||||
|
if (readResponse.done) {
|
||||||
|
// read everything - clear connection and return
|
||||||
|
delete connections[connectionID];
|
||||||
|
Atomics.store(intBuffer, 0, Status.SUCCESS_EOF);
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
// finished reading successfully
|
||||||
|
// return from event handler
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
curOffset = 0;
|
||||||
|
connections[connectionID].value = readResponse.value;
|
||||||
|
value = readResponse.value;
|
||||||
|
} catch (error) {
|
||||||
|
console.log("Request exception:", error);
|
||||||
|
let errorBytes = encoder.encode(error.message);
|
||||||
|
let written = errorBytes.length;
|
||||||
|
byteBuffer.set(errorBytes);
|
||||||
|
intBuffer[1] = written;
|
||||||
|
Atomics.store(intBuffer, 0, Status.ERROR_EXCEPTION);
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// send as much buffer as we can
|
||||||
|
let curLen = value.length - curOffset;
|
||||||
|
if (curLen > byteBuffer.length) {
|
||||||
|
curLen = byteBuffer.length;
|
||||||
|
}
|
||||||
|
byteBuffer.set(value.subarray(curOffset, curOffset + curLen), 0);
|
||||||
|
|
||||||
|
Atomics.store(intBuffer, 0, curLen); // store current length in bytes
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
curOffset += curLen;
|
||||||
|
connections[connectionID].curOffset = curOffset;
|
||||||
|
|
||||||
|
return;
|
||||||
|
} else {
|
||||||
|
// start fetch
|
||||||
|
let connectionID = nextConnectionID;
|
||||||
|
nextConnectionID += 1;
|
||||||
|
const intBuffer = new Int32Array(event.data.buffer);
|
||||||
|
const byteBuffer = new Uint8Array(event.data.buffer, 8);
|
||||||
|
try {
|
||||||
|
const response = await fetch(event.data.url, event.data.fetchParams);
|
||||||
|
// return the headers first via textencoder
|
||||||
|
var headers = [];
|
||||||
|
for (const pair of response.headers.entries()) {
|
||||||
|
headers.push([pair[0], pair[1]]);
|
||||||
|
}
|
||||||
|
let headerObj = {
|
||||||
|
headers: headers,
|
||||||
|
status: response.status,
|
||||||
|
connectionID,
|
||||||
|
};
|
||||||
|
const headerText = JSON.stringify(headerObj);
|
||||||
|
let headerBytes = encoder.encode(headerText);
|
||||||
|
let written = headerBytes.length;
|
||||||
|
byteBuffer.set(headerBytes);
|
||||||
|
intBuffer[1] = written;
|
||||||
|
// make a connection
|
||||||
|
connections[connectionID] = {
|
||||||
|
reader: response.body.getReader(),
|
||||||
|
intBuffer: intBuffer,
|
||||||
|
byteBuffer: byteBuffer,
|
||||||
|
value: undefined,
|
||||||
|
curOffset: 0,
|
||||||
|
};
|
||||||
|
// set header ready
|
||||||
|
Atomics.store(intBuffer, 0, Status.SUCCESS_HEADER);
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
// all fetching after this goes through a new postmessage call with getMore
|
||||||
|
// this allows for parallel requests
|
||||||
|
} catch (error) {
|
||||||
|
console.log("Request exception:", error);
|
||||||
|
let errorBytes = encoder.encode(error.message);
|
||||||
|
let written = errorBytes.length;
|
||||||
|
byteBuffer.set(errorBytes);
|
||||||
|
intBuffer[1] = written;
|
||||||
|
Atomics.store(intBuffer, 0, Status.ERROR_EXCEPTION);
|
||||||
|
Atomics.notify(intBuffer, 0);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
});
|
||||||
|
self.postMessage({ inited: true });
|
||||||
@@ -0,0 +1,728 @@
|
|||||||
|
"""
|
||||||
|
Support for streaming http requests in emscripten.
|
||||||
|
|
||||||
|
A few caveats -
|
||||||
|
|
||||||
|
If your browser (or Node.js) has WebAssembly JavaScript Promise Integration enabled
|
||||||
|
https://github.com/WebAssembly/js-promise-integration/blob/main/proposals/js-promise-integration/Overview.md
|
||||||
|
*and* you launch pyodide using `pyodide.runPythonAsync`, this will fetch data using the
|
||||||
|
JavaScript asynchronous fetch api (wrapped via `pyodide.ffi.call_sync`). In this case
|
||||||
|
timeouts and streaming should just work.
|
||||||
|
|
||||||
|
Otherwise, it uses a combination of XMLHttpRequest and a web-worker for streaming.
|
||||||
|
|
||||||
|
This approach has several caveats:
|
||||||
|
|
||||||
|
Firstly, you can't do streaming http in the main UI thread, because atomics.wait isn't allowed.
|
||||||
|
Streaming only works if you're running pyodide in a web worker.
|
||||||
|
|
||||||
|
Secondly, this uses an extra web worker and SharedArrayBuffer to do the asynchronous fetch
|
||||||
|
operation, so it requires that you have crossOriginIsolation enabled, by serving over https
|
||||||
|
(or from localhost) with the two headers below set:
|
||||||
|
|
||||||
|
Cross-Origin-Opener-Policy: same-origin
|
||||||
|
Cross-Origin-Embedder-Policy: require-corp
|
||||||
|
|
||||||
|
You can tell if cross origin isolation is successfully enabled by looking at the global crossOriginIsolated variable in
|
||||||
|
JavaScript console. If it isn't, streaming requests will fallback to XMLHttpRequest, i.e. getting the whole
|
||||||
|
request into a buffer and then returning it. it shows a warning in the JavaScript console in this case.
|
||||||
|
|
||||||
|
Finally, the webworker which does the streaming fetch is created on initial import, but will only be started once
|
||||||
|
control is returned to javascript. Call `await wait_for_streaming_ready()` to wait for streaming fetch.
|
||||||
|
|
||||||
|
NB: in this code, there are a lot of JavaScript objects. They are named js_*
|
||||||
|
to make it clear what type of object they are.
|
||||||
|
"""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import io
|
||||||
|
import json
|
||||||
|
from email.parser import Parser
|
||||||
|
from importlib.resources import files
|
||||||
|
from typing import TYPE_CHECKING, Any
|
||||||
|
|
||||||
|
import js # type: ignore[import-not-found]
|
||||||
|
from pyodide.ffi import ( # type: ignore[import-not-found]
|
||||||
|
JsArray,
|
||||||
|
JsException,
|
||||||
|
JsProxy,
|
||||||
|
to_js,
|
||||||
|
)
|
||||||
|
|
||||||
|
if TYPE_CHECKING:
|
||||||
|
from typing_extensions import Buffer
|
||||||
|
|
||||||
|
from .request import EmscriptenRequest
|
||||||
|
from .response import EmscriptenResponse
|
||||||
|
|
||||||
|
"""
|
||||||
|
There are some headers that trigger unintended CORS preflight requests.
|
||||||
|
See also https://github.com/koenvo/pyodide-http/issues/22
|
||||||
|
"""
|
||||||
|
HEADERS_TO_IGNORE = ("user-agent",)
|
||||||
|
|
||||||
|
SUCCESS_HEADER = -1
|
||||||
|
SUCCESS_EOF = -2
|
||||||
|
ERROR_TIMEOUT = -3
|
||||||
|
ERROR_EXCEPTION = -4
|
||||||
|
|
||||||
|
_STREAMING_WORKER_CODE = (
|
||||||
|
files(__package__)
|
||||||
|
.joinpath("emscripten_fetch_worker.js")
|
||||||
|
.read_text(encoding="utf-8")
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class _RequestError(Exception):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
message: str | None = None,
|
||||||
|
*,
|
||||||
|
request: EmscriptenRequest | None = None,
|
||||||
|
response: EmscriptenResponse | None = None,
|
||||||
|
):
|
||||||
|
self.request = request
|
||||||
|
self.response = response
|
||||||
|
self.message = message
|
||||||
|
super().__init__(self.message)
|
||||||
|
|
||||||
|
|
||||||
|
class _StreamingError(_RequestError):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class _TimeoutError(_RequestError):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
def _obj_from_dict(dict_val: dict[str, Any]) -> JsProxy:
|
||||||
|
return to_js(dict_val, dict_converter=js.Object.fromEntries)
|
||||||
|
|
||||||
|
|
||||||
|
class _ReadStream(io.RawIOBase):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
int_buffer: JsArray,
|
||||||
|
byte_buffer: JsArray,
|
||||||
|
timeout: float,
|
||||||
|
worker: JsProxy,
|
||||||
|
connection_id: int,
|
||||||
|
request: EmscriptenRequest,
|
||||||
|
):
|
||||||
|
self.int_buffer = int_buffer
|
||||||
|
self.byte_buffer = byte_buffer
|
||||||
|
self.read_pos = 0
|
||||||
|
self.read_len = 0
|
||||||
|
self.connection_id = connection_id
|
||||||
|
self.worker = worker
|
||||||
|
self.timeout = int(1000 * timeout) if timeout > 0 else None
|
||||||
|
self.is_live = True
|
||||||
|
self._is_closed = False
|
||||||
|
self.request: EmscriptenRequest | None = request
|
||||||
|
|
||||||
|
def __del__(self) -> None:
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
# this is compatible with _base_connection
|
||||||
|
def is_closed(self) -> bool:
|
||||||
|
return self._is_closed
|
||||||
|
|
||||||
|
# for compatibility with RawIOBase
|
||||||
|
@property
|
||||||
|
def closed(self) -> bool:
|
||||||
|
return self.is_closed()
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
if self.is_closed():
|
||||||
|
return
|
||||||
|
self.read_len = 0
|
||||||
|
self.read_pos = 0
|
||||||
|
self.int_buffer = None
|
||||||
|
self.byte_buffer = None
|
||||||
|
self._is_closed = True
|
||||||
|
self.request = None
|
||||||
|
if self.is_live:
|
||||||
|
self.worker.postMessage(_obj_from_dict({"close": self.connection_id}))
|
||||||
|
self.is_live = False
|
||||||
|
super().close()
|
||||||
|
|
||||||
|
def readable(self) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def writable(self) -> bool:
|
||||||
|
return False
|
||||||
|
|
||||||
|
def seekable(self) -> bool:
|
||||||
|
return False
|
||||||
|
|
||||||
|
def readinto(self, byte_obj: Buffer) -> int:
|
||||||
|
if not self.int_buffer:
|
||||||
|
raise _StreamingError(
|
||||||
|
"No buffer for stream in _ReadStream.readinto",
|
||||||
|
request=self.request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
if self.read_len == 0:
|
||||||
|
# wait for the worker to send something
|
||||||
|
js.Atomics.store(self.int_buffer, 0, ERROR_TIMEOUT)
|
||||||
|
self.worker.postMessage(_obj_from_dict({"getMore": self.connection_id}))
|
||||||
|
if (
|
||||||
|
js.Atomics.wait(self.int_buffer, 0, ERROR_TIMEOUT, self.timeout)
|
||||||
|
== "timed-out"
|
||||||
|
):
|
||||||
|
raise _TimeoutError
|
||||||
|
data_len = self.int_buffer[0]
|
||||||
|
if data_len > 0:
|
||||||
|
self.read_len = data_len
|
||||||
|
self.read_pos = 0
|
||||||
|
elif data_len == ERROR_EXCEPTION:
|
||||||
|
string_len = self.int_buffer[1]
|
||||||
|
# decode the error string
|
||||||
|
js_decoder = js.TextDecoder.new()
|
||||||
|
json_str = js_decoder.decode(self.byte_buffer.slice(0, string_len))
|
||||||
|
raise _StreamingError(
|
||||||
|
f"Exception thrown in fetch: {json_str}",
|
||||||
|
request=self.request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# EOF, free the buffers and return zero
|
||||||
|
# and free the request
|
||||||
|
self.is_live = False
|
||||||
|
self.close()
|
||||||
|
return 0
|
||||||
|
# copy from int32array to python bytes
|
||||||
|
ret_length = min(self.read_len, len(memoryview(byte_obj)))
|
||||||
|
subarray = self.byte_buffer.subarray(
|
||||||
|
self.read_pos, self.read_pos + ret_length
|
||||||
|
).to_py()
|
||||||
|
memoryview(byte_obj)[0:ret_length] = subarray
|
||||||
|
self.read_len -= ret_length
|
||||||
|
self.read_pos += ret_length
|
||||||
|
return ret_length
|
||||||
|
|
||||||
|
|
||||||
|
class _StreamingFetcher:
|
||||||
|
def __init__(self) -> None:
|
||||||
|
# make web-worker and data buffer on startup
|
||||||
|
self.streaming_ready = False
|
||||||
|
|
||||||
|
js_data_blob = js.Blob.new(
|
||||||
|
to_js([_STREAMING_WORKER_CODE], create_pyproxies=False),
|
||||||
|
_obj_from_dict({"type": "application/javascript"}),
|
||||||
|
)
|
||||||
|
|
||||||
|
def promise_resolver(js_resolve_fn: JsProxy, js_reject_fn: JsProxy) -> None:
|
||||||
|
def onMsg(e: JsProxy) -> None:
|
||||||
|
self.streaming_ready = True
|
||||||
|
js_resolve_fn(e)
|
||||||
|
|
||||||
|
def onErr(e: JsProxy) -> None:
|
||||||
|
js_reject_fn(e) # Defensive: never happens in ci
|
||||||
|
|
||||||
|
self.js_worker.onmessage = onMsg
|
||||||
|
self.js_worker.onerror = onErr
|
||||||
|
|
||||||
|
js_data_url = js.URL.createObjectURL(js_data_blob)
|
||||||
|
self.js_worker = js.globalThis.Worker.new(js_data_url)
|
||||||
|
self.js_worker_ready_promise = js.globalThis.Promise.new(promise_resolver)
|
||||||
|
|
||||||
|
def send(self, request: EmscriptenRequest) -> EmscriptenResponse:
|
||||||
|
headers = {
|
||||||
|
k: v for k, v in request.headers.items() if k not in HEADERS_TO_IGNORE
|
||||||
|
}
|
||||||
|
|
||||||
|
body = request.body
|
||||||
|
fetch_data = {"headers": headers, "body": to_js(body), "method": request.method}
|
||||||
|
# start the request off in the worker
|
||||||
|
timeout = int(1000 * request.timeout) if request.timeout > 0 else None
|
||||||
|
js_shared_buffer = js.SharedArrayBuffer.new(1048576)
|
||||||
|
js_int_buffer = js.Int32Array.new(js_shared_buffer)
|
||||||
|
js_byte_buffer = js.Uint8Array.new(js_shared_buffer, 8)
|
||||||
|
|
||||||
|
js.Atomics.store(js_int_buffer, 0, ERROR_TIMEOUT)
|
||||||
|
js.Atomics.notify(js_int_buffer, 0)
|
||||||
|
js_absolute_url = js.URL.new(request.url, js.location).href
|
||||||
|
self.js_worker.postMessage(
|
||||||
|
_obj_from_dict(
|
||||||
|
{
|
||||||
|
"buffer": js_shared_buffer,
|
||||||
|
"url": js_absolute_url,
|
||||||
|
"fetchParams": fetch_data,
|
||||||
|
}
|
||||||
|
)
|
||||||
|
)
|
||||||
|
# wait for the worker to send something
|
||||||
|
js.Atomics.wait(js_int_buffer, 0, ERROR_TIMEOUT, timeout)
|
||||||
|
if js_int_buffer[0] == ERROR_TIMEOUT:
|
||||||
|
raise _TimeoutError(
|
||||||
|
"Timeout connecting to streaming request",
|
||||||
|
request=request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
elif js_int_buffer[0] == SUCCESS_HEADER:
|
||||||
|
# got response
|
||||||
|
# header length is in second int of intBuffer
|
||||||
|
string_len = js_int_buffer[1]
|
||||||
|
# decode the rest to a JSON string
|
||||||
|
js_decoder = js.TextDecoder.new()
|
||||||
|
# this does a copy (the slice) because decode can't work on shared array
|
||||||
|
# for some silly reason
|
||||||
|
json_str = js_decoder.decode(js_byte_buffer.slice(0, string_len))
|
||||||
|
# get it as an object
|
||||||
|
response_obj = json.loads(json_str)
|
||||||
|
return EmscriptenResponse(
|
||||||
|
request=request,
|
||||||
|
status_code=response_obj["status"],
|
||||||
|
headers=response_obj["headers"],
|
||||||
|
body=_ReadStream(
|
||||||
|
js_int_buffer,
|
||||||
|
js_byte_buffer,
|
||||||
|
request.timeout,
|
||||||
|
self.js_worker,
|
||||||
|
response_obj["connectionID"],
|
||||||
|
request,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
elif js_int_buffer[0] == ERROR_EXCEPTION:
|
||||||
|
string_len = js_int_buffer[1]
|
||||||
|
# decode the error string
|
||||||
|
js_decoder = js.TextDecoder.new()
|
||||||
|
json_str = js_decoder.decode(js_byte_buffer.slice(0, string_len))
|
||||||
|
raise _StreamingError(
|
||||||
|
f"Exception thrown in fetch: {json_str}", request=request, response=None
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise _StreamingError(
|
||||||
|
f"Unknown status from worker in fetch: {js_int_buffer[0]}",
|
||||||
|
request=request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class _JSPIReadStream(io.RawIOBase):
|
||||||
|
"""
|
||||||
|
A read stream that uses pyodide.ffi.run_sync to read from a JavaScript fetch
|
||||||
|
response. This requires support for WebAssembly JavaScript Promise Integration
|
||||||
|
in the containing browser, and for pyodide to be launched via runPythonAsync.
|
||||||
|
|
||||||
|
:param js_read_stream:
|
||||||
|
The JavaScript stream reader
|
||||||
|
|
||||||
|
:param timeout:
|
||||||
|
Timeout in seconds
|
||||||
|
|
||||||
|
:param request:
|
||||||
|
The request we're handling
|
||||||
|
|
||||||
|
:param response:
|
||||||
|
The response this stream relates to
|
||||||
|
|
||||||
|
:param js_abort_controller:
|
||||||
|
A JavaScript AbortController object, used for timeouts
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
js_read_stream: Any,
|
||||||
|
timeout: float,
|
||||||
|
request: EmscriptenRequest,
|
||||||
|
response: EmscriptenResponse,
|
||||||
|
js_abort_controller: Any, # JavaScript AbortController for timeouts
|
||||||
|
):
|
||||||
|
self.js_read_stream = js_read_stream
|
||||||
|
self.timeout = timeout
|
||||||
|
self._is_closed = False
|
||||||
|
self._is_done = False
|
||||||
|
self.request: EmscriptenRequest | None = request
|
||||||
|
self.response: EmscriptenResponse | None = response
|
||||||
|
self.current_buffer = None
|
||||||
|
self.current_buffer_pos = 0
|
||||||
|
self.js_abort_controller = js_abort_controller
|
||||||
|
|
||||||
|
def __del__(self) -> None:
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
# this is compatible with _base_connection
|
||||||
|
def is_closed(self) -> bool:
|
||||||
|
return self._is_closed
|
||||||
|
|
||||||
|
# for compatibility with RawIOBase
|
||||||
|
@property
|
||||||
|
def closed(self) -> bool:
|
||||||
|
return self.is_closed()
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
if self.is_closed():
|
||||||
|
return
|
||||||
|
self.read_len = 0
|
||||||
|
self.read_pos = 0
|
||||||
|
self.js_read_stream.cancel()
|
||||||
|
self.js_read_stream = None
|
||||||
|
self._is_closed = True
|
||||||
|
self._is_done = True
|
||||||
|
self.request = None
|
||||||
|
self.response = None
|
||||||
|
super().close()
|
||||||
|
|
||||||
|
def readable(self) -> bool:
|
||||||
|
return True
|
||||||
|
|
||||||
|
def writable(self) -> bool:
|
||||||
|
return False
|
||||||
|
|
||||||
|
def seekable(self) -> bool:
|
||||||
|
return False
|
||||||
|
|
||||||
|
def _get_next_buffer(self) -> bool:
|
||||||
|
result_js = _run_sync_with_timeout(
|
||||||
|
self.js_read_stream.read(),
|
||||||
|
self.timeout,
|
||||||
|
self.js_abort_controller,
|
||||||
|
request=self.request,
|
||||||
|
response=self.response,
|
||||||
|
)
|
||||||
|
if result_js.done:
|
||||||
|
self._is_done = True
|
||||||
|
return False
|
||||||
|
else:
|
||||||
|
self.current_buffer = result_js.value.to_py()
|
||||||
|
self.current_buffer_pos = 0
|
||||||
|
return True
|
||||||
|
|
||||||
|
def readinto(self, byte_obj: Buffer) -> int:
|
||||||
|
if self.current_buffer is None:
|
||||||
|
if not self._get_next_buffer() or self.current_buffer is None:
|
||||||
|
self.close()
|
||||||
|
return 0
|
||||||
|
ret_length = min(
|
||||||
|
len(byte_obj), len(self.current_buffer) - self.current_buffer_pos
|
||||||
|
)
|
||||||
|
byte_obj[0:ret_length] = self.current_buffer[
|
||||||
|
self.current_buffer_pos : self.current_buffer_pos + ret_length
|
||||||
|
]
|
||||||
|
self.current_buffer_pos += ret_length
|
||||||
|
if self.current_buffer_pos == len(self.current_buffer):
|
||||||
|
self.current_buffer = None
|
||||||
|
return ret_length
|
||||||
|
|
||||||
|
|
||||||
|
# check if we are in a worker or not
|
||||||
|
def is_in_browser_main_thread() -> bool:
|
||||||
|
return hasattr(js, "window") and hasattr(js, "self") and js.self == js.window
|
||||||
|
|
||||||
|
|
||||||
|
def is_cross_origin_isolated() -> bool:
|
||||||
|
return hasattr(js, "crossOriginIsolated") and js.crossOriginIsolated
|
||||||
|
|
||||||
|
|
||||||
|
def is_in_node() -> bool:
|
||||||
|
return (
|
||||||
|
hasattr(js, "process")
|
||||||
|
and hasattr(js.process, "release")
|
||||||
|
and hasattr(js.process.release, "name")
|
||||||
|
and js.process.release.name == "node"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def is_worker_available() -> bool:
|
||||||
|
return hasattr(js, "Worker") and hasattr(js, "Blob")
|
||||||
|
|
||||||
|
|
||||||
|
_fetcher: _StreamingFetcher | None = None
|
||||||
|
|
||||||
|
if is_worker_available() and (
|
||||||
|
(is_cross_origin_isolated() and not is_in_browser_main_thread())
|
||||||
|
and (not is_in_node())
|
||||||
|
):
|
||||||
|
_fetcher = _StreamingFetcher()
|
||||||
|
else:
|
||||||
|
_fetcher = None
|
||||||
|
|
||||||
|
|
||||||
|
NODE_JSPI_ERROR = (
|
||||||
|
"urllib3 only works in Node.js with pyodide.runPythonAsync"
|
||||||
|
" and requires the flag --experimental-wasm-stack-switching in "
|
||||||
|
" versions of node <24."
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def send_streaming_request(request: EmscriptenRequest) -> EmscriptenResponse | None:
|
||||||
|
if has_jspi():
|
||||||
|
return send_jspi_request(request, True)
|
||||||
|
elif is_in_node():
|
||||||
|
raise _RequestError(
|
||||||
|
message=NODE_JSPI_ERROR,
|
||||||
|
request=request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
|
||||||
|
if _fetcher and streaming_ready():
|
||||||
|
return _fetcher.send(request)
|
||||||
|
else:
|
||||||
|
_show_streaming_warning()
|
||||||
|
return None
|
||||||
|
|
||||||
|
|
||||||
|
_SHOWN_TIMEOUT_WARNING = False
|
||||||
|
|
||||||
|
|
||||||
|
def _show_timeout_warning() -> None:
|
||||||
|
global _SHOWN_TIMEOUT_WARNING
|
||||||
|
if not _SHOWN_TIMEOUT_WARNING:
|
||||||
|
_SHOWN_TIMEOUT_WARNING = True
|
||||||
|
message = "Warning: Timeout is not available on main browser thread"
|
||||||
|
js.console.warn(message)
|
||||||
|
|
||||||
|
|
||||||
|
_SHOWN_STREAMING_WARNING = False
|
||||||
|
|
||||||
|
|
||||||
|
def _show_streaming_warning() -> None:
|
||||||
|
global _SHOWN_STREAMING_WARNING
|
||||||
|
if not _SHOWN_STREAMING_WARNING:
|
||||||
|
_SHOWN_STREAMING_WARNING = True
|
||||||
|
message = "Can't stream HTTP requests because: \n"
|
||||||
|
if not is_cross_origin_isolated():
|
||||||
|
message += " Page is not cross-origin isolated\n"
|
||||||
|
if is_in_browser_main_thread():
|
||||||
|
message += " Python is running in main browser thread\n"
|
||||||
|
if not is_worker_available():
|
||||||
|
message += " Worker or Blob classes are not available in this environment." # Defensive: this is always False in browsers that we test in
|
||||||
|
if streaming_ready() is False:
|
||||||
|
message += """ Streaming fetch worker isn't ready. If you want to be sure that streaming fetch
|
||||||
|
is working, you need to call: 'await urllib3.contrib.emscripten.fetch.wait_for_streaming_ready()`"""
|
||||||
|
from js import console
|
||||||
|
|
||||||
|
console.warn(message)
|
||||||
|
|
||||||
|
|
||||||
|
def send_request(request: EmscriptenRequest) -> EmscriptenResponse:
|
||||||
|
if has_jspi():
|
||||||
|
return send_jspi_request(request, False)
|
||||||
|
elif is_in_node():
|
||||||
|
raise _RequestError(
|
||||||
|
message=NODE_JSPI_ERROR,
|
||||||
|
request=request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
try:
|
||||||
|
js_xhr = js.XMLHttpRequest.new()
|
||||||
|
|
||||||
|
if not is_in_browser_main_thread():
|
||||||
|
js_xhr.responseType = "arraybuffer"
|
||||||
|
if request.timeout:
|
||||||
|
js_xhr.timeout = int(request.timeout * 1000)
|
||||||
|
else:
|
||||||
|
js_xhr.overrideMimeType("text/plain; charset=ISO-8859-15")
|
||||||
|
if request.timeout:
|
||||||
|
# timeout isn't available on the main thread - show a warning in console
|
||||||
|
# if it is set
|
||||||
|
_show_timeout_warning()
|
||||||
|
|
||||||
|
js_xhr.open(request.method, request.url, False)
|
||||||
|
for name, value in request.headers.items():
|
||||||
|
if name.lower() not in HEADERS_TO_IGNORE:
|
||||||
|
js_xhr.setRequestHeader(name, value)
|
||||||
|
|
||||||
|
js_xhr.send(to_js(request.body))
|
||||||
|
|
||||||
|
headers = dict(Parser().parsestr(js_xhr.getAllResponseHeaders()))
|
||||||
|
|
||||||
|
if not is_in_browser_main_thread():
|
||||||
|
body = js_xhr.response.to_py().tobytes()
|
||||||
|
else:
|
||||||
|
body = js_xhr.response.encode("ISO-8859-15")
|
||||||
|
return EmscriptenResponse(
|
||||||
|
status_code=js_xhr.status, headers=headers, body=body, request=request
|
||||||
|
)
|
||||||
|
except JsException as err:
|
||||||
|
if err.name == "TimeoutError":
|
||||||
|
raise _TimeoutError(err.message, request=request)
|
||||||
|
elif err.name == "NetworkError":
|
||||||
|
raise _RequestError(err.message, request=request)
|
||||||
|
else:
|
||||||
|
# general http error
|
||||||
|
raise _RequestError(err.message, request=request)
|
||||||
|
|
||||||
|
|
||||||
|
def send_jspi_request(
|
||||||
|
request: EmscriptenRequest, streaming: bool
|
||||||
|
) -> EmscriptenResponse:
|
||||||
|
"""
|
||||||
|
Send a request using WebAssembly JavaScript Promise Integration
|
||||||
|
to wrap the asynchronous JavaScript fetch api (experimental).
|
||||||
|
|
||||||
|
:param request:
|
||||||
|
Request to send
|
||||||
|
|
||||||
|
:param streaming:
|
||||||
|
Whether to stream the response
|
||||||
|
|
||||||
|
:return: The response object
|
||||||
|
:rtype: EmscriptenResponse
|
||||||
|
"""
|
||||||
|
timeout = request.timeout
|
||||||
|
js_abort_controller = js.AbortController.new()
|
||||||
|
headers = {k: v for k, v in request.headers.items() if k not in HEADERS_TO_IGNORE}
|
||||||
|
req_body = request.body
|
||||||
|
fetch_data = {
|
||||||
|
"headers": headers,
|
||||||
|
"body": to_js(req_body),
|
||||||
|
"method": request.method,
|
||||||
|
"signal": js_abort_controller.signal,
|
||||||
|
}
|
||||||
|
# Node.js returns the whole response (unlike opaqueredirect in browsers),
|
||||||
|
# so urllib3 can set `redirect: manual` to control redirects itself.
|
||||||
|
# https://stackoverflow.com/a/78524615
|
||||||
|
if _is_node_js():
|
||||||
|
fetch_data["redirect"] = "manual"
|
||||||
|
# Call JavaScript fetch (async api, returns a promise)
|
||||||
|
fetcher_promise_js = js.fetch(request.url, _obj_from_dict(fetch_data))
|
||||||
|
# Now suspend WebAssembly until we resolve that promise
|
||||||
|
# or time out.
|
||||||
|
response_js = _run_sync_with_timeout(
|
||||||
|
fetcher_promise_js,
|
||||||
|
timeout,
|
||||||
|
js_abort_controller,
|
||||||
|
request=request,
|
||||||
|
response=None,
|
||||||
|
)
|
||||||
|
headers = {}
|
||||||
|
header_iter = response_js.headers.entries()
|
||||||
|
while True:
|
||||||
|
iter_value_js = header_iter.next()
|
||||||
|
if getattr(iter_value_js, "done", False):
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
headers[str(iter_value_js.value[0])] = str(iter_value_js.value[1])
|
||||||
|
status_code = response_js.status
|
||||||
|
body: bytes | io.RawIOBase = b""
|
||||||
|
|
||||||
|
response = EmscriptenResponse(
|
||||||
|
status_code=status_code, headers=headers, body=b"", request=request
|
||||||
|
)
|
||||||
|
if streaming:
|
||||||
|
# get via inputstream
|
||||||
|
if response_js.body is not None:
|
||||||
|
# get a reader from the fetch response
|
||||||
|
body_stream_js = response_js.body.getReader()
|
||||||
|
body = _JSPIReadStream(
|
||||||
|
body_stream_js, timeout, request, response, js_abort_controller
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
# get directly via arraybuffer
|
||||||
|
# n.b. this is another async JavaScript call.
|
||||||
|
body = _run_sync_with_timeout(
|
||||||
|
response_js.arrayBuffer(),
|
||||||
|
timeout,
|
||||||
|
js_abort_controller,
|
||||||
|
request=request,
|
||||||
|
response=response,
|
||||||
|
).to_py()
|
||||||
|
response.body = body
|
||||||
|
return response
|
||||||
|
|
||||||
|
|
||||||
|
def _run_sync_with_timeout(
|
||||||
|
promise: Any,
|
||||||
|
timeout: float,
|
||||||
|
js_abort_controller: Any,
|
||||||
|
request: EmscriptenRequest | None,
|
||||||
|
response: EmscriptenResponse | None,
|
||||||
|
) -> Any:
|
||||||
|
"""
|
||||||
|
Await a JavaScript promise synchronously with a timeout which is implemented
|
||||||
|
via the AbortController
|
||||||
|
|
||||||
|
:param promise:
|
||||||
|
Javascript promise to await
|
||||||
|
|
||||||
|
:param timeout:
|
||||||
|
Timeout in seconds
|
||||||
|
|
||||||
|
:param js_abort_controller:
|
||||||
|
A JavaScript AbortController object, used on timeout
|
||||||
|
|
||||||
|
:param request:
|
||||||
|
The request being handled
|
||||||
|
|
||||||
|
:param response:
|
||||||
|
The response being handled (if it exists yet)
|
||||||
|
|
||||||
|
:raises _TimeoutError: If the request times out
|
||||||
|
:raises _RequestError: If the request raises a JavaScript exception
|
||||||
|
|
||||||
|
:return: The result of awaiting the promise.
|
||||||
|
"""
|
||||||
|
timer_id = None
|
||||||
|
if timeout > 0:
|
||||||
|
timer_id = js.setTimeout(
|
||||||
|
js_abort_controller.abort.bind(js_abort_controller), int(timeout * 1000)
|
||||||
|
)
|
||||||
|
try:
|
||||||
|
from pyodide.ffi import run_sync
|
||||||
|
|
||||||
|
# run_sync here uses WebAssembly JavaScript Promise Integration to
|
||||||
|
# suspend python until the JavaScript promise resolves.
|
||||||
|
return run_sync(promise)
|
||||||
|
except JsException as err:
|
||||||
|
if err.name == "AbortError":
|
||||||
|
raise _TimeoutError(
|
||||||
|
message="Request timed out", request=request, response=response
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise _RequestError(message=err.message, request=request, response=response)
|
||||||
|
finally:
|
||||||
|
if timer_id is not None:
|
||||||
|
js.clearTimeout(timer_id)
|
||||||
|
|
||||||
|
|
||||||
|
def has_jspi() -> bool:
|
||||||
|
"""
|
||||||
|
Return true if jspi can be used.
|
||||||
|
|
||||||
|
This requires both browser support and also WebAssembly
|
||||||
|
to be in the correct state - i.e. that the javascript
|
||||||
|
call into python was async not sync.
|
||||||
|
|
||||||
|
:return: True if jspi can be used.
|
||||||
|
:rtype: bool
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
from pyodide.ffi import can_run_sync, run_sync # noqa: F401
|
||||||
|
|
||||||
|
return bool(can_run_sync())
|
||||||
|
except ImportError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def _is_node_js() -> bool:
|
||||||
|
"""
|
||||||
|
Check if we are in Node.js.
|
||||||
|
|
||||||
|
:return: True if we are in Node.js.
|
||||||
|
:rtype: bool
|
||||||
|
"""
|
||||||
|
return (
|
||||||
|
hasattr(js, "process")
|
||||||
|
and hasattr(js.process, "release")
|
||||||
|
# According to the Node.js documentation, the release name is always "node".
|
||||||
|
and js.process.release.name == "node"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def streaming_ready() -> bool | None:
|
||||||
|
if _fetcher:
|
||||||
|
return _fetcher.streaming_ready
|
||||||
|
else:
|
||||||
|
return None # no fetcher, return None to signify that
|
||||||
|
|
||||||
|
|
||||||
|
async def wait_for_streaming_ready() -> bool:
|
||||||
|
if _fetcher:
|
||||||
|
await _fetcher.js_worker_ready_promise
|
||||||
|
return True
|
||||||
|
else:
|
||||||
|
return False
|
||||||
@@ -0,0 +1,22 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from dataclasses import dataclass, field
|
||||||
|
|
||||||
|
from ..._base_connection import _TYPE_BODY
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class EmscriptenRequest:
|
||||||
|
method: str
|
||||||
|
url: str
|
||||||
|
params: dict[str, str] | None = None
|
||||||
|
body: _TYPE_BODY | None = None
|
||||||
|
headers: dict[str, str] = field(default_factory=dict)
|
||||||
|
timeout: float = 0
|
||||||
|
decode_content: bool = True
|
||||||
|
|
||||||
|
def set_header(self, name: str, value: str) -> None:
|
||||||
|
self.headers[name.capitalize()] = value
|
||||||
|
|
||||||
|
def set_body(self, body: _TYPE_BODY | None) -> None:
|
||||||
|
self.body = body
|
||||||
@@ -0,0 +1,277 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import json as _json
|
||||||
|
import logging
|
||||||
|
import typing
|
||||||
|
from contextlib import contextmanager
|
||||||
|
from dataclasses import dataclass
|
||||||
|
from http.client import HTTPException as HTTPException
|
||||||
|
from io import BytesIO, IOBase
|
||||||
|
|
||||||
|
from ...exceptions import InvalidHeader, TimeoutError
|
||||||
|
from ...response import BaseHTTPResponse
|
||||||
|
from ...util.retry import Retry
|
||||||
|
from .request import EmscriptenRequest
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from ..._base_connection import BaseHTTPConnection, BaseHTTPSConnection
|
||||||
|
|
||||||
|
log = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class EmscriptenResponse:
|
||||||
|
status_code: int
|
||||||
|
headers: dict[str, str]
|
||||||
|
body: IOBase | bytes
|
||||||
|
request: EmscriptenRequest
|
||||||
|
|
||||||
|
|
||||||
|
class EmscriptenHttpResponseWrapper(BaseHTTPResponse):
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
internal_response: EmscriptenResponse,
|
||||||
|
url: str | None = None,
|
||||||
|
connection: BaseHTTPConnection | BaseHTTPSConnection | None = None,
|
||||||
|
):
|
||||||
|
self._pool = None # set by pool class
|
||||||
|
self._body = None
|
||||||
|
self._response = internal_response
|
||||||
|
self._url = url
|
||||||
|
self._connection = connection
|
||||||
|
self._closed = False
|
||||||
|
super().__init__(
|
||||||
|
headers=internal_response.headers,
|
||||||
|
status=internal_response.status_code,
|
||||||
|
request_url=url,
|
||||||
|
version=0,
|
||||||
|
version_string="HTTP/?",
|
||||||
|
reason="",
|
||||||
|
decode_content=True,
|
||||||
|
)
|
||||||
|
self.length_remaining = self._init_length(self._response.request.method)
|
||||||
|
self.length_is_certain = False
|
||||||
|
|
||||||
|
@property
|
||||||
|
def url(self) -> str | None:
|
||||||
|
return self._url
|
||||||
|
|
||||||
|
@url.setter
|
||||||
|
def url(self, url: str | None) -> None:
|
||||||
|
self._url = url
|
||||||
|
|
||||||
|
@property
|
||||||
|
def connection(self) -> BaseHTTPConnection | BaseHTTPSConnection | None:
|
||||||
|
return self._connection
|
||||||
|
|
||||||
|
@property
|
||||||
|
def retries(self) -> Retry | None:
|
||||||
|
return self._retries
|
||||||
|
|
||||||
|
@retries.setter
|
||||||
|
def retries(self, retries: Retry | None) -> None:
|
||||||
|
# Override the request_url if retries has a redirect location.
|
||||||
|
self._retries = retries
|
||||||
|
|
||||||
|
def stream(
|
||||||
|
self, amt: int | None = 2**16, decode_content: bool | None = None
|
||||||
|
) -> typing.Generator[bytes]:
|
||||||
|
"""
|
||||||
|
A generator wrapper for the read() method. A call will block until
|
||||||
|
``amt`` bytes have been read from the connection or until the
|
||||||
|
connection is closed.
|
||||||
|
|
||||||
|
:param amt:
|
||||||
|
How much of the content to read. The generator will return up to
|
||||||
|
much data per iteration, but may return less. This is particularly
|
||||||
|
likely when using compressed data. However, the empty string will
|
||||||
|
never be returned.
|
||||||
|
|
||||||
|
:param decode_content:
|
||||||
|
If True, will attempt to decode the body based on the
|
||||||
|
'content-encoding' header.
|
||||||
|
"""
|
||||||
|
while True:
|
||||||
|
data = self.read(amt=amt, decode_content=decode_content)
|
||||||
|
|
||||||
|
if data:
|
||||||
|
yield data
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
|
||||||
|
def _init_length(self, request_method: str | None) -> int | None:
|
||||||
|
length: int | None
|
||||||
|
content_length: str | None = self.headers.get("content-length")
|
||||||
|
|
||||||
|
if content_length is not None:
|
||||||
|
try:
|
||||||
|
# RFC 7230 section 3.3.2 specifies multiple content lengths can
|
||||||
|
# be sent in a single Content-Length header
|
||||||
|
# (e.g. Content-Length: 42, 42). This line ensures the values
|
||||||
|
# are all valid ints and that as long as the `set` length is 1,
|
||||||
|
# all values are the same. Otherwise, the header is invalid.
|
||||||
|
lengths = {int(val) for val in content_length.split(",")}
|
||||||
|
if len(lengths) > 1:
|
||||||
|
raise InvalidHeader(
|
||||||
|
"Content-Length contained multiple "
|
||||||
|
"unmatching values (%s)" % content_length
|
||||||
|
)
|
||||||
|
length = lengths.pop()
|
||||||
|
except ValueError:
|
||||||
|
length = None
|
||||||
|
else:
|
||||||
|
if length < 0:
|
||||||
|
length = None
|
||||||
|
|
||||||
|
else: # if content_length is None
|
||||||
|
length = None
|
||||||
|
|
||||||
|
# Check for responses that shouldn't include a body
|
||||||
|
if (
|
||||||
|
self.status in (204, 304)
|
||||||
|
or 100 <= self.status < 200
|
||||||
|
or request_method == "HEAD"
|
||||||
|
):
|
||||||
|
length = 0
|
||||||
|
|
||||||
|
return length
|
||||||
|
|
||||||
|
def read(
|
||||||
|
self,
|
||||||
|
amt: int | None = None,
|
||||||
|
decode_content: bool | None = None, # ignored because browser decodes always
|
||||||
|
cache_content: bool = False,
|
||||||
|
) -> bytes:
|
||||||
|
if (
|
||||||
|
self._closed
|
||||||
|
or self._response is None
|
||||||
|
or (isinstance(self._response.body, IOBase) and self._response.body.closed)
|
||||||
|
):
|
||||||
|
return b""
|
||||||
|
|
||||||
|
with self._error_catcher():
|
||||||
|
# body has been preloaded as a string by XmlHttpRequest
|
||||||
|
if not isinstance(self._response.body, IOBase):
|
||||||
|
self.length_remaining = len(self._response.body)
|
||||||
|
self.length_is_certain = True
|
||||||
|
# wrap body in IOStream
|
||||||
|
self._response.body = BytesIO(self._response.body)
|
||||||
|
if amt is not None and amt >= 0:
|
||||||
|
# don't cache partial content
|
||||||
|
cache_content = False
|
||||||
|
data = self._response.body.read(amt)
|
||||||
|
else: # read all we can (and cache it)
|
||||||
|
data = self._response.body.read()
|
||||||
|
if cache_content:
|
||||||
|
self._body = data
|
||||||
|
if self.length_remaining is not None:
|
||||||
|
self.length_remaining = max(self.length_remaining - len(data), 0)
|
||||||
|
if len(data) == 0 or (
|
||||||
|
self.length_is_certain and self.length_remaining == 0
|
||||||
|
):
|
||||||
|
# definitely finished reading, close response stream
|
||||||
|
self._response.body.close()
|
||||||
|
return typing.cast(bytes, data)
|
||||||
|
|
||||||
|
def read_chunked(
|
||||||
|
self,
|
||||||
|
amt: int | None = None,
|
||||||
|
decode_content: bool | None = None,
|
||||||
|
) -> typing.Generator[bytes]:
|
||||||
|
# chunked is handled by browser
|
||||||
|
while True:
|
||||||
|
bytes = self.read(amt, decode_content)
|
||||||
|
if not bytes:
|
||||||
|
break
|
||||||
|
yield bytes
|
||||||
|
|
||||||
|
def release_conn(self) -> None:
|
||||||
|
if not self._pool or not self._connection:
|
||||||
|
return None
|
||||||
|
|
||||||
|
self._pool._put_conn(self._connection)
|
||||||
|
self._connection = None
|
||||||
|
|
||||||
|
def drain_conn(self) -> None:
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def data(self) -> bytes:
|
||||||
|
if self._body:
|
||||||
|
return self._body
|
||||||
|
else:
|
||||||
|
return self.read(cache_content=True)
|
||||||
|
|
||||||
|
def json(self) -> typing.Any:
|
||||||
|
"""
|
||||||
|
Deserializes the body of the HTTP response as a Python object.
|
||||||
|
|
||||||
|
The body of the HTTP response must be encoded using UTF-8, as per
|
||||||
|
`RFC 8529 Section 8.1 <https://www.rfc-editor.org/rfc/rfc8259#section-8.1>`_.
|
||||||
|
|
||||||
|
To use a custom JSON decoder pass the result of :attr:`HTTPResponse.data` to
|
||||||
|
your custom decoder instead.
|
||||||
|
|
||||||
|
If the body of the HTTP response is not decodable to UTF-8, a
|
||||||
|
`UnicodeDecodeError` will be raised. If the body of the HTTP response is not a
|
||||||
|
valid JSON document, a `json.JSONDecodeError` will be raised.
|
||||||
|
|
||||||
|
Read more :ref:`here <json_content>`.
|
||||||
|
|
||||||
|
:returns: The body of the HTTP response as a Python object.
|
||||||
|
"""
|
||||||
|
data = self.data.decode("utf-8")
|
||||||
|
return _json.loads(data)
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
if not self._closed:
|
||||||
|
if isinstance(self._response.body, IOBase):
|
||||||
|
self._response.body.close()
|
||||||
|
if self._connection:
|
||||||
|
self._connection.close()
|
||||||
|
self._connection = None
|
||||||
|
self._closed = True
|
||||||
|
|
||||||
|
@contextmanager
|
||||||
|
def _error_catcher(self) -> typing.Generator[None]:
|
||||||
|
"""
|
||||||
|
Catch Emscripten specific exceptions thrown by fetch.py,
|
||||||
|
instead re-raising urllib3 variants, so that low-level exceptions
|
||||||
|
are not leaked in the high-level api.
|
||||||
|
|
||||||
|
On exit, release the connection back to the pool.
|
||||||
|
"""
|
||||||
|
from .fetch import _RequestError, _TimeoutError # avoid circular import
|
||||||
|
|
||||||
|
clean_exit = False
|
||||||
|
|
||||||
|
try:
|
||||||
|
yield
|
||||||
|
# If no exception is thrown, we should avoid cleaning up
|
||||||
|
# unnecessarily.
|
||||||
|
clean_exit = True
|
||||||
|
except _TimeoutError as e:
|
||||||
|
raise TimeoutError(str(e))
|
||||||
|
except _RequestError as e:
|
||||||
|
raise HTTPException(str(e))
|
||||||
|
finally:
|
||||||
|
# If we didn't terminate cleanly, we need to throw away our
|
||||||
|
# connection.
|
||||||
|
if not clean_exit:
|
||||||
|
# The response may not be closed but we're not going to use it
|
||||||
|
# anymore so close it now
|
||||||
|
if (
|
||||||
|
isinstance(self._response.body, IOBase)
|
||||||
|
and not self._response.body.closed
|
||||||
|
):
|
||||||
|
self._response.body.close()
|
||||||
|
# release the connection back to the pool
|
||||||
|
self.release_conn()
|
||||||
|
else:
|
||||||
|
# If we have read everything from the response stream,
|
||||||
|
# return the connection back to the pool.
|
||||||
|
if (
|
||||||
|
isinstance(self._response.body, IOBase)
|
||||||
|
and self._response.body.closed
|
||||||
|
):
|
||||||
|
self.release_conn()
|
||||||
564
venv/lib/python3.12/site-packages/urllib3/contrib/pyopenssl.py
Normal file
564
venv/lib/python3.12/site-packages/urllib3/contrib/pyopenssl.py
Normal file
@@ -0,0 +1,564 @@
|
|||||||
|
"""
|
||||||
|
Module for using pyOpenSSL as a TLS backend. This module was relevant before
|
||||||
|
the standard library ``ssl`` module supported SNI, but now that we've dropped
|
||||||
|
support for Python 2.7 all relevant Python versions support SNI so
|
||||||
|
**this module is no longer recommended**.
|
||||||
|
|
||||||
|
This needs the following packages installed:
|
||||||
|
|
||||||
|
* `pyOpenSSL`_ (tested with 16.0.0)
|
||||||
|
* `cryptography`_ (minimum 1.3.4, from pyopenssl)
|
||||||
|
* `idna`_ (minimum 2.0)
|
||||||
|
|
||||||
|
However, pyOpenSSL depends on cryptography, so while we use all three directly here we
|
||||||
|
end up having relatively few packages required.
|
||||||
|
|
||||||
|
You can install them with the following command:
|
||||||
|
|
||||||
|
.. code-block:: bash
|
||||||
|
|
||||||
|
$ python -m pip install pyopenssl cryptography idna
|
||||||
|
|
||||||
|
To activate certificate checking, call
|
||||||
|
:func:`~urllib3.contrib.pyopenssl.inject_into_urllib3` from your Python code
|
||||||
|
before you begin making HTTP requests. This can be done in a ``sitecustomize``
|
||||||
|
module, or at any other time before your application begins using ``urllib3``,
|
||||||
|
like this:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
try:
|
||||||
|
import urllib3.contrib.pyopenssl
|
||||||
|
urllib3.contrib.pyopenssl.inject_into_urllib3()
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
.. _pyopenssl: https://www.pyopenssl.org
|
||||||
|
.. _cryptography: https://cryptography.io
|
||||||
|
.. _idna: https://github.com/kjd/idna
|
||||||
|
"""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import OpenSSL.SSL # type: ignore[import-untyped]
|
||||||
|
from cryptography import x509
|
||||||
|
|
||||||
|
try:
|
||||||
|
from cryptography.x509 import UnsupportedExtension # type: ignore[attr-defined]
|
||||||
|
except ImportError:
|
||||||
|
# UnsupportedExtension is gone in cryptography >= 2.1.0
|
||||||
|
class UnsupportedExtension(Exception): # type: ignore[no-redef]
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import ssl
|
||||||
|
import typing
|
||||||
|
from io import BytesIO
|
||||||
|
from socket import socket as socket_cls
|
||||||
|
from socket import timeout
|
||||||
|
|
||||||
|
from .. import util
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from OpenSSL.crypto import X509 # type: ignore[import-untyped]
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = ["inject_into_urllib3", "extract_from_urllib3"]
|
||||||
|
|
||||||
|
# Map from urllib3 to PyOpenSSL compatible parameter-values.
|
||||||
|
_openssl_versions: dict[int, int] = {
|
||||||
|
util.ssl_.PROTOCOL_TLS: OpenSSL.SSL.SSLv23_METHOD, # type: ignore[attr-defined]
|
||||||
|
util.ssl_.PROTOCOL_TLS_CLIENT: OpenSSL.SSL.SSLv23_METHOD, # type: ignore[attr-defined]
|
||||||
|
ssl.PROTOCOL_TLSv1: OpenSSL.SSL.TLSv1_METHOD,
|
||||||
|
}
|
||||||
|
|
||||||
|
if hasattr(ssl, "PROTOCOL_TLSv1_1") and hasattr(OpenSSL.SSL, "TLSv1_1_METHOD"):
|
||||||
|
_openssl_versions[ssl.PROTOCOL_TLSv1_1] = OpenSSL.SSL.TLSv1_1_METHOD
|
||||||
|
|
||||||
|
if hasattr(ssl, "PROTOCOL_TLSv1_2") and hasattr(OpenSSL.SSL, "TLSv1_2_METHOD"):
|
||||||
|
_openssl_versions[ssl.PROTOCOL_TLSv1_2] = OpenSSL.SSL.TLSv1_2_METHOD
|
||||||
|
|
||||||
|
|
||||||
|
_stdlib_to_openssl_verify = {
|
||||||
|
ssl.CERT_NONE: OpenSSL.SSL.VERIFY_NONE,
|
||||||
|
ssl.CERT_OPTIONAL: OpenSSL.SSL.VERIFY_PEER,
|
||||||
|
ssl.CERT_REQUIRED: OpenSSL.SSL.VERIFY_PEER
|
||||||
|
+ OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,
|
||||||
|
}
|
||||||
|
_openssl_to_stdlib_verify = {v: k for k, v in _stdlib_to_openssl_verify.items()}
|
||||||
|
|
||||||
|
# The SSLvX values are the most likely to be missing in the future
|
||||||
|
# but we check them all just to be sure.
|
||||||
|
_OP_NO_SSLv2_OR_SSLv3: int = getattr(OpenSSL.SSL, "OP_NO_SSLv2", 0) | getattr(
|
||||||
|
OpenSSL.SSL, "OP_NO_SSLv3", 0
|
||||||
|
)
|
||||||
|
_OP_NO_TLSv1: int = getattr(OpenSSL.SSL, "OP_NO_TLSv1", 0)
|
||||||
|
_OP_NO_TLSv1_1: int = getattr(OpenSSL.SSL, "OP_NO_TLSv1_1", 0)
|
||||||
|
_OP_NO_TLSv1_2: int = getattr(OpenSSL.SSL, "OP_NO_TLSv1_2", 0)
|
||||||
|
_OP_NO_TLSv1_3: int = getattr(OpenSSL.SSL, "OP_NO_TLSv1_3", 0)
|
||||||
|
|
||||||
|
_openssl_to_ssl_minimum_version: dict[int, int] = {
|
||||||
|
ssl.TLSVersion.MINIMUM_SUPPORTED: _OP_NO_SSLv2_OR_SSLv3,
|
||||||
|
ssl.TLSVersion.TLSv1: _OP_NO_SSLv2_OR_SSLv3,
|
||||||
|
ssl.TLSVersion.TLSv1_1: _OP_NO_SSLv2_OR_SSLv3 | _OP_NO_TLSv1,
|
||||||
|
ssl.TLSVersion.TLSv1_2: _OP_NO_SSLv2_OR_SSLv3 | _OP_NO_TLSv1 | _OP_NO_TLSv1_1,
|
||||||
|
ssl.TLSVersion.TLSv1_3: (
|
||||||
|
_OP_NO_SSLv2_OR_SSLv3 | _OP_NO_TLSv1 | _OP_NO_TLSv1_1 | _OP_NO_TLSv1_2
|
||||||
|
),
|
||||||
|
ssl.TLSVersion.MAXIMUM_SUPPORTED: (
|
||||||
|
_OP_NO_SSLv2_OR_SSLv3 | _OP_NO_TLSv1 | _OP_NO_TLSv1_1 | _OP_NO_TLSv1_2
|
||||||
|
),
|
||||||
|
}
|
||||||
|
_openssl_to_ssl_maximum_version: dict[int, int] = {
|
||||||
|
ssl.TLSVersion.MINIMUM_SUPPORTED: (
|
||||||
|
_OP_NO_SSLv2_OR_SSLv3
|
||||||
|
| _OP_NO_TLSv1
|
||||||
|
| _OP_NO_TLSv1_1
|
||||||
|
| _OP_NO_TLSv1_2
|
||||||
|
| _OP_NO_TLSv1_3
|
||||||
|
),
|
||||||
|
ssl.TLSVersion.TLSv1: (
|
||||||
|
_OP_NO_SSLv2_OR_SSLv3 | _OP_NO_TLSv1_1 | _OP_NO_TLSv1_2 | _OP_NO_TLSv1_3
|
||||||
|
),
|
||||||
|
ssl.TLSVersion.TLSv1_1: _OP_NO_SSLv2_OR_SSLv3 | _OP_NO_TLSv1_2 | _OP_NO_TLSv1_3,
|
||||||
|
ssl.TLSVersion.TLSv1_2: _OP_NO_SSLv2_OR_SSLv3 | _OP_NO_TLSv1_3,
|
||||||
|
ssl.TLSVersion.TLSv1_3: _OP_NO_SSLv2_OR_SSLv3,
|
||||||
|
ssl.TLSVersion.MAXIMUM_SUPPORTED: _OP_NO_SSLv2_OR_SSLv3,
|
||||||
|
}
|
||||||
|
|
||||||
|
# OpenSSL will only write 16K at a time
|
||||||
|
SSL_WRITE_BLOCKSIZE = 16384
|
||||||
|
|
||||||
|
orig_util_SSLContext = util.ssl_.SSLContext
|
||||||
|
|
||||||
|
|
||||||
|
log = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def inject_into_urllib3() -> None:
|
||||||
|
"Monkey-patch urllib3 with PyOpenSSL-backed SSL-support."
|
||||||
|
|
||||||
|
_validate_dependencies_met()
|
||||||
|
|
||||||
|
util.SSLContext = PyOpenSSLContext # type: ignore[assignment]
|
||||||
|
util.ssl_.SSLContext = PyOpenSSLContext # type: ignore[assignment]
|
||||||
|
util.IS_PYOPENSSL = True
|
||||||
|
util.ssl_.IS_PYOPENSSL = True
|
||||||
|
|
||||||
|
|
||||||
|
def extract_from_urllib3() -> None:
|
||||||
|
"Undo monkey-patching by :func:`inject_into_urllib3`."
|
||||||
|
|
||||||
|
util.SSLContext = orig_util_SSLContext
|
||||||
|
util.ssl_.SSLContext = orig_util_SSLContext
|
||||||
|
util.IS_PYOPENSSL = False
|
||||||
|
util.ssl_.IS_PYOPENSSL = False
|
||||||
|
|
||||||
|
|
||||||
|
def _validate_dependencies_met() -> None:
|
||||||
|
"""
|
||||||
|
Verifies that PyOpenSSL's package-level dependencies have been met.
|
||||||
|
Throws `ImportError` if they are not met.
|
||||||
|
"""
|
||||||
|
# Method added in `cryptography==1.1`; not available in older versions
|
||||||
|
from cryptography.x509.extensions import Extensions
|
||||||
|
|
||||||
|
if getattr(Extensions, "get_extension_for_class", None) is None:
|
||||||
|
raise ImportError(
|
||||||
|
"'cryptography' module missing required functionality. "
|
||||||
|
"Try upgrading to v1.3.4 or newer."
|
||||||
|
)
|
||||||
|
|
||||||
|
# pyOpenSSL 0.14 and above use cryptography for OpenSSL bindings. The _x509
|
||||||
|
# attribute is only present on those versions.
|
||||||
|
from OpenSSL.crypto import X509
|
||||||
|
|
||||||
|
x509 = X509()
|
||||||
|
if getattr(x509, "_x509", None) is None:
|
||||||
|
raise ImportError(
|
||||||
|
"'pyOpenSSL' module missing required functionality. "
|
||||||
|
"Try upgrading to v0.14 or newer."
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def _dnsname_to_stdlib(name: str) -> str | None:
|
||||||
|
"""
|
||||||
|
Converts a dNSName SubjectAlternativeName field to the form used by the
|
||||||
|
standard library on the given Python version.
|
||||||
|
|
||||||
|
Cryptography produces a dNSName as a unicode string that was idna-decoded
|
||||||
|
from ASCII bytes. We need to idna-encode that string to get it back, and
|
||||||
|
then on Python 3 we also need to convert to unicode via UTF-8 (the stdlib
|
||||||
|
uses PyUnicode_FromStringAndSize on it, which decodes via UTF-8).
|
||||||
|
|
||||||
|
If the name cannot be idna-encoded then we return None signalling that
|
||||||
|
the name given should be skipped.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def idna_encode(name: str) -> bytes | None:
|
||||||
|
"""
|
||||||
|
Borrowed wholesale from the Python Cryptography Project. It turns out
|
||||||
|
that we can't just safely call `idna.encode`: it can explode for
|
||||||
|
wildcard names. This avoids that problem.
|
||||||
|
"""
|
||||||
|
import idna
|
||||||
|
|
||||||
|
try:
|
||||||
|
for prefix in ["*.", "."]:
|
||||||
|
if name.startswith(prefix):
|
||||||
|
name = name[len(prefix) :]
|
||||||
|
return prefix.encode("ascii") + idna.encode(name)
|
||||||
|
return idna.encode(name)
|
||||||
|
except idna.core.IDNAError:
|
||||||
|
return None
|
||||||
|
|
||||||
|
# Don't send IPv6 addresses through the IDNA encoder.
|
||||||
|
if ":" in name:
|
||||||
|
return name
|
||||||
|
|
||||||
|
encoded_name = idna_encode(name)
|
||||||
|
if encoded_name is None:
|
||||||
|
return None
|
||||||
|
return encoded_name.decode("utf-8")
|
||||||
|
|
||||||
|
|
||||||
|
def get_subj_alt_name(peer_cert: X509) -> list[tuple[str, str]]:
|
||||||
|
"""
|
||||||
|
Given an PyOpenSSL certificate, provides all the subject alternative names.
|
||||||
|
"""
|
||||||
|
cert = peer_cert.to_cryptography()
|
||||||
|
|
||||||
|
# We want to find the SAN extension. Ask Cryptography to locate it (it's
|
||||||
|
# faster than looping in Python)
|
||||||
|
try:
|
||||||
|
ext = cert.extensions.get_extension_for_class(x509.SubjectAlternativeName).value
|
||||||
|
except x509.ExtensionNotFound:
|
||||||
|
# No such extension, return the empty list.
|
||||||
|
return []
|
||||||
|
except (
|
||||||
|
x509.DuplicateExtension,
|
||||||
|
UnsupportedExtension,
|
||||||
|
x509.UnsupportedGeneralNameType,
|
||||||
|
UnicodeError,
|
||||||
|
) as e:
|
||||||
|
# A problem has been found with the quality of the certificate. Assume
|
||||||
|
# no SAN field is present.
|
||||||
|
log.warning(
|
||||||
|
"A problem was encountered with the certificate that prevented "
|
||||||
|
"urllib3 from finding the SubjectAlternativeName field. This can "
|
||||||
|
"affect certificate validation. The error was %s",
|
||||||
|
e,
|
||||||
|
)
|
||||||
|
return []
|
||||||
|
|
||||||
|
# We want to return dNSName and iPAddress fields. We need to cast the IPs
|
||||||
|
# back to strings because the match_hostname function wants them as
|
||||||
|
# strings.
|
||||||
|
# Sadly the DNS names need to be idna encoded and then, on Python 3, UTF-8
|
||||||
|
# decoded. This is pretty frustrating, but that's what the standard library
|
||||||
|
# does with certificates, and so we need to attempt to do the same.
|
||||||
|
# We also want to skip over names which cannot be idna encoded.
|
||||||
|
names = [
|
||||||
|
("DNS", name)
|
||||||
|
for name in map(_dnsname_to_stdlib, ext.get_values_for_type(x509.DNSName))
|
||||||
|
if name is not None
|
||||||
|
]
|
||||||
|
names.extend(
|
||||||
|
("IP Address", str(name)) for name in ext.get_values_for_type(x509.IPAddress)
|
||||||
|
)
|
||||||
|
|
||||||
|
return names
|
||||||
|
|
||||||
|
|
||||||
|
class WrappedSocket:
|
||||||
|
"""API-compatibility wrapper for Python OpenSSL's Connection-class."""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
connection: OpenSSL.SSL.Connection,
|
||||||
|
socket: socket_cls,
|
||||||
|
suppress_ragged_eofs: bool = True,
|
||||||
|
) -> None:
|
||||||
|
self.connection = connection
|
||||||
|
self.socket = socket
|
||||||
|
self.suppress_ragged_eofs = suppress_ragged_eofs
|
||||||
|
self._io_refs = 0
|
||||||
|
self._closed = False
|
||||||
|
|
||||||
|
def fileno(self) -> int:
|
||||||
|
return self.socket.fileno()
|
||||||
|
|
||||||
|
# Copy-pasted from Python 3.5 source code
|
||||||
|
def _decref_socketios(self) -> None:
|
||||||
|
if self._io_refs > 0:
|
||||||
|
self._io_refs -= 1
|
||||||
|
if self._closed:
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
def recv(self, *args: typing.Any, **kwargs: typing.Any) -> bytes:
|
||||||
|
try:
|
||||||
|
data = self.connection.recv(*args, **kwargs)
|
||||||
|
except OpenSSL.SSL.SysCallError as e:
|
||||||
|
if self.suppress_ragged_eofs and e.args == (-1, "Unexpected EOF"):
|
||||||
|
return b""
|
||||||
|
else:
|
||||||
|
raise OSError(e.args[0], str(e)) from e
|
||||||
|
except OpenSSL.SSL.ZeroReturnError:
|
||||||
|
if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:
|
||||||
|
return b""
|
||||||
|
else:
|
||||||
|
raise
|
||||||
|
except OpenSSL.SSL.WantReadError as e:
|
||||||
|
if not util.wait_for_read(self.socket, self.socket.gettimeout()):
|
||||||
|
raise timeout("The read operation timed out") from e
|
||||||
|
else:
|
||||||
|
return self.recv(*args, **kwargs)
|
||||||
|
|
||||||
|
# TLS 1.3 post-handshake authentication
|
||||||
|
except OpenSSL.SSL.Error as e:
|
||||||
|
raise ssl.SSLError(f"read error: {e!r}") from e
|
||||||
|
else:
|
||||||
|
return data # type: ignore[no-any-return]
|
||||||
|
|
||||||
|
def recv_into(self, *args: typing.Any, **kwargs: typing.Any) -> int:
|
||||||
|
try:
|
||||||
|
return self.connection.recv_into(*args, **kwargs) # type: ignore[no-any-return]
|
||||||
|
except OpenSSL.SSL.SysCallError as e:
|
||||||
|
if self.suppress_ragged_eofs and e.args == (-1, "Unexpected EOF"):
|
||||||
|
return 0
|
||||||
|
else:
|
||||||
|
raise OSError(e.args[0], str(e)) from e
|
||||||
|
except OpenSSL.SSL.ZeroReturnError:
|
||||||
|
if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:
|
||||||
|
return 0
|
||||||
|
else:
|
||||||
|
raise
|
||||||
|
except OpenSSL.SSL.WantReadError as e:
|
||||||
|
if not util.wait_for_read(self.socket, self.socket.gettimeout()):
|
||||||
|
raise timeout("The read operation timed out") from e
|
||||||
|
else:
|
||||||
|
return self.recv_into(*args, **kwargs)
|
||||||
|
|
||||||
|
# TLS 1.3 post-handshake authentication
|
||||||
|
except OpenSSL.SSL.Error as e:
|
||||||
|
raise ssl.SSLError(f"read error: {e!r}") from e
|
||||||
|
|
||||||
|
def settimeout(self, timeout: float) -> None:
|
||||||
|
return self.socket.settimeout(timeout)
|
||||||
|
|
||||||
|
def _send_until_done(self, data: bytes) -> int:
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
return self.connection.send(data) # type: ignore[no-any-return]
|
||||||
|
except OpenSSL.SSL.WantWriteError as e:
|
||||||
|
if not util.wait_for_write(self.socket, self.socket.gettimeout()):
|
||||||
|
raise timeout() from e
|
||||||
|
continue
|
||||||
|
except OpenSSL.SSL.SysCallError as e:
|
||||||
|
raise OSError(e.args[0], str(e)) from e
|
||||||
|
|
||||||
|
def sendall(self, data: bytes) -> None:
|
||||||
|
total_sent = 0
|
||||||
|
while total_sent < len(data):
|
||||||
|
sent = self._send_until_done(
|
||||||
|
data[total_sent : total_sent + SSL_WRITE_BLOCKSIZE]
|
||||||
|
)
|
||||||
|
total_sent += sent
|
||||||
|
|
||||||
|
def shutdown(self, how: int) -> None:
|
||||||
|
try:
|
||||||
|
self.connection.shutdown()
|
||||||
|
except OpenSSL.SSL.Error as e:
|
||||||
|
raise ssl.SSLError(f"shutdown error: {e!r}") from e
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
self._closed = True
|
||||||
|
if self._io_refs <= 0:
|
||||||
|
self._real_close()
|
||||||
|
|
||||||
|
def _real_close(self) -> None:
|
||||||
|
try:
|
||||||
|
return self.connection.close() # type: ignore[no-any-return]
|
||||||
|
except OpenSSL.SSL.Error:
|
||||||
|
return
|
||||||
|
|
||||||
|
def getpeercert(
|
||||||
|
self, binary_form: bool = False
|
||||||
|
) -> dict[str, list[typing.Any]] | None:
|
||||||
|
x509 = self.connection.get_peer_certificate()
|
||||||
|
|
||||||
|
if not x509:
|
||||||
|
return x509 # type: ignore[no-any-return]
|
||||||
|
|
||||||
|
if binary_form:
|
||||||
|
return OpenSSL.crypto.dump_certificate(OpenSSL.crypto.FILETYPE_ASN1, x509) # type: ignore[no-any-return]
|
||||||
|
|
||||||
|
return {
|
||||||
|
"subject": ((("commonName", x509.get_subject().CN),),), # type: ignore[dict-item]
|
||||||
|
"subjectAltName": get_subj_alt_name(x509),
|
||||||
|
}
|
||||||
|
|
||||||
|
def version(self) -> str:
|
||||||
|
return self.connection.get_protocol_version_name() # type: ignore[no-any-return]
|
||||||
|
|
||||||
|
def selected_alpn_protocol(self) -> str | None:
|
||||||
|
alpn_proto = self.connection.get_alpn_proto_negotiated()
|
||||||
|
return alpn_proto.decode() if alpn_proto else None
|
||||||
|
|
||||||
|
|
||||||
|
WrappedSocket.makefile = socket_cls.makefile # type: ignore[attr-defined]
|
||||||
|
|
||||||
|
|
||||||
|
class PyOpenSSLContext:
|
||||||
|
"""
|
||||||
|
I am a wrapper class for the PyOpenSSL ``Context`` object. I am responsible
|
||||||
|
for translating the interface of the standard library ``SSLContext`` object
|
||||||
|
to calls into PyOpenSSL.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, protocol: int) -> None:
|
||||||
|
self.protocol = _openssl_versions[protocol]
|
||||||
|
self._ctx = OpenSSL.SSL.Context(self.protocol)
|
||||||
|
self._options = 0
|
||||||
|
self.check_hostname = False
|
||||||
|
self._minimum_version: int = ssl.TLSVersion.MINIMUM_SUPPORTED
|
||||||
|
self._maximum_version: int = ssl.TLSVersion.MAXIMUM_SUPPORTED
|
||||||
|
self._verify_flags: int = ssl.VERIFY_X509_TRUSTED_FIRST
|
||||||
|
|
||||||
|
@property
|
||||||
|
def options(self) -> int:
|
||||||
|
return self._options
|
||||||
|
|
||||||
|
@options.setter
|
||||||
|
def options(self, value: int) -> None:
|
||||||
|
self._options = value
|
||||||
|
self._set_ctx_options()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def verify_flags(self) -> int:
|
||||||
|
return self._verify_flags
|
||||||
|
|
||||||
|
@verify_flags.setter
|
||||||
|
def verify_flags(self, value: int) -> None:
|
||||||
|
self._verify_flags = value
|
||||||
|
self._ctx.get_cert_store().set_flags(self._verify_flags)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def verify_mode(self) -> int:
|
||||||
|
return _openssl_to_stdlib_verify[self._ctx.get_verify_mode()]
|
||||||
|
|
||||||
|
@verify_mode.setter
|
||||||
|
def verify_mode(self, value: ssl.VerifyMode) -> None:
|
||||||
|
self._ctx.set_verify(_stdlib_to_openssl_verify[value], _verify_callback)
|
||||||
|
|
||||||
|
def set_default_verify_paths(self) -> None:
|
||||||
|
self._ctx.set_default_verify_paths()
|
||||||
|
|
||||||
|
def set_ciphers(self, ciphers: bytes | str) -> None:
|
||||||
|
if isinstance(ciphers, str):
|
||||||
|
ciphers = ciphers.encode("utf-8")
|
||||||
|
self._ctx.set_cipher_list(ciphers)
|
||||||
|
|
||||||
|
def load_verify_locations(
|
||||||
|
self,
|
||||||
|
cafile: str | None = None,
|
||||||
|
capath: str | None = None,
|
||||||
|
cadata: bytes | None = None,
|
||||||
|
) -> None:
|
||||||
|
if cafile is not None:
|
||||||
|
cafile = cafile.encode("utf-8") # type: ignore[assignment]
|
||||||
|
if capath is not None:
|
||||||
|
capath = capath.encode("utf-8") # type: ignore[assignment]
|
||||||
|
try:
|
||||||
|
self._ctx.load_verify_locations(cafile, capath)
|
||||||
|
if cadata is not None:
|
||||||
|
self._ctx.load_verify_locations(BytesIO(cadata))
|
||||||
|
except OpenSSL.SSL.Error as e:
|
||||||
|
raise ssl.SSLError(f"unable to load trusted certificates: {e!r}") from e
|
||||||
|
|
||||||
|
def load_cert_chain(
|
||||||
|
self,
|
||||||
|
certfile: str,
|
||||||
|
keyfile: str | None = None,
|
||||||
|
password: str | None = None,
|
||||||
|
) -> None:
|
||||||
|
try:
|
||||||
|
self._ctx.use_certificate_chain_file(certfile)
|
||||||
|
if password is not None:
|
||||||
|
if not isinstance(password, bytes):
|
||||||
|
password = password.encode("utf-8") # type: ignore[assignment]
|
||||||
|
self._ctx.set_passwd_cb(lambda *_: password)
|
||||||
|
self._ctx.use_privatekey_file(keyfile or certfile)
|
||||||
|
except OpenSSL.SSL.Error as e:
|
||||||
|
raise ssl.SSLError(f"Unable to load certificate chain: {e!r}") from e
|
||||||
|
|
||||||
|
def set_alpn_protocols(self, protocols: list[bytes | str]) -> None:
|
||||||
|
protocols = [util.util.to_bytes(p, "ascii") for p in protocols]
|
||||||
|
return self._ctx.set_alpn_protos(protocols) # type: ignore[no-any-return]
|
||||||
|
|
||||||
|
def wrap_socket(
|
||||||
|
self,
|
||||||
|
sock: socket_cls,
|
||||||
|
server_side: bool = False,
|
||||||
|
do_handshake_on_connect: bool = True,
|
||||||
|
suppress_ragged_eofs: bool = True,
|
||||||
|
server_hostname: bytes | str | None = None,
|
||||||
|
) -> WrappedSocket:
|
||||||
|
cnx = OpenSSL.SSL.Connection(self._ctx, sock)
|
||||||
|
|
||||||
|
# If server_hostname is an IP, don't use it for SNI, per RFC6066 Section 3
|
||||||
|
if server_hostname and not util.ssl_.is_ipaddress(server_hostname):
|
||||||
|
if isinstance(server_hostname, str):
|
||||||
|
server_hostname = server_hostname.encode("utf-8")
|
||||||
|
cnx.set_tlsext_host_name(server_hostname)
|
||||||
|
|
||||||
|
cnx.set_connect_state()
|
||||||
|
|
||||||
|
while True:
|
||||||
|
try:
|
||||||
|
cnx.do_handshake()
|
||||||
|
except OpenSSL.SSL.WantReadError as e:
|
||||||
|
if not util.wait_for_read(sock, sock.gettimeout()):
|
||||||
|
raise timeout("select timed out") from e
|
||||||
|
continue
|
||||||
|
except OpenSSL.SSL.Error as e:
|
||||||
|
raise ssl.SSLError(f"bad handshake: {e!r}") from e
|
||||||
|
break
|
||||||
|
|
||||||
|
return WrappedSocket(cnx, sock)
|
||||||
|
|
||||||
|
def _set_ctx_options(self) -> None:
|
||||||
|
self._ctx.set_options(
|
||||||
|
self._options
|
||||||
|
| _openssl_to_ssl_minimum_version[self._minimum_version]
|
||||||
|
| _openssl_to_ssl_maximum_version[self._maximum_version]
|
||||||
|
)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def minimum_version(self) -> int:
|
||||||
|
return self._minimum_version
|
||||||
|
|
||||||
|
@minimum_version.setter
|
||||||
|
def minimum_version(self, minimum_version: int) -> None:
|
||||||
|
self._minimum_version = minimum_version
|
||||||
|
self._set_ctx_options()
|
||||||
|
|
||||||
|
@property
|
||||||
|
def maximum_version(self) -> int:
|
||||||
|
return self._maximum_version
|
||||||
|
|
||||||
|
@maximum_version.setter
|
||||||
|
def maximum_version(self, maximum_version: int) -> None:
|
||||||
|
self._maximum_version = maximum_version
|
||||||
|
self._set_ctx_options()
|
||||||
|
|
||||||
|
|
||||||
|
def _verify_callback(
|
||||||
|
cnx: OpenSSL.SSL.Connection,
|
||||||
|
x509: X509,
|
||||||
|
err_no: int,
|
||||||
|
err_depth: int,
|
||||||
|
return_code: int,
|
||||||
|
) -> bool:
|
||||||
|
return err_no == 0
|
||||||
228
venv/lib/python3.12/site-packages/urllib3/contrib/socks.py
Normal file
228
venv/lib/python3.12/site-packages/urllib3/contrib/socks.py
Normal file
@@ -0,0 +1,228 @@
|
|||||||
|
"""
|
||||||
|
This module contains provisional support for SOCKS proxies from within
|
||||||
|
urllib3. This module supports SOCKS4, SOCKS4A (an extension of SOCKS4), and
|
||||||
|
SOCKS5. To enable its functionality, either install PySocks or install this
|
||||||
|
module with the ``socks`` extra.
|
||||||
|
|
||||||
|
The SOCKS implementation supports the full range of urllib3 features. It also
|
||||||
|
supports the following SOCKS features:
|
||||||
|
|
||||||
|
- SOCKS4A (``proxy_url='socks4a://...``)
|
||||||
|
- SOCKS4 (``proxy_url='socks4://...``)
|
||||||
|
- SOCKS5 with remote DNS (``proxy_url='socks5h://...``)
|
||||||
|
- SOCKS5 with local DNS (``proxy_url='socks5://...``)
|
||||||
|
- Usernames and passwords for the SOCKS proxy
|
||||||
|
|
||||||
|
.. note::
|
||||||
|
It is recommended to use ``socks5h://`` or ``socks4a://`` schemes in
|
||||||
|
your ``proxy_url`` to ensure that DNS resolution is done from the remote
|
||||||
|
server instead of client-side when connecting to a domain name.
|
||||||
|
|
||||||
|
SOCKS4 supports IPv4 and domain names with the SOCKS4A extension. SOCKS5
|
||||||
|
supports IPv4, IPv6, and domain names.
|
||||||
|
|
||||||
|
When connecting to a SOCKS4 proxy the ``username`` portion of the ``proxy_url``
|
||||||
|
will be sent as the ``userid`` section of the SOCKS request:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
proxy_url="socks4a://<userid>@proxy-host"
|
||||||
|
|
||||||
|
When connecting to a SOCKS5 proxy the ``username`` and ``password`` portion
|
||||||
|
of the ``proxy_url`` will be sent as the username/password to authenticate
|
||||||
|
with the proxy:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
proxy_url="socks5h://<username>:<password>@proxy-host"
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
try:
|
||||||
|
import socks # type: ignore[import-not-found]
|
||||||
|
except ImportError:
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
from ..exceptions import DependencyWarning
|
||||||
|
|
||||||
|
warnings.warn(
|
||||||
|
(
|
||||||
|
"SOCKS support in urllib3 requires the installation of optional "
|
||||||
|
"dependencies: specifically, PySocks. For more information, see "
|
||||||
|
"https://urllib3.readthedocs.io/en/latest/advanced-usage.html#socks-proxies"
|
||||||
|
),
|
||||||
|
DependencyWarning,
|
||||||
|
)
|
||||||
|
raise
|
||||||
|
|
||||||
|
import typing
|
||||||
|
from socket import timeout as SocketTimeout
|
||||||
|
|
||||||
|
from ..connection import HTTPConnection, HTTPSConnection
|
||||||
|
from ..connectionpool import HTTPConnectionPool, HTTPSConnectionPool
|
||||||
|
from ..exceptions import ConnectTimeoutError, NewConnectionError
|
||||||
|
from ..poolmanager import PoolManager
|
||||||
|
from ..util.url import parse_url
|
||||||
|
|
||||||
|
try:
|
||||||
|
import ssl
|
||||||
|
except ImportError:
|
||||||
|
ssl = None # type: ignore[assignment]
|
||||||
|
|
||||||
|
|
||||||
|
class _TYPE_SOCKS_OPTIONS(typing.TypedDict):
|
||||||
|
socks_version: int
|
||||||
|
proxy_host: str | None
|
||||||
|
proxy_port: str | None
|
||||||
|
username: str | None
|
||||||
|
password: str | None
|
||||||
|
rdns: bool
|
||||||
|
|
||||||
|
|
||||||
|
class SOCKSConnection(HTTPConnection):
|
||||||
|
"""
|
||||||
|
A plain-text HTTP connection that connects via a SOCKS proxy.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
_socks_options: _TYPE_SOCKS_OPTIONS,
|
||||||
|
*args: typing.Any,
|
||||||
|
**kwargs: typing.Any,
|
||||||
|
) -> None:
|
||||||
|
self._socks_options = _socks_options
|
||||||
|
super().__init__(*args, **kwargs)
|
||||||
|
|
||||||
|
def _new_conn(self) -> socks.socksocket:
|
||||||
|
"""
|
||||||
|
Establish a new connection via the SOCKS proxy.
|
||||||
|
"""
|
||||||
|
extra_kw: dict[str, typing.Any] = {}
|
||||||
|
if self.source_address:
|
||||||
|
extra_kw["source_address"] = self.source_address
|
||||||
|
|
||||||
|
if self.socket_options:
|
||||||
|
extra_kw["socket_options"] = self.socket_options
|
||||||
|
|
||||||
|
try:
|
||||||
|
conn = socks.create_connection(
|
||||||
|
(self.host, self.port),
|
||||||
|
proxy_type=self._socks_options["socks_version"],
|
||||||
|
proxy_addr=self._socks_options["proxy_host"],
|
||||||
|
proxy_port=self._socks_options["proxy_port"],
|
||||||
|
proxy_username=self._socks_options["username"],
|
||||||
|
proxy_password=self._socks_options["password"],
|
||||||
|
proxy_rdns=self._socks_options["rdns"],
|
||||||
|
timeout=self.timeout,
|
||||||
|
**extra_kw,
|
||||||
|
)
|
||||||
|
|
||||||
|
except SocketTimeout as e:
|
||||||
|
raise ConnectTimeoutError(
|
||||||
|
self,
|
||||||
|
f"Connection to {self.host} timed out. (connect timeout={self.timeout})",
|
||||||
|
) from e
|
||||||
|
|
||||||
|
except socks.ProxyError as e:
|
||||||
|
# This is fragile as hell, but it seems to be the only way to raise
|
||||||
|
# useful errors here.
|
||||||
|
if e.socket_err:
|
||||||
|
error = e.socket_err
|
||||||
|
if isinstance(error, SocketTimeout):
|
||||||
|
raise ConnectTimeoutError(
|
||||||
|
self,
|
||||||
|
f"Connection to {self.host} timed out. (connect timeout={self.timeout})",
|
||||||
|
) from e
|
||||||
|
else:
|
||||||
|
# Adding `from e` messes with coverage somehow, so it's omitted.
|
||||||
|
# See #2386.
|
||||||
|
raise NewConnectionError(
|
||||||
|
self, f"Failed to establish a new connection: {error}"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise NewConnectionError(
|
||||||
|
self, f"Failed to establish a new connection: {e}"
|
||||||
|
) from e
|
||||||
|
|
||||||
|
except OSError as e: # Defensive: PySocks should catch all these.
|
||||||
|
raise NewConnectionError(
|
||||||
|
self, f"Failed to establish a new connection: {e}"
|
||||||
|
) from e
|
||||||
|
|
||||||
|
return conn
|
||||||
|
|
||||||
|
|
||||||
|
# We don't need to duplicate the Verified/Unverified distinction from
|
||||||
|
# urllib3/connection.py here because the HTTPSConnection will already have been
|
||||||
|
# correctly set to either the Verified or Unverified form by that module. This
|
||||||
|
# means the SOCKSHTTPSConnection will automatically be the correct type.
|
||||||
|
class SOCKSHTTPSConnection(SOCKSConnection, HTTPSConnection):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class SOCKSHTTPConnectionPool(HTTPConnectionPool):
|
||||||
|
ConnectionCls = SOCKSConnection
|
||||||
|
|
||||||
|
|
||||||
|
class SOCKSHTTPSConnectionPool(HTTPSConnectionPool):
|
||||||
|
ConnectionCls = SOCKSHTTPSConnection
|
||||||
|
|
||||||
|
|
||||||
|
class SOCKSProxyManager(PoolManager):
|
||||||
|
"""
|
||||||
|
A version of the urllib3 ProxyManager that routes connections via the
|
||||||
|
defined SOCKS proxy.
|
||||||
|
"""
|
||||||
|
|
||||||
|
pool_classes_by_scheme = {
|
||||||
|
"http": SOCKSHTTPConnectionPool,
|
||||||
|
"https": SOCKSHTTPSConnectionPool,
|
||||||
|
}
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
proxy_url: str,
|
||||||
|
username: str | None = None,
|
||||||
|
password: str | None = None,
|
||||||
|
num_pools: int = 10,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
**connection_pool_kw: typing.Any,
|
||||||
|
):
|
||||||
|
parsed = parse_url(proxy_url)
|
||||||
|
|
||||||
|
if username is None and password is None and parsed.auth is not None:
|
||||||
|
split = parsed.auth.split(":")
|
||||||
|
if len(split) == 2:
|
||||||
|
username, password = split
|
||||||
|
if parsed.scheme == "socks5":
|
||||||
|
socks_version = socks.PROXY_TYPE_SOCKS5
|
||||||
|
rdns = False
|
||||||
|
elif parsed.scheme == "socks5h":
|
||||||
|
socks_version = socks.PROXY_TYPE_SOCKS5
|
||||||
|
rdns = True
|
||||||
|
elif parsed.scheme == "socks4":
|
||||||
|
socks_version = socks.PROXY_TYPE_SOCKS4
|
||||||
|
rdns = False
|
||||||
|
elif parsed.scheme == "socks4a":
|
||||||
|
socks_version = socks.PROXY_TYPE_SOCKS4
|
||||||
|
rdns = True
|
||||||
|
else:
|
||||||
|
raise ValueError(f"Unable to determine SOCKS version from {proxy_url}")
|
||||||
|
|
||||||
|
self.proxy_url = proxy_url
|
||||||
|
|
||||||
|
socks_options = {
|
||||||
|
"socks_version": socks_version,
|
||||||
|
"proxy_host": parsed.host,
|
||||||
|
"proxy_port": parsed.port,
|
||||||
|
"username": username,
|
||||||
|
"password": password,
|
||||||
|
"rdns": rdns,
|
||||||
|
}
|
||||||
|
connection_pool_kw["_socks_options"] = socks_options
|
||||||
|
|
||||||
|
super().__init__(num_pools, headers, **connection_pool_kw)
|
||||||
|
|
||||||
|
self.pool_classes_by_scheme = SOCKSProxyManager.pool_classes_by_scheme
|
||||||
335
venv/lib/python3.12/site-packages/urllib3/exceptions.py
Normal file
335
venv/lib/python3.12/site-packages/urllib3/exceptions.py
Normal file
@@ -0,0 +1,335 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import socket
|
||||||
|
import typing
|
||||||
|
import warnings
|
||||||
|
from email.errors import MessageDefect
|
||||||
|
from http.client import IncompleteRead as httplib_IncompleteRead
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from .connection import HTTPConnection
|
||||||
|
from .connectionpool import ConnectionPool
|
||||||
|
from .response import HTTPResponse
|
||||||
|
from .util.retry import Retry
|
||||||
|
|
||||||
|
# Base Exceptions
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPError(Exception):
|
||||||
|
"""Base exception used by this module."""
|
||||||
|
|
||||||
|
|
||||||
|
class HTTPWarning(Warning):
|
||||||
|
"""Base warning used by this module."""
|
||||||
|
|
||||||
|
|
||||||
|
_TYPE_REDUCE_RESULT = tuple[typing.Callable[..., object], tuple[object, ...]]
|
||||||
|
|
||||||
|
|
||||||
|
class PoolError(HTTPError):
|
||||||
|
"""Base exception for errors caused within a pool."""
|
||||||
|
|
||||||
|
def __init__(self, pool: ConnectionPool, message: str) -> None:
|
||||||
|
self.pool = pool
|
||||||
|
self._message = message
|
||||||
|
super().__init__(f"{pool}: {message}")
|
||||||
|
|
||||||
|
def __reduce__(self) -> _TYPE_REDUCE_RESULT:
|
||||||
|
# For pickling purposes.
|
||||||
|
return self.__class__, (None, self._message)
|
||||||
|
|
||||||
|
|
||||||
|
class RequestError(PoolError):
|
||||||
|
"""Base exception for PoolErrors that have associated URLs."""
|
||||||
|
|
||||||
|
def __init__(self, pool: ConnectionPool, url: str, message: str) -> None:
|
||||||
|
self.url = url
|
||||||
|
super().__init__(pool, message)
|
||||||
|
|
||||||
|
def __reduce__(self) -> _TYPE_REDUCE_RESULT:
|
||||||
|
# For pickling purposes.
|
||||||
|
return self.__class__, (None, self.url, self._message)
|
||||||
|
|
||||||
|
|
||||||
|
class SSLError(HTTPError):
|
||||||
|
"""Raised when SSL certificate fails in an HTTPS connection."""
|
||||||
|
|
||||||
|
|
||||||
|
class ProxyError(HTTPError):
|
||||||
|
"""Raised when the connection to a proxy fails."""
|
||||||
|
|
||||||
|
# The original error is also available as __cause__.
|
||||||
|
original_error: Exception
|
||||||
|
|
||||||
|
def __init__(self, message: str, error: Exception) -> None:
|
||||||
|
super().__init__(message, error)
|
||||||
|
self.original_error = error
|
||||||
|
|
||||||
|
|
||||||
|
class DecodeError(HTTPError):
|
||||||
|
"""Raised when automatic decoding based on Content-Type fails."""
|
||||||
|
|
||||||
|
|
||||||
|
class ProtocolError(HTTPError):
|
||||||
|
"""Raised when something unexpected happens mid-request/response."""
|
||||||
|
|
||||||
|
|
||||||
|
#: Renamed to ProtocolError but aliased for backwards compatibility.
|
||||||
|
ConnectionError = ProtocolError
|
||||||
|
|
||||||
|
|
||||||
|
# Leaf Exceptions
|
||||||
|
|
||||||
|
|
||||||
|
class MaxRetryError(RequestError):
|
||||||
|
"""Raised when the maximum number of retries is exceeded.
|
||||||
|
|
||||||
|
:param pool: The connection pool
|
||||||
|
:type pool: :class:`~urllib3.connectionpool.HTTPConnectionPool`
|
||||||
|
:param str url: The requested Url
|
||||||
|
:param reason: The underlying error
|
||||||
|
:type reason: :class:`Exception`
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, pool: ConnectionPool, url: str, reason: Exception | None = None
|
||||||
|
) -> None:
|
||||||
|
self.reason = reason
|
||||||
|
|
||||||
|
message = f"Max retries exceeded with url: {url} (Caused by {reason!r})"
|
||||||
|
|
||||||
|
super().__init__(pool, url, message)
|
||||||
|
|
||||||
|
def __reduce__(self) -> _TYPE_REDUCE_RESULT:
|
||||||
|
# For pickling purposes.
|
||||||
|
return self.__class__, (None, self.url, self.reason)
|
||||||
|
|
||||||
|
|
||||||
|
class HostChangedError(RequestError):
|
||||||
|
"""Raised when an existing pool gets a request for a foreign host."""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, pool: ConnectionPool, url: str, retries: Retry | int = 3
|
||||||
|
) -> None:
|
||||||
|
message = f"Tried to open a foreign host with url: {url}"
|
||||||
|
super().__init__(pool, url, message)
|
||||||
|
self.retries = retries
|
||||||
|
|
||||||
|
|
||||||
|
class TimeoutStateError(HTTPError):
|
||||||
|
"""Raised when passing an invalid state to a timeout"""
|
||||||
|
|
||||||
|
|
||||||
|
class TimeoutError(HTTPError):
|
||||||
|
"""Raised when a socket timeout error occurs.
|
||||||
|
|
||||||
|
Catching this error will catch both :exc:`ReadTimeoutErrors
|
||||||
|
<ReadTimeoutError>` and :exc:`ConnectTimeoutErrors <ConnectTimeoutError>`.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class ReadTimeoutError(TimeoutError, RequestError):
|
||||||
|
"""Raised when a socket timeout occurs while receiving data from a server"""
|
||||||
|
|
||||||
|
|
||||||
|
# This timeout error does not have a URL attached and needs to inherit from the
|
||||||
|
# base HTTPError
|
||||||
|
class ConnectTimeoutError(TimeoutError):
|
||||||
|
"""Raised when a socket timeout occurs while connecting to a server"""
|
||||||
|
|
||||||
|
|
||||||
|
class NewConnectionError(ConnectTimeoutError, HTTPError):
|
||||||
|
"""Raised when we fail to establish a new connection. Usually ECONNREFUSED."""
|
||||||
|
|
||||||
|
def __init__(self, conn: HTTPConnection, message: str) -> None:
|
||||||
|
self.conn = conn
|
||||||
|
self._message = message
|
||||||
|
super().__init__(f"{conn}: {message}")
|
||||||
|
|
||||||
|
def __reduce__(self) -> _TYPE_REDUCE_RESULT:
|
||||||
|
# For pickling purposes.
|
||||||
|
return self.__class__, (None, self._message)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def pool(self) -> HTTPConnection:
|
||||||
|
warnings.warn(
|
||||||
|
"The 'pool' property is deprecated and will be removed "
|
||||||
|
"in urllib3 v2.1.0. Use 'conn' instead.",
|
||||||
|
DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
|
||||||
|
return self.conn
|
||||||
|
|
||||||
|
|
||||||
|
class NameResolutionError(NewConnectionError):
|
||||||
|
"""Raised when host name resolution fails."""
|
||||||
|
|
||||||
|
def __init__(self, host: str, conn: HTTPConnection, reason: socket.gaierror):
|
||||||
|
message = f"Failed to resolve '{host}' ({reason})"
|
||||||
|
self._host = host
|
||||||
|
self._reason = reason
|
||||||
|
super().__init__(conn, message)
|
||||||
|
|
||||||
|
def __reduce__(self) -> _TYPE_REDUCE_RESULT:
|
||||||
|
# For pickling purposes.
|
||||||
|
return self.__class__, (self._host, None, self._reason)
|
||||||
|
|
||||||
|
|
||||||
|
class EmptyPoolError(PoolError):
|
||||||
|
"""Raised when a pool runs out of connections and no more are allowed."""
|
||||||
|
|
||||||
|
|
||||||
|
class FullPoolError(PoolError):
|
||||||
|
"""Raised when we try to add a connection to a full pool in blocking mode."""
|
||||||
|
|
||||||
|
|
||||||
|
class ClosedPoolError(PoolError):
|
||||||
|
"""Raised when a request enters a pool after the pool has been closed."""
|
||||||
|
|
||||||
|
|
||||||
|
class LocationValueError(ValueError, HTTPError):
|
||||||
|
"""Raised when there is something wrong with a given URL input."""
|
||||||
|
|
||||||
|
|
||||||
|
class LocationParseError(LocationValueError):
|
||||||
|
"""Raised when get_host or similar fails to parse the URL input."""
|
||||||
|
|
||||||
|
def __init__(self, location: str) -> None:
|
||||||
|
message = f"Failed to parse: {location}"
|
||||||
|
super().__init__(message)
|
||||||
|
|
||||||
|
self.location = location
|
||||||
|
|
||||||
|
|
||||||
|
class URLSchemeUnknown(LocationValueError):
|
||||||
|
"""Raised when a URL input has an unsupported scheme."""
|
||||||
|
|
||||||
|
def __init__(self, scheme: str):
|
||||||
|
message = f"Not supported URL scheme {scheme}"
|
||||||
|
super().__init__(message)
|
||||||
|
|
||||||
|
self.scheme = scheme
|
||||||
|
|
||||||
|
|
||||||
|
class ResponseError(HTTPError):
|
||||||
|
"""Used as a container for an error reason supplied in a MaxRetryError."""
|
||||||
|
|
||||||
|
GENERIC_ERROR = "too many error responses"
|
||||||
|
SPECIFIC_ERROR = "too many {status_code} error responses"
|
||||||
|
|
||||||
|
|
||||||
|
class SecurityWarning(HTTPWarning):
|
||||||
|
"""Warned when performing security reducing actions"""
|
||||||
|
|
||||||
|
|
||||||
|
class InsecureRequestWarning(SecurityWarning):
|
||||||
|
"""Warned when making an unverified HTTPS request."""
|
||||||
|
|
||||||
|
|
||||||
|
class NotOpenSSLWarning(SecurityWarning):
|
||||||
|
"""Warned when using unsupported SSL library"""
|
||||||
|
|
||||||
|
|
||||||
|
class SystemTimeWarning(SecurityWarning):
|
||||||
|
"""Warned when system time is suspected to be wrong"""
|
||||||
|
|
||||||
|
|
||||||
|
class InsecurePlatformWarning(SecurityWarning):
|
||||||
|
"""Warned when certain TLS/SSL configuration is not available on a platform."""
|
||||||
|
|
||||||
|
|
||||||
|
class DependencyWarning(HTTPWarning):
|
||||||
|
"""
|
||||||
|
Warned when an attempt is made to import a module with missing optional
|
||||||
|
dependencies.
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class ResponseNotChunked(ProtocolError, ValueError):
|
||||||
|
"""Response needs to be chunked in order to read it as chunks."""
|
||||||
|
|
||||||
|
|
||||||
|
class BodyNotHttplibCompatible(HTTPError):
|
||||||
|
"""
|
||||||
|
Body should be :class:`http.client.HTTPResponse` like
|
||||||
|
(have an fp attribute which returns raw chunks) for read_chunked().
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class IncompleteRead(HTTPError, httplib_IncompleteRead):
|
||||||
|
"""
|
||||||
|
Response length doesn't match expected Content-Length
|
||||||
|
|
||||||
|
Subclass of :class:`http.client.IncompleteRead` to allow int value
|
||||||
|
for ``partial`` to avoid creating large objects on streamed reads.
|
||||||
|
"""
|
||||||
|
|
||||||
|
partial: int # type: ignore[assignment]
|
||||||
|
expected: int
|
||||||
|
|
||||||
|
def __init__(self, partial: int, expected: int) -> None:
|
||||||
|
self.partial = partial
|
||||||
|
self.expected = expected
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
return "IncompleteRead(%i bytes read, %i more expected)" % (
|
||||||
|
self.partial,
|
||||||
|
self.expected,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidChunkLength(HTTPError, httplib_IncompleteRead):
|
||||||
|
"""Invalid chunk length in a chunked response."""
|
||||||
|
|
||||||
|
def __init__(self, response: HTTPResponse, length: bytes) -> None:
|
||||||
|
self.partial: int = response.tell() # type: ignore[assignment]
|
||||||
|
self.expected: int | None = response.length_remaining
|
||||||
|
self.response = response
|
||||||
|
self.length = length
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
return "InvalidChunkLength(got length %r, %i bytes read)" % (
|
||||||
|
self.length,
|
||||||
|
self.partial,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class InvalidHeader(HTTPError):
|
||||||
|
"""The header provided was somehow invalid."""
|
||||||
|
|
||||||
|
|
||||||
|
class ProxySchemeUnknown(AssertionError, URLSchemeUnknown):
|
||||||
|
"""ProxyManager does not support the supplied scheme"""
|
||||||
|
|
||||||
|
# TODO(t-8ch): Stop inheriting from AssertionError in v2.0.
|
||||||
|
|
||||||
|
def __init__(self, scheme: str | None) -> None:
|
||||||
|
# 'localhost' is here because our URL parser parses
|
||||||
|
# localhost:8080 -> scheme=localhost, remove if we fix this.
|
||||||
|
if scheme == "localhost":
|
||||||
|
scheme = None
|
||||||
|
if scheme is None:
|
||||||
|
message = "Proxy URL had no scheme, should start with http:// or https://"
|
||||||
|
else:
|
||||||
|
message = f"Proxy URL had unsupported scheme {scheme}, should use http:// or https://"
|
||||||
|
super().__init__(message)
|
||||||
|
|
||||||
|
|
||||||
|
class ProxySchemeUnsupported(ValueError):
|
||||||
|
"""Fetching HTTPS resources through HTTPS proxies is unsupported"""
|
||||||
|
|
||||||
|
|
||||||
|
class HeaderParsingError(HTTPError):
|
||||||
|
"""Raised by assert_header_parsing, but we convert it to a log.warning statement."""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, defects: list[MessageDefect], unparsed_data: bytes | str | None
|
||||||
|
) -> None:
|
||||||
|
message = f"{defects or 'Unknown'}, unparsed data: {unparsed_data!r}"
|
||||||
|
super().__init__(message)
|
||||||
|
|
||||||
|
|
||||||
|
class UnrewindableBodyError(HTTPError):
|
||||||
|
"""urllib3 encountered an error when trying to rewind a body"""
|
||||||
341
venv/lib/python3.12/site-packages/urllib3/fields.py
Normal file
341
venv/lib/python3.12/site-packages/urllib3/fields.py
Normal file
@@ -0,0 +1,341 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import email.utils
|
||||||
|
import mimetypes
|
||||||
|
import typing
|
||||||
|
|
||||||
|
_TYPE_FIELD_VALUE = typing.Union[str, bytes]
|
||||||
|
_TYPE_FIELD_VALUE_TUPLE = typing.Union[
|
||||||
|
_TYPE_FIELD_VALUE,
|
||||||
|
tuple[str, _TYPE_FIELD_VALUE],
|
||||||
|
tuple[str, _TYPE_FIELD_VALUE, str],
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def guess_content_type(
|
||||||
|
filename: str | None, default: str = "application/octet-stream"
|
||||||
|
) -> str:
|
||||||
|
"""
|
||||||
|
Guess the "Content-Type" of a file.
|
||||||
|
|
||||||
|
:param filename:
|
||||||
|
The filename to guess the "Content-Type" of using :mod:`mimetypes`.
|
||||||
|
:param default:
|
||||||
|
If no "Content-Type" can be guessed, default to `default`.
|
||||||
|
"""
|
||||||
|
if filename:
|
||||||
|
return mimetypes.guess_type(filename)[0] or default
|
||||||
|
return default
|
||||||
|
|
||||||
|
|
||||||
|
def format_header_param_rfc2231(name: str, value: _TYPE_FIELD_VALUE) -> str:
|
||||||
|
"""
|
||||||
|
Helper function to format and quote a single header parameter using the
|
||||||
|
strategy defined in RFC 2231.
|
||||||
|
|
||||||
|
Particularly useful for header parameters which might contain
|
||||||
|
non-ASCII values, like file names. This follows
|
||||||
|
`RFC 2388 Section 4.4 <https://tools.ietf.org/html/rfc2388#section-4.4>`_.
|
||||||
|
|
||||||
|
:param name:
|
||||||
|
The name of the parameter, a string expected to be ASCII only.
|
||||||
|
:param value:
|
||||||
|
The value of the parameter, provided as ``bytes`` or `str``.
|
||||||
|
:returns:
|
||||||
|
An RFC-2231-formatted unicode string.
|
||||||
|
|
||||||
|
.. deprecated:: 2.0.0
|
||||||
|
Will be removed in urllib3 v2.1.0. This is not valid for
|
||||||
|
``multipart/form-data`` header parameters.
|
||||||
|
"""
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
warnings.warn(
|
||||||
|
"'format_header_param_rfc2231' is deprecated and will be "
|
||||||
|
"removed in urllib3 v2.1.0. This is not valid for "
|
||||||
|
"multipart/form-data header parameters.",
|
||||||
|
DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
|
||||||
|
if isinstance(value, bytes):
|
||||||
|
value = value.decode("utf-8")
|
||||||
|
|
||||||
|
if not any(ch in value for ch in '"\\\r\n'):
|
||||||
|
result = f'{name}="{value}"'
|
||||||
|
try:
|
||||||
|
result.encode("ascii")
|
||||||
|
except (UnicodeEncodeError, UnicodeDecodeError):
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
return result
|
||||||
|
|
||||||
|
value = email.utils.encode_rfc2231(value, "utf-8")
|
||||||
|
value = f"{name}*={value}"
|
||||||
|
|
||||||
|
return value
|
||||||
|
|
||||||
|
|
||||||
|
def format_multipart_header_param(name: str, value: _TYPE_FIELD_VALUE) -> str:
|
||||||
|
"""
|
||||||
|
Format and quote a single multipart header parameter.
|
||||||
|
|
||||||
|
This follows the `WHATWG HTML Standard`_ as of 2021/06/10, matching
|
||||||
|
the behavior of current browser and curl versions. Values are
|
||||||
|
assumed to be UTF-8. The ``\\n``, ``\\r``, and ``"`` characters are
|
||||||
|
percent encoded.
|
||||||
|
|
||||||
|
.. _WHATWG HTML Standard:
|
||||||
|
https://html.spec.whatwg.org/multipage/
|
||||||
|
form-control-infrastructure.html#multipart-form-data
|
||||||
|
|
||||||
|
:param name:
|
||||||
|
The name of the parameter, an ASCII-only ``str``.
|
||||||
|
:param value:
|
||||||
|
The value of the parameter, a ``str`` or UTF-8 encoded
|
||||||
|
``bytes``.
|
||||||
|
:returns:
|
||||||
|
A string ``name="value"`` with the escaped value.
|
||||||
|
|
||||||
|
.. versionchanged:: 2.0.0
|
||||||
|
Matches the WHATWG HTML Standard as of 2021/06/10. Control
|
||||||
|
characters are no longer percent encoded.
|
||||||
|
|
||||||
|
.. versionchanged:: 2.0.0
|
||||||
|
Renamed from ``format_header_param_html5`` and
|
||||||
|
``format_header_param``. The old names will be removed in
|
||||||
|
urllib3 v2.1.0.
|
||||||
|
"""
|
||||||
|
if isinstance(value, bytes):
|
||||||
|
value = value.decode("utf-8")
|
||||||
|
|
||||||
|
# percent encode \n \r "
|
||||||
|
value = value.translate({10: "%0A", 13: "%0D", 34: "%22"})
|
||||||
|
return f'{name}="{value}"'
|
||||||
|
|
||||||
|
|
||||||
|
def format_header_param_html5(name: str, value: _TYPE_FIELD_VALUE) -> str:
|
||||||
|
"""
|
||||||
|
.. deprecated:: 2.0.0
|
||||||
|
Renamed to :func:`format_multipart_header_param`. Will be
|
||||||
|
removed in urllib3 v2.1.0.
|
||||||
|
"""
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
warnings.warn(
|
||||||
|
"'format_header_param_html5' has been renamed to "
|
||||||
|
"'format_multipart_header_param'. The old name will be "
|
||||||
|
"removed in urllib3 v2.1.0.",
|
||||||
|
DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
return format_multipart_header_param(name, value)
|
||||||
|
|
||||||
|
|
||||||
|
def format_header_param(name: str, value: _TYPE_FIELD_VALUE) -> str:
|
||||||
|
"""
|
||||||
|
.. deprecated:: 2.0.0
|
||||||
|
Renamed to :func:`format_multipart_header_param`. Will be
|
||||||
|
removed in urllib3 v2.1.0.
|
||||||
|
"""
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
warnings.warn(
|
||||||
|
"'format_header_param' has been renamed to "
|
||||||
|
"'format_multipart_header_param'. The old name will be "
|
||||||
|
"removed in urllib3 v2.1.0.",
|
||||||
|
DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
return format_multipart_header_param(name, value)
|
||||||
|
|
||||||
|
|
||||||
|
class RequestField:
|
||||||
|
"""
|
||||||
|
A data container for request body parameters.
|
||||||
|
|
||||||
|
:param name:
|
||||||
|
The name of this request field. Must be unicode.
|
||||||
|
:param data:
|
||||||
|
The data/value body.
|
||||||
|
:param filename:
|
||||||
|
An optional filename of the request field. Must be unicode.
|
||||||
|
:param headers:
|
||||||
|
An optional dict-like object of headers to initially use for the field.
|
||||||
|
|
||||||
|
.. versionchanged:: 2.0.0
|
||||||
|
The ``header_formatter`` parameter is deprecated and will
|
||||||
|
be removed in urllib3 v2.1.0.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
name: str,
|
||||||
|
data: _TYPE_FIELD_VALUE,
|
||||||
|
filename: str | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
header_formatter: typing.Callable[[str, _TYPE_FIELD_VALUE], str] | None = None,
|
||||||
|
):
|
||||||
|
self._name = name
|
||||||
|
self._filename = filename
|
||||||
|
self.data = data
|
||||||
|
self.headers: dict[str, str | None] = {}
|
||||||
|
if headers:
|
||||||
|
self.headers = dict(headers)
|
||||||
|
|
||||||
|
if header_formatter is not None:
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
warnings.warn(
|
||||||
|
"The 'header_formatter' parameter is deprecated and "
|
||||||
|
"will be removed in urllib3 v2.1.0.",
|
||||||
|
DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
self.header_formatter = header_formatter
|
||||||
|
else:
|
||||||
|
self.header_formatter = format_multipart_header_param
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_tuples(
|
||||||
|
cls,
|
||||||
|
fieldname: str,
|
||||||
|
value: _TYPE_FIELD_VALUE_TUPLE,
|
||||||
|
header_formatter: typing.Callable[[str, _TYPE_FIELD_VALUE], str] | None = None,
|
||||||
|
) -> RequestField:
|
||||||
|
"""
|
||||||
|
A :class:`~urllib3.fields.RequestField` factory from old-style tuple parameters.
|
||||||
|
|
||||||
|
Supports constructing :class:`~urllib3.fields.RequestField` from
|
||||||
|
parameter of key/value strings AND key/filetuple. A filetuple is a
|
||||||
|
(filename, data, MIME type) tuple where the MIME type is optional.
|
||||||
|
For example::
|
||||||
|
|
||||||
|
'foo': 'bar',
|
||||||
|
'fakefile': ('foofile.txt', 'contents of foofile'),
|
||||||
|
'realfile': ('barfile.txt', open('realfile').read()),
|
||||||
|
'typedfile': ('bazfile.bin', open('bazfile').read(), 'image/jpeg'),
|
||||||
|
'nonamefile': 'contents of nonamefile field',
|
||||||
|
|
||||||
|
Field names and filenames must be unicode.
|
||||||
|
"""
|
||||||
|
filename: str | None
|
||||||
|
content_type: str | None
|
||||||
|
data: _TYPE_FIELD_VALUE
|
||||||
|
|
||||||
|
if isinstance(value, tuple):
|
||||||
|
if len(value) == 3:
|
||||||
|
filename, data, content_type = value
|
||||||
|
else:
|
||||||
|
filename, data = value
|
||||||
|
content_type = guess_content_type(filename)
|
||||||
|
else:
|
||||||
|
filename = None
|
||||||
|
content_type = None
|
||||||
|
data = value
|
||||||
|
|
||||||
|
request_param = cls(
|
||||||
|
fieldname, data, filename=filename, header_formatter=header_formatter
|
||||||
|
)
|
||||||
|
request_param.make_multipart(content_type=content_type)
|
||||||
|
|
||||||
|
return request_param
|
||||||
|
|
||||||
|
def _render_part(self, name: str, value: _TYPE_FIELD_VALUE) -> str:
|
||||||
|
"""
|
||||||
|
Override this method to change how each multipart header
|
||||||
|
parameter is formatted. By default, this calls
|
||||||
|
:func:`format_multipart_header_param`.
|
||||||
|
|
||||||
|
:param name:
|
||||||
|
The name of the parameter, an ASCII-only ``str``.
|
||||||
|
:param value:
|
||||||
|
The value of the parameter, a ``str`` or UTF-8 encoded
|
||||||
|
``bytes``.
|
||||||
|
|
||||||
|
:meta public:
|
||||||
|
"""
|
||||||
|
return self.header_formatter(name, value)
|
||||||
|
|
||||||
|
def _render_parts(
|
||||||
|
self,
|
||||||
|
header_parts: (
|
||||||
|
dict[str, _TYPE_FIELD_VALUE | None]
|
||||||
|
| typing.Sequence[tuple[str, _TYPE_FIELD_VALUE | None]]
|
||||||
|
),
|
||||||
|
) -> str:
|
||||||
|
"""
|
||||||
|
Helper function to format and quote a single header.
|
||||||
|
|
||||||
|
Useful for single headers that are composed of multiple items. E.g.,
|
||||||
|
'Content-Disposition' fields.
|
||||||
|
|
||||||
|
:param header_parts:
|
||||||
|
A sequence of (k, v) tuples or a :class:`dict` of (k, v) to format
|
||||||
|
as `k1="v1"; k2="v2"; ...`.
|
||||||
|
"""
|
||||||
|
iterable: typing.Iterable[tuple[str, _TYPE_FIELD_VALUE | None]]
|
||||||
|
|
||||||
|
parts = []
|
||||||
|
if isinstance(header_parts, dict):
|
||||||
|
iterable = header_parts.items()
|
||||||
|
else:
|
||||||
|
iterable = header_parts
|
||||||
|
|
||||||
|
for name, value in iterable:
|
||||||
|
if value is not None:
|
||||||
|
parts.append(self._render_part(name, value))
|
||||||
|
|
||||||
|
return "; ".join(parts)
|
||||||
|
|
||||||
|
def render_headers(self) -> str:
|
||||||
|
"""
|
||||||
|
Renders the headers for this request field.
|
||||||
|
"""
|
||||||
|
lines = []
|
||||||
|
|
||||||
|
sort_keys = ["Content-Disposition", "Content-Type", "Content-Location"]
|
||||||
|
for sort_key in sort_keys:
|
||||||
|
if self.headers.get(sort_key, False):
|
||||||
|
lines.append(f"{sort_key}: {self.headers[sort_key]}")
|
||||||
|
|
||||||
|
for header_name, header_value in self.headers.items():
|
||||||
|
if header_name not in sort_keys:
|
||||||
|
if header_value:
|
||||||
|
lines.append(f"{header_name}: {header_value}")
|
||||||
|
|
||||||
|
lines.append("\r\n")
|
||||||
|
return "\r\n".join(lines)
|
||||||
|
|
||||||
|
def make_multipart(
|
||||||
|
self,
|
||||||
|
content_disposition: str | None = None,
|
||||||
|
content_type: str | None = None,
|
||||||
|
content_location: str | None = None,
|
||||||
|
) -> None:
|
||||||
|
"""
|
||||||
|
Makes this request field into a multipart request field.
|
||||||
|
|
||||||
|
This method overrides "Content-Disposition", "Content-Type" and
|
||||||
|
"Content-Location" headers to the request parameter.
|
||||||
|
|
||||||
|
:param content_disposition:
|
||||||
|
The 'Content-Disposition' of the request body. Defaults to 'form-data'
|
||||||
|
:param content_type:
|
||||||
|
The 'Content-Type' of the request body.
|
||||||
|
:param content_location:
|
||||||
|
The 'Content-Location' of the request body.
|
||||||
|
|
||||||
|
"""
|
||||||
|
content_disposition = (content_disposition or "form-data") + "; ".join(
|
||||||
|
[
|
||||||
|
"",
|
||||||
|
self._render_parts(
|
||||||
|
(("name", self._name), ("filename", self._filename))
|
||||||
|
),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
|
||||||
|
self.headers["Content-Disposition"] = content_disposition
|
||||||
|
self.headers["Content-Type"] = content_type
|
||||||
|
self.headers["Content-Location"] = content_location
|
||||||
89
venv/lib/python3.12/site-packages/urllib3/filepost.py
Normal file
89
venv/lib/python3.12/site-packages/urllib3/filepost.py
Normal file
@@ -0,0 +1,89 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import binascii
|
||||||
|
import codecs
|
||||||
|
import os
|
||||||
|
import typing
|
||||||
|
from io import BytesIO
|
||||||
|
|
||||||
|
from .fields import _TYPE_FIELD_VALUE_TUPLE, RequestField
|
||||||
|
|
||||||
|
writer = codecs.lookup("utf-8")[3]
|
||||||
|
|
||||||
|
_TYPE_FIELDS_SEQUENCE = typing.Sequence[
|
||||||
|
typing.Union[tuple[str, _TYPE_FIELD_VALUE_TUPLE], RequestField]
|
||||||
|
]
|
||||||
|
_TYPE_FIELDS = typing.Union[
|
||||||
|
_TYPE_FIELDS_SEQUENCE,
|
||||||
|
typing.Mapping[str, _TYPE_FIELD_VALUE_TUPLE],
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def choose_boundary() -> str:
|
||||||
|
"""
|
||||||
|
Our embarrassingly-simple replacement for mimetools.choose_boundary.
|
||||||
|
"""
|
||||||
|
return binascii.hexlify(os.urandom(16)).decode()
|
||||||
|
|
||||||
|
|
||||||
|
def iter_field_objects(fields: _TYPE_FIELDS) -> typing.Iterable[RequestField]:
|
||||||
|
"""
|
||||||
|
Iterate over fields.
|
||||||
|
|
||||||
|
Supports list of (k, v) tuples and dicts, and lists of
|
||||||
|
:class:`~urllib3.fields.RequestField`.
|
||||||
|
|
||||||
|
"""
|
||||||
|
iterable: typing.Iterable[RequestField | tuple[str, _TYPE_FIELD_VALUE_TUPLE]]
|
||||||
|
|
||||||
|
if isinstance(fields, typing.Mapping):
|
||||||
|
iterable = fields.items()
|
||||||
|
else:
|
||||||
|
iterable = fields
|
||||||
|
|
||||||
|
for field in iterable:
|
||||||
|
if isinstance(field, RequestField):
|
||||||
|
yield field
|
||||||
|
else:
|
||||||
|
yield RequestField.from_tuples(*field)
|
||||||
|
|
||||||
|
|
||||||
|
def encode_multipart_formdata(
|
||||||
|
fields: _TYPE_FIELDS, boundary: str | None = None
|
||||||
|
) -> tuple[bytes, str]:
|
||||||
|
"""
|
||||||
|
Encode a dictionary of ``fields`` using the multipart/form-data MIME format.
|
||||||
|
|
||||||
|
:param fields:
|
||||||
|
Dictionary of fields or list of (key, :class:`~urllib3.fields.RequestField`).
|
||||||
|
Values are processed by :func:`urllib3.fields.RequestField.from_tuples`.
|
||||||
|
|
||||||
|
:param boundary:
|
||||||
|
If not specified, then a random boundary will be generated using
|
||||||
|
:func:`urllib3.filepost.choose_boundary`.
|
||||||
|
"""
|
||||||
|
body = BytesIO()
|
||||||
|
if boundary is None:
|
||||||
|
boundary = choose_boundary()
|
||||||
|
|
||||||
|
for field in iter_field_objects(fields):
|
||||||
|
body.write(f"--{boundary}\r\n".encode("latin-1"))
|
||||||
|
|
||||||
|
writer(body).write(field.render_headers())
|
||||||
|
data = field.data
|
||||||
|
|
||||||
|
if isinstance(data, int):
|
||||||
|
data = str(data) # Backwards compatibility
|
||||||
|
|
||||||
|
if isinstance(data, str):
|
||||||
|
writer(body).write(data)
|
||||||
|
else:
|
||||||
|
body.write(data)
|
||||||
|
|
||||||
|
body.write(b"\r\n")
|
||||||
|
|
||||||
|
body.write(f"--{boundary}--\r\n".encode("latin-1"))
|
||||||
|
|
||||||
|
content_type = f"multipart/form-data; boundary={boundary}"
|
||||||
|
|
||||||
|
return body.getvalue(), content_type
|
||||||
53
venv/lib/python3.12/site-packages/urllib3/http2/__init__.py
Normal file
53
venv/lib/python3.12/site-packages/urllib3/http2/__init__.py
Normal file
@@ -0,0 +1,53 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from importlib.metadata import version
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"inject_into_urllib3",
|
||||||
|
"extract_from_urllib3",
|
||||||
|
]
|
||||||
|
|
||||||
|
import typing
|
||||||
|
|
||||||
|
orig_HTTPSConnection: typing.Any = None
|
||||||
|
|
||||||
|
|
||||||
|
def inject_into_urllib3() -> None:
|
||||||
|
# First check if h2 version is valid
|
||||||
|
h2_version = version("h2")
|
||||||
|
if not h2_version.startswith("4."):
|
||||||
|
raise ImportError(
|
||||||
|
"urllib3 v2 supports h2 version 4.x.x, currently "
|
||||||
|
f"the 'h2' module is compiled with {h2_version!r}. "
|
||||||
|
"See: https://github.com/urllib3/urllib3/issues/3290"
|
||||||
|
)
|
||||||
|
|
||||||
|
# Import here to avoid circular dependencies.
|
||||||
|
from .. import connection as urllib3_connection
|
||||||
|
from .. import util as urllib3_util
|
||||||
|
from ..connectionpool import HTTPSConnectionPool
|
||||||
|
from ..util import ssl_ as urllib3_util_ssl
|
||||||
|
from .connection import HTTP2Connection
|
||||||
|
|
||||||
|
global orig_HTTPSConnection
|
||||||
|
orig_HTTPSConnection = urllib3_connection.HTTPSConnection
|
||||||
|
|
||||||
|
HTTPSConnectionPool.ConnectionCls = HTTP2Connection
|
||||||
|
urllib3_connection.HTTPSConnection = HTTP2Connection # type: ignore[misc]
|
||||||
|
|
||||||
|
# TODO: Offer 'http/1.1' as well, but for testing purposes this is handy.
|
||||||
|
urllib3_util.ALPN_PROTOCOLS = ["h2"]
|
||||||
|
urllib3_util_ssl.ALPN_PROTOCOLS = ["h2"]
|
||||||
|
|
||||||
|
|
||||||
|
def extract_from_urllib3() -> None:
|
||||||
|
from .. import connection as urllib3_connection
|
||||||
|
from .. import util as urllib3_util
|
||||||
|
from ..connectionpool import HTTPSConnectionPool
|
||||||
|
from ..util import ssl_ as urllib3_util_ssl
|
||||||
|
|
||||||
|
HTTPSConnectionPool.ConnectionCls = orig_HTTPSConnection
|
||||||
|
urllib3_connection.HTTPSConnection = orig_HTTPSConnection # type: ignore[misc]
|
||||||
|
|
||||||
|
urllib3_util.ALPN_PROTOCOLS = ["http/1.1"]
|
||||||
|
urllib3_util_ssl.ALPN_PROTOCOLS = ["http/1.1"]
|
||||||
356
venv/lib/python3.12/site-packages/urllib3/http2/connection.py
Normal file
356
venv/lib/python3.12/site-packages/urllib3/http2/connection.py
Normal file
@@ -0,0 +1,356 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import re
|
||||||
|
import threading
|
||||||
|
import types
|
||||||
|
import typing
|
||||||
|
|
||||||
|
import h2.config # type: ignore[import-untyped]
|
||||||
|
import h2.connection # type: ignore[import-untyped]
|
||||||
|
import h2.events # type: ignore[import-untyped]
|
||||||
|
|
||||||
|
from .._base_connection import _TYPE_BODY
|
||||||
|
from .._collections import HTTPHeaderDict
|
||||||
|
from ..connection import HTTPSConnection, _get_default_user_agent
|
||||||
|
from ..exceptions import ConnectionError
|
||||||
|
from ..response import BaseHTTPResponse
|
||||||
|
|
||||||
|
orig_HTTPSConnection = HTTPSConnection
|
||||||
|
|
||||||
|
T = typing.TypeVar("T")
|
||||||
|
|
||||||
|
log = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
RE_IS_LEGAL_HEADER_NAME = re.compile(rb"^[!#$%&'*+\-.^_`|~0-9a-z]+$")
|
||||||
|
RE_IS_ILLEGAL_HEADER_VALUE = re.compile(rb"[\0\x00\x0a\x0d\r\n]|^[ \r\n\t]|[ \r\n\t]$")
|
||||||
|
|
||||||
|
|
||||||
|
def _is_legal_header_name(name: bytes) -> bool:
|
||||||
|
"""
|
||||||
|
"An implementation that validates fields according to the definitions in Sections
|
||||||
|
5.1 and 5.5 of [HTTP] only needs an additional check that field names do not
|
||||||
|
include uppercase characters." (https://httpwg.org/specs/rfc9113.html#n-field-validity)
|
||||||
|
|
||||||
|
`http.client._is_legal_header_name` does not validate the field name according to the
|
||||||
|
HTTP 1.1 spec, so we do that here, in addition to checking for uppercase characters.
|
||||||
|
|
||||||
|
This does not allow for the `:` character in the header name, so should not
|
||||||
|
be used to validate pseudo-headers.
|
||||||
|
"""
|
||||||
|
return bool(RE_IS_LEGAL_HEADER_NAME.match(name))
|
||||||
|
|
||||||
|
|
||||||
|
def _is_illegal_header_value(value: bytes) -> bool:
|
||||||
|
"""
|
||||||
|
"A field value MUST NOT contain the zero value (ASCII NUL, 0x00), line feed
|
||||||
|
(ASCII LF, 0x0a), or carriage return (ASCII CR, 0x0d) at any position. A field
|
||||||
|
value MUST NOT start or end with an ASCII whitespace character (ASCII SP or HTAB,
|
||||||
|
0x20 or 0x09)." (https://httpwg.org/specs/rfc9113.html#n-field-validity)
|
||||||
|
"""
|
||||||
|
return bool(RE_IS_ILLEGAL_HEADER_VALUE.search(value))
|
||||||
|
|
||||||
|
|
||||||
|
class _LockedObject(typing.Generic[T]):
|
||||||
|
"""
|
||||||
|
A wrapper class that hides a specific object behind a lock.
|
||||||
|
The goal here is to provide a simple way to protect access to an object
|
||||||
|
that cannot safely be simultaneously accessed from multiple threads. The
|
||||||
|
intended use of this class is simple: take hold of it with a context
|
||||||
|
manager, which returns the protected object.
|
||||||
|
"""
|
||||||
|
|
||||||
|
__slots__ = (
|
||||||
|
"lock",
|
||||||
|
"_obj",
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(self, obj: T):
|
||||||
|
self.lock = threading.RLock()
|
||||||
|
self._obj = obj
|
||||||
|
|
||||||
|
def __enter__(self) -> T:
|
||||||
|
self.lock.acquire()
|
||||||
|
return self._obj
|
||||||
|
|
||||||
|
def __exit__(
|
||||||
|
self,
|
||||||
|
exc_type: type[BaseException] | None,
|
||||||
|
exc_val: BaseException | None,
|
||||||
|
exc_tb: types.TracebackType | None,
|
||||||
|
) -> None:
|
||||||
|
self.lock.release()
|
||||||
|
|
||||||
|
|
||||||
|
class HTTP2Connection(HTTPSConnection):
|
||||||
|
def __init__(
|
||||||
|
self, host: str, port: int | None = None, **kwargs: typing.Any
|
||||||
|
) -> None:
|
||||||
|
self._h2_conn = self._new_h2_conn()
|
||||||
|
self._h2_stream: int | None = None
|
||||||
|
self._headers: list[tuple[bytes, bytes]] = []
|
||||||
|
|
||||||
|
if "proxy" in kwargs or "proxy_config" in kwargs: # Defensive:
|
||||||
|
raise NotImplementedError("Proxies aren't supported with HTTP/2")
|
||||||
|
|
||||||
|
super().__init__(host, port, **kwargs)
|
||||||
|
|
||||||
|
if self._tunnel_host is not None:
|
||||||
|
raise NotImplementedError("Tunneling isn't supported with HTTP/2")
|
||||||
|
|
||||||
|
def _new_h2_conn(self) -> _LockedObject[h2.connection.H2Connection]:
|
||||||
|
config = h2.config.H2Configuration(client_side=True)
|
||||||
|
return _LockedObject(h2.connection.H2Connection(config=config))
|
||||||
|
|
||||||
|
def connect(self) -> None:
|
||||||
|
super().connect()
|
||||||
|
with self._h2_conn as conn:
|
||||||
|
conn.initiate_connection()
|
||||||
|
if data_to_send := conn.data_to_send():
|
||||||
|
self.sock.sendall(data_to_send)
|
||||||
|
|
||||||
|
def putrequest( # type: ignore[override]
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
**kwargs: typing.Any,
|
||||||
|
) -> None:
|
||||||
|
"""putrequest
|
||||||
|
This deviates from the HTTPConnection method signature since we never need to override
|
||||||
|
sending accept-encoding headers or the host header.
|
||||||
|
"""
|
||||||
|
if "skip_host" in kwargs:
|
||||||
|
raise NotImplementedError("`skip_host` isn't supported")
|
||||||
|
if "skip_accept_encoding" in kwargs:
|
||||||
|
raise NotImplementedError("`skip_accept_encoding` isn't supported")
|
||||||
|
|
||||||
|
self._request_url = url or "/"
|
||||||
|
self._validate_path(url) # type: ignore[attr-defined]
|
||||||
|
|
||||||
|
if ":" in self.host:
|
||||||
|
authority = f"[{self.host}]:{self.port or 443}"
|
||||||
|
else:
|
||||||
|
authority = f"{self.host}:{self.port or 443}"
|
||||||
|
|
||||||
|
self._headers.append((b":scheme", b"https"))
|
||||||
|
self._headers.append((b":method", method.encode()))
|
||||||
|
self._headers.append((b":authority", authority.encode()))
|
||||||
|
self._headers.append((b":path", url.encode()))
|
||||||
|
|
||||||
|
with self._h2_conn as conn:
|
||||||
|
self._h2_stream = conn.get_next_available_stream_id()
|
||||||
|
|
||||||
|
def putheader(self, header: str | bytes, *values: str | bytes) -> None: # type: ignore[override]
|
||||||
|
# TODO SKIPPABLE_HEADERS from urllib3 are ignored.
|
||||||
|
header = header.encode() if isinstance(header, str) else header
|
||||||
|
header = header.lower() # A lot of upstream code uses capitalized headers.
|
||||||
|
if not _is_legal_header_name(header):
|
||||||
|
raise ValueError(f"Illegal header name {str(header)}")
|
||||||
|
|
||||||
|
for value in values:
|
||||||
|
value = value.encode() if isinstance(value, str) else value
|
||||||
|
if _is_illegal_header_value(value):
|
||||||
|
raise ValueError(f"Illegal header value {str(value)}")
|
||||||
|
self._headers.append((header, value))
|
||||||
|
|
||||||
|
def endheaders(self, message_body: typing.Any = None) -> None: # type: ignore[override]
|
||||||
|
if self._h2_stream is None:
|
||||||
|
raise ConnectionError("Must call `putrequest` first.")
|
||||||
|
|
||||||
|
with self._h2_conn as conn:
|
||||||
|
conn.send_headers(
|
||||||
|
stream_id=self._h2_stream,
|
||||||
|
headers=self._headers,
|
||||||
|
end_stream=(message_body is None),
|
||||||
|
)
|
||||||
|
if data_to_send := conn.data_to_send():
|
||||||
|
self.sock.sendall(data_to_send)
|
||||||
|
self._headers = [] # Reset headers for the next request.
|
||||||
|
|
||||||
|
def send(self, data: typing.Any) -> None:
|
||||||
|
"""Send data to the server.
|
||||||
|
`data` can be: `str`, `bytes`, an iterable, or file-like objects
|
||||||
|
that support a .read() method.
|
||||||
|
"""
|
||||||
|
if self._h2_stream is None:
|
||||||
|
raise ConnectionError("Must call `putrequest` first.")
|
||||||
|
|
||||||
|
with self._h2_conn as conn:
|
||||||
|
if data_to_send := conn.data_to_send():
|
||||||
|
self.sock.sendall(data_to_send)
|
||||||
|
|
||||||
|
if hasattr(data, "read"): # file-like objects
|
||||||
|
while True:
|
||||||
|
chunk = data.read(self.blocksize)
|
||||||
|
if not chunk:
|
||||||
|
break
|
||||||
|
if isinstance(chunk, str):
|
||||||
|
chunk = chunk.encode() # pragma: no cover
|
||||||
|
conn.send_data(self._h2_stream, chunk, end_stream=False)
|
||||||
|
if data_to_send := conn.data_to_send():
|
||||||
|
self.sock.sendall(data_to_send)
|
||||||
|
conn.end_stream(self._h2_stream)
|
||||||
|
return
|
||||||
|
|
||||||
|
if isinstance(data, str): # str -> bytes
|
||||||
|
data = data.encode()
|
||||||
|
|
||||||
|
try:
|
||||||
|
if isinstance(data, bytes):
|
||||||
|
conn.send_data(self._h2_stream, data, end_stream=True)
|
||||||
|
if data_to_send := conn.data_to_send():
|
||||||
|
self.sock.sendall(data_to_send)
|
||||||
|
else:
|
||||||
|
for chunk in data:
|
||||||
|
conn.send_data(self._h2_stream, chunk, end_stream=False)
|
||||||
|
if data_to_send := conn.data_to_send():
|
||||||
|
self.sock.sendall(data_to_send)
|
||||||
|
conn.end_stream(self._h2_stream)
|
||||||
|
except TypeError:
|
||||||
|
raise TypeError(
|
||||||
|
"`data` should be str, bytes, iterable, or file. got %r"
|
||||||
|
% type(data)
|
||||||
|
)
|
||||||
|
|
||||||
|
def set_tunnel(
|
||||||
|
self,
|
||||||
|
host: str,
|
||||||
|
port: int | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
scheme: str = "http",
|
||||||
|
) -> None:
|
||||||
|
raise NotImplementedError(
|
||||||
|
"HTTP/2 does not support setting up a tunnel through a proxy"
|
||||||
|
)
|
||||||
|
|
||||||
|
def getresponse( # type: ignore[override]
|
||||||
|
self,
|
||||||
|
) -> HTTP2Response:
|
||||||
|
status = None
|
||||||
|
data = bytearray()
|
||||||
|
with self._h2_conn as conn:
|
||||||
|
end_stream = False
|
||||||
|
while not end_stream:
|
||||||
|
# TODO: Arbitrary read value.
|
||||||
|
if received_data := self.sock.recv(65535):
|
||||||
|
events = conn.receive_data(received_data)
|
||||||
|
for event in events:
|
||||||
|
if isinstance(event, h2.events.ResponseReceived):
|
||||||
|
headers = HTTPHeaderDict()
|
||||||
|
for header, value in event.headers:
|
||||||
|
if header == b":status":
|
||||||
|
status = int(value.decode())
|
||||||
|
else:
|
||||||
|
headers.add(
|
||||||
|
header.decode("ascii"), value.decode("ascii")
|
||||||
|
)
|
||||||
|
|
||||||
|
elif isinstance(event, h2.events.DataReceived):
|
||||||
|
data += event.data
|
||||||
|
conn.acknowledge_received_data(
|
||||||
|
event.flow_controlled_length, event.stream_id
|
||||||
|
)
|
||||||
|
|
||||||
|
elif isinstance(event, h2.events.StreamEnded):
|
||||||
|
end_stream = True
|
||||||
|
|
||||||
|
if data_to_send := conn.data_to_send():
|
||||||
|
self.sock.sendall(data_to_send)
|
||||||
|
|
||||||
|
assert status is not None
|
||||||
|
return HTTP2Response(
|
||||||
|
status=status,
|
||||||
|
headers=headers,
|
||||||
|
request_url=self._request_url,
|
||||||
|
data=bytes(data),
|
||||||
|
)
|
||||||
|
|
||||||
|
def request( # type: ignore[override]
|
||||||
|
self,
|
||||||
|
method: str,
|
||||||
|
url: str,
|
||||||
|
body: _TYPE_BODY | None = None,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
*,
|
||||||
|
preload_content: bool = True,
|
||||||
|
decode_content: bool = True,
|
||||||
|
enforce_content_length: bool = True,
|
||||||
|
**kwargs: typing.Any,
|
||||||
|
) -> None:
|
||||||
|
"""Send an HTTP/2 request"""
|
||||||
|
if "chunked" in kwargs:
|
||||||
|
# TODO this is often present from upstream.
|
||||||
|
# raise NotImplementedError("`chunked` isn't supported with HTTP/2")
|
||||||
|
pass
|
||||||
|
|
||||||
|
if self.sock is not None:
|
||||||
|
self.sock.settimeout(self.timeout)
|
||||||
|
|
||||||
|
self.putrequest(method, url)
|
||||||
|
|
||||||
|
headers = headers or {}
|
||||||
|
for k, v in headers.items():
|
||||||
|
if k.lower() == "transfer-encoding" and v == "chunked":
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
self.putheader(k, v)
|
||||||
|
|
||||||
|
if b"user-agent" not in dict(self._headers):
|
||||||
|
self.putheader(b"user-agent", _get_default_user_agent())
|
||||||
|
|
||||||
|
if body:
|
||||||
|
self.endheaders(message_body=body)
|
||||||
|
self.send(body)
|
||||||
|
else:
|
||||||
|
self.endheaders()
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
with self._h2_conn as conn:
|
||||||
|
try:
|
||||||
|
conn.close_connection()
|
||||||
|
if data := conn.data_to_send():
|
||||||
|
self.sock.sendall(data)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
# Reset all our HTTP/2 connection state.
|
||||||
|
self._h2_conn = self._new_h2_conn()
|
||||||
|
self._h2_stream = None
|
||||||
|
self._headers = []
|
||||||
|
|
||||||
|
super().close()
|
||||||
|
|
||||||
|
|
||||||
|
class HTTP2Response(BaseHTTPResponse):
|
||||||
|
# TODO: This is a woefully incomplete response object, but works for non-streaming.
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
status: int,
|
||||||
|
headers: HTTPHeaderDict,
|
||||||
|
request_url: str,
|
||||||
|
data: bytes,
|
||||||
|
decode_content: bool = False, # TODO: support decoding
|
||||||
|
) -> None:
|
||||||
|
super().__init__(
|
||||||
|
status=status,
|
||||||
|
headers=headers,
|
||||||
|
# Following CPython, we map HTTP versions to major * 10 + minor integers
|
||||||
|
version=20,
|
||||||
|
version_string="HTTP/2",
|
||||||
|
# No reason phrase in HTTP/2
|
||||||
|
reason=None,
|
||||||
|
decode_content=decode_content,
|
||||||
|
request_url=request_url,
|
||||||
|
)
|
||||||
|
self._data = data
|
||||||
|
self.length_remaining = 0
|
||||||
|
|
||||||
|
@property
|
||||||
|
def data(self) -> bytes:
|
||||||
|
return self._data
|
||||||
|
|
||||||
|
def get_redirect_location(self) -> None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
pass
|
||||||
87
venv/lib/python3.12/site-packages/urllib3/http2/probe.py
Normal file
87
venv/lib/python3.12/site-packages/urllib3/http2/probe.py
Normal file
@@ -0,0 +1,87 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import threading
|
||||||
|
|
||||||
|
|
||||||
|
class _HTTP2ProbeCache:
|
||||||
|
__slots__ = (
|
||||||
|
"_lock",
|
||||||
|
"_cache_locks",
|
||||||
|
"_cache_values",
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(self) -> None:
|
||||||
|
self._lock = threading.Lock()
|
||||||
|
self._cache_locks: dict[tuple[str, int], threading.RLock] = {}
|
||||||
|
self._cache_values: dict[tuple[str, int], bool | None] = {}
|
||||||
|
|
||||||
|
def acquire_and_get(self, host: str, port: int) -> bool | None:
|
||||||
|
# By the end of this block we know that
|
||||||
|
# _cache_[values,locks] is available.
|
||||||
|
value = None
|
||||||
|
with self._lock:
|
||||||
|
key = (host, port)
|
||||||
|
try:
|
||||||
|
value = self._cache_values[key]
|
||||||
|
# If it's a known value we return right away.
|
||||||
|
if value is not None:
|
||||||
|
return value
|
||||||
|
except KeyError:
|
||||||
|
self._cache_locks[key] = threading.RLock()
|
||||||
|
self._cache_values[key] = None
|
||||||
|
|
||||||
|
# If the value is unknown, we acquire the lock to signal
|
||||||
|
# to the requesting thread that the probe is in progress
|
||||||
|
# or that the current thread needs to return their findings.
|
||||||
|
key_lock = self._cache_locks[key]
|
||||||
|
key_lock.acquire()
|
||||||
|
try:
|
||||||
|
# If the by the time we get the lock the value has been
|
||||||
|
# updated we want to return the updated value.
|
||||||
|
value = self._cache_values[key]
|
||||||
|
|
||||||
|
# In case an exception like KeyboardInterrupt is raised here.
|
||||||
|
except BaseException as e: # Defensive:
|
||||||
|
assert not isinstance(e, KeyError) # KeyError shouldn't be possible.
|
||||||
|
key_lock.release()
|
||||||
|
raise
|
||||||
|
|
||||||
|
return value
|
||||||
|
|
||||||
|
def set_and_release(
|
||||||
|
self, host: str, port: int, supports_http2: bool | None
|
||||||
|
) -> None:
|
||||||
|
key = (host, port)
|
||||||
|
key_lock = self._cache_locks[key]
|
||||||
|
with key_lock: # Uses an RLock, so can be locked again from same thread.
|
||||||
|
if supports_http2 is None and self._cache_values[key] is not None:
|
||||||
|
raise ValueError(
|
||||||
|
"Cannot reset HTTP/2 support for origin after value has been set."
|
||||||
|
) # Defensive: not expected in normal usage
|
||||||
|
|
||||||
|
self._cache_values[key] = supports_http2
|
||||||
|
key_lock.release()
|
||||||
|
|
||||||
|
def _values(self) -> dict[tuple[str, int], bool | None]:
|
||||||
|
"""This function is for testing purposes only. Gets the current state of the probe cache"""
|
||||||
|
with self._lock:
|
||||||
|
return {k: v for k, v in self._cache_values.items()}
|
||||||
|
|
||||||
|
def _reset(self) -> None:
|
||||||
|
"""This function is for testing purposes only. Reset the cache values"""
|
||||||
|
with self._lock:
|
||||||
|
self._cache_locks = {}
|
||||||
|
self._cache_values = {}
|
||||||
|
|
||||||
|
|
||||||
|
_HTTP2_PROBE_CACHE = _HTTP2ProbeCache()
|
||||||
|
|
||||||
|
set_and_release = _HTTP2_PROBE_CACHE.set_and_release
|
||||||
|
acquire_and_get = _HTTP2_PROBE_CACHE.acquire_and_get
|
||||||
|
_values = _HTTP2_PROBE_CACHE._values
|
||||||
|
_reset = _HTTP2_PROBE_CACHE._reset
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"set_and_release",
|
||||||
|
"acquire_and_get",
|
||||||
|
]
|
||||||
653
venv/lib/python3.12/site-packages/urllib3/poolmanager.py
Normal file
653
venv/lib/python3.12/site-packages/urllib3/poolmanager.py
Normal file
@@ -0,0 +1,653 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import functools
|
||||||
|
import logging
|
||||||
|
import typing
|
||||||
|
import warnings
|
||||||
|
from types import TracebackType
|
||||||
|
from urllib.parse import urljoin
|
||||||
|
|
||||||
|
from ._collections import HTTPHeaderDict, RecentlyUsedContainer
|
||||||
|
from ._request_methods import RequestMethods
|
||||||
|
from .connection import ProxyConfig
|
||||||
|
from .connectionpool import HTTPConnectionPool, HTTPSConnectionPool, port_by_scheme
|
||||||
|
from .exceptions import (
|
||||||
|
LocationValueError,
|
||||||
|
MaxRetryError,
|
||||||
|
ProxySchemeUnknown,
|
||||||
|
URLSchemeUnknown,
|
||||||
|
)
|
||||||
|
from .response import BaseHTTPResponse
|
||||||
|
from .util.connection import _TYPE_SOCKET_OPTIONS
|
||||||
|
from .util.proxy import connection_requires_http_tunnel
|
||||||
|
from .util.retry import Retry
|
||||||
|
from .util.timeout import Timeout
|
||||||
|
from .util.url import Url, parse_url
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
import ssl
|
||||||
|
|
||||||
|
from typing_extensions import Self
|
||||||
|
|
||||||
|
__all__ = ["PoolManager", "ProxyManager", "proxy_from_url"]
|
||||||
|
|
||||||
|
|
||||||
|
log = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
SSL_KEYWORDS = (
|
||||||
|
"key_file",
|
||||||
|
"cert_file",
|
||||||
|
"cert_reqs",
|
||||||
|
"ca_certs",
|
||||||
|
"ca_cert_data",
|
||||||
|
"ssl_version",
|
||||||
|
"ssl_minimum_version",
|
||||||
|
"ssl_maximum_version",
|
||||||
|
"ca_cert_dir",
|
||||||
|
"ssl_context",
|
||||||
|
"key_password",
|
||||||
|
"server_hostname",
|
||||||
|
)
|
||||||
|
# Default value for `blocksize` - a new parameter introduced to
|
||||||
|
# http.client.HTTPConnection & http.client.HTTPSConnection in Python 3.7
|
||||||
|
_DEFAULT_BLOCKSIZE = 16384
|
||||||
|
|
||||||
|
|
||||||
|
class PoolKey(typing.NamedTuple):
|
||||||
|
"""
|
||||||
|
All known keyword arguments that could be provided to the pool manager, its
|
||||||
|
pools, or the underlying connections.
|
||||||
|
|
||||||
|
All custom key schemes should include the fields in this key at a minimum.
|
||||||
|
"""
|
||||||
|
|
||||||
|
key_scheme: str
|
||||||
|
key_host: str
|
||||||
|
key_port: int | None
|
||||||
|
key_timeout: Timeout | float | int | None
|
||||||
|
key_retries: Retry | bool | int | None
|
||||||
|
key_block: bool | None
|
||||||
|
key_source_address: tuple[str, int] | None
|
||||||
|
key_key_file: str | None
|
||||||
|
key_key_password: str | None
|
||||||
|
key_cert_file: str | None
|
||||||
|
key_cert_reqs: str | None
|
||||||
|
key_ca_certs: str | None
|
||||||
|
key_ca_cert_data: str | bytes | None
|
||||||
|
key_ssl_version: int | str | None
|
||||||
|
key_ssl_minimum_version: ssl.TLSVersion | None
|
||||||
|
key_ssl_maximum_version: ssl.TLSVersion | None
|
||||||
|
key_ca_cert_dir: str | None
|
||||||
|
key_ssl_context: ssl.SSLContext | None
|
||||||
|
key_maxsize: int | None
|
||||||
|
key_headers: frozenset[tuple[str, str]] | None
|
||||||
|
key__proxy: Url | None
|
||||||
|
key__proxy_headers: frozenset[tuple[str, str]] | None
|
||||||
|
key__proxy_config: ProxyConfig | None
|
||||||
|
key_socket_options: _TYPE_SOCKET_OPTIONS | None
|
||||||
|
key__socks_options: frozenset[tuple[str, str]] | None
|
||||||
|
key_assert_hostname: bool | str | None
|
||||||
|
key_assert_fingerprint: str | None
|
||||||
|
key_server_hostname: str | None
|
||||||
|
key_blocksize: int | None
|
||||||
|
|
||||||
|
|
||||||
|
def _default_key_normalizer(
|
||||||
|
key_class: type[PoolKey], request_context: dict[str, typing.Any]
|
||||||
|
) -> PoolKey:
|
||||||
|
"""
|
||||||
|
Create a pool key out of a request context dictionary.
|
||||||
|
|
||||||
|
According to RFC 3986, both the scheme and host are case-insensitive.
|
||||||
|
Therefore, this function normalizes both before constructing the pool
|
||||||
|
key for an HTTPS request. If you wish to change this behaviour, provide
|
||||||
|
alternate callables to ``key_fn_by_scheme``.
|
||||||
|
|
||||||
|
:param key_class:
|
||||||
|
The class to use when constructing the key. This should be a namedtuple
|
||||||
|
with the ``scheme`` and ``host`` keys at a minimum.
|
||||||
|
:type key_class: namedtuple
|
||||||
|
:param request_context:
|
||||||
|
A dictionary-like object that contain the context for a request.
|
||||||
|
:type request_context: dict
|
||||||
|
|
||||||
|
:return: A namedtuple that can be used as a connection pool key.
|
||||||
|
:rtype: PoolKey
|
||||||
|
"""
|
||||||
|
# Since we mutate the dictionary, make a copy first
|
||||||
|
context = request_context.copy()
|
||||||
|
context["scheme"] = context["scheme"].lower()
|
||||||
|
context["host"] = context["host"].lower()
|
||||||
|
|
||||||
|
# These are both dictionaries and need to be transformed into frozensets
|
||||||
|
for key in ("headers", "_proxy_headers", "_socks_options"):
|
||||||
|
if key in context and context[key] is not None:
|
||||||
|
context[key] = frozenset(context[key].items())
|
||||||
|
|
||||||
|
# The socket_options key may be a list and needs to be transformed into a
|
||||||
|
# tuple.
|
||||||
|
socket_opts = context.get("socket_options")
|
||||||
|
if socket_opts is not None:
|
||||||
|
context["socket_options"] = tuple(socket_opts)
|
||||||
|
|
||||||
|
# Map the kwargs to the names in the namedtuple - this is necessary since
|
||||||
|
# namedtuples can't have fields starting with '_'.
|
||||||
|
for key in list(context.keys()):
|
||||||
|
context["key_" + key] = context.pop(key)
|
||||||
|
|
||||||
|
# Default to ``None`` for keys missing from the context
|
||||||
|
for field in key_class._fields:
|
||||||
|
if field not in context:
|
||||||
|
context[field] = None
|
||||||
|
|
||||||
|
# Default key_blocksize to _DEFAULT_BLOCKSIZE if missing from the context
|
||||||
|
if context.get("key_blocksize") is None:
|
||||||
|
context["key_blocksize"] = _DEFAULT_BLOCKSIZE
|
||||||
|
|
||||||
|
return key_class(**context)
|
||||||
|
|
||||||
|
|
||||||
|
#: A dictionary that maps a scheme to a callable that creates a pool key.
|
||||||
|
#: This can be used to alter the way pool keys are constructed, if desired.
|
||||||
|
#: Each PoolManager makes a copy of this dictionary so they can be configured
|
||||||
|
#: globally here, or individually on the instance.
|
||||||
|
key_fn_by_scheme = {
|
||||||
|
"http": functools.partial(_default_key_normalizer, PoolKey),
|
||||||
|
"https": functools.partial(_default_key_normalizer, PoolKey),
|
||||||
|
}
|
||||||
|
|
||||||
|
pool_classes_by_scheme = {"http": HTTPConnectionPool, "https": HTTPSConnectionPool}
|
||||||
|
|
||||||
|
|
||||||
|
class PoolManager(RequestMethods):
|
||||||
|
"""
|
||||||
|
Allows for arbitrary requests while transparently keeping track of
|
||||||
|
necessary connection pools for you.
|
||||||
|
|
||||||
|
:param num_pools:
|
||||||
|
Number of connection pools to cache before discarding the least
|
||||||
|
recently used pool.
|
||||||
|
|
||||||
|
:param headers:
|
||||||
|
Headers to include with all requests, unless other headers are given
|
||||||
|
explicitly.
|
||||||
|
|
||||||
|
:param \\**connection_pool_kw:
|
||||||
|
Additional parameters are used to create fresh
|
||||||
|
:class:`urllib3.connectionpool.ConnectionPool` instances.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
http = urllib3.PoolManager(num_pools=2)
|
||||||
|
|
||||||
|
resp1 = http.request("GET", "https://google.com/")
|
||||||
|
resp2 = http.request("GET", "https://google.com/mail")
|
||||||
|
resp3 = http.request("GET", "https://yahoo.com/")
|
||||||
|
|
||||||
|
print(len(http.pools))
|
||||||
|
# 2
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
proxy: Url | None = None
|
||||||
|
proxy_config: ProxyConfig | None = None
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
num_pools: int = 10,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
**connection_pool_kw: typing.Any,
|
||||||
|
) -> None:
|
||||||
|
super().__init__(headers)
|
||||||
|
if "retries" in connection_pool_kw:
|
||||||
|
retries = connection_pool_kw["retries"]
|
||||||
|
if not isinstance(retries, Retry):
|
||||||
|
# When Retry is initialized, raise_on_redirect is based
|
||||||
|
# on a redirect boolean value.
|
||||||
|
# But requests made via a pool manager always set
|
||||||
|
# redirect to False, and raise_on_redirect always ends
|
||||||
|
# up being False consequently.
|
||||||
|
# Here we fix the issue by setting raise_on_redirect to
|
||||||
|
# a value needed by the pool manager without considering
|
||||||
|
# the redirect boolean.
|
||||||
|
raise_on_redirect = retries is not False
|
||||||
|
retries = Retry.from_int(retries, redirect=False)
|
||||||
|
retries.raise_on_redirect = raise_on_redirect
|
||||||
|
connection_pool_kw = connection_pool_kw.copy()
|
||||||
|
connection_pool_kw["retries"] = retries
|
||||||
|
self.connection_pool_kw = connection_pool_kw
|
||||||
|
|
||||||
|
self.pools: RecentlyUsedContainer[PoolKey, HTTPConnectionPool]
|
||||||
|
self.pools = RecentlyUsedContainer(num_pools)
|
||||||
|
|
||||||
|
# Locally set the pool classes and keys so other PoolManagers can
|
||||||
|
# override them.
|
||||||
|
self.pool_classes_by_scheme = pool_classes_by_scheme
|
||||||
|
self.key_fn_by_scheme = key_fn_by_scheme.copy()
|
||||||
|
|
||||||
|
def __enter__(self) -> Self:
|
||||||
|
return self
|
||||||
|
|
||||||
|
def __exit__(
|
||||||
|
self,
|
||||||
|
exc_type: type[BaseException] | None,
|
||||||
|
exc_val: BaseException | None,
|
||||||
|
exc_tb: TracebackType | None,
|
||||||
|
) -> typing.Literal[False]:
|
||||||
|
self.clear()
|
||||||
|
# Return False to re-raise any potential exceptions
|
||||||
|
return False
|
||||||
|
|
||||||
|
def _new_pool(
|
||||||
|
self,
|
||||||
|
scheme: str,
|
||||||
|
host: str,
|
||||||
|
port: int,
|
||||||
|
request_context: dict[str, typing.Any] | None = None,
|
||||||
|
) -> HTTPConnectionPool:
|
||||||
|
"""
|
||||||
|
Create a new :class:`urllib3.connectionpool.ConnectionPool` based on host, port, scheme, and
|
||||||
|
any additional pool keyword arguments.
|
||||||
|
|
||||||
|
If ``request_context`` is provided, it is provided as keyword arguments
|
||||||
|
to the pool class used. This method is used to actually create the
|
||||||
|
connection pools handed out by :meth:`connection_from_url` and
|
||||||
|
companion methods. It is intended to be overridden for customization.
|
||||||
|
"""
|
||||||
|
pool_cls: type[HTTPConnectionPool] = self.pool_classes_by_scheme[scheme]
|
||||||
|
if request_context is None:
|
||||||
|
request_context = self.connection_pool_kw.copy()
|
||||||
|
|
||||||
|
# Default blocksize to _DEFAULT_BLOCKSIZE if missing or explicitly
|
||||||
|
# set to 'None' in the request_context.
|
||||||
|
if request_context.get("blocksize") is None:
|
||||||
|
request_context["blocksize"] = _DEFAULT_BLOCKSIZE
|
||||||
|
|
||||||
|
# Although the context has everything necessary to create the pool,
|
||||||
|
# this function has historically only used the scheme, host, and port
|
||||||
|
# in the positional args. When an API change is acceptable these can
|
||||||
|
# be removed.
|
||||||
|
for key in ("scheme", "host", "port"):
|
||||||
|
request_context.pop(key, None)
|
||||||
|
|
||||||
|
if scheme == "http":
|
||||||
|
for kw in SSL_KEYWORDS:
|
||||||
|
request_context.pop(kw, None)
|
||||||
|
|
||||||
|
return pool_cls(host, port, **request_context)
|
||||||
|
|
||||||
|
def clear(self) -> None:
|
||||||
|
"""
|
||||||
|
Empty our store of pools and direct them all to close.
|
||||||
|
|
||||||
|
This will not affect in-flight connections, but they will not be
|
||||||
|
re-used after completion.
|
||||||
|
"""
|
||||||
|
self.pools.clear()
|
||||||
|
|
||||||
|
def connection_from_host(
|
||||||
|
self,
|
||||||
|
host: str | None,
|
||||||
|
port: int | None = None,
|
||||||
|
scheme: str | None = "http",
|
||||||
|
pool_kwargs: dict[str, typing.Any] | None = None,
|
||||||
|
) -> HTTPConnectionPool:
|
||||||
|
"""
|
||||||
|
Get a :class:`urllib3.connectionpool.ConnectionPool` based on the host, port, and scheme.
|
||||||
|
|
||||||
|
If ``port`` isn't given, it will be derived from the ``scheme`` using
|
||||||
|
``urllib3.connectionpool.port_by_scheme``. If ``pool_kwargs`` is
|
||||||
|
provided, it is merged with the instance's ``connection_pool_kw``
|
||||||
|
variable and used to create the new connection pool, if one is
|
||||||
|
needed.
|
||||||
|
"""
|
||||||
|
|
||||||
|
if not host:
|
||||||
|
raise LocationValueError("No host specified.")
|
||||||
|
|
||||||
|
request_context = self._merge_pool_kwargs(pool_kwargs)
|
||||||
|
request_context["scheme"] = scheme or "http"
|
||||||
|
if not port:
|
||||||
|
port = port_by_scheme.get(request_context["scheme"].lower(), 80)
|
||||||
|
request_context["port"] = port
|
||||||
|
request_context["host"] = host
|
||||||
|
|
||||||
|
return self.connection_from_context(request_context)
|
||||||
|
|
||||||
|
def connection_from_context(
|
||||||
|
self, request_context: dict[str, typing.Any]
|
||||||
|
) -> HTTPConnectionPool:
|
||||||
|
"""
|
||||||
|
Get a :class:`urllib3.connectionpool.ConnectionPool` based on the request context.
|
||||||
|
|
||||||
|
``request_context`` must at least contain the ``scheme`` key and its
|
||||||
|
value must be a key in ``key_fn_by_scheme`` instance variable.
|
||||||
|
"""
|
||||||
|
if "strict" in request_context:
|
||||||
|
warnings.warn(
|
||||||
|
"The 'strict' parameter is no longer needed on Python 3+. "
|
||||||
|
"This will raise an error in urllib3 v2.1.0.",
|
||||||
|
DeprecationWarning,
|
||||||
|
)
|
||||||
|
request_context.pop("strict")
|
||||||
|
|
||||||
|
scheme = request_context["scheme"].lower()
|
||||||
|
pool_key_constructor = self.key_fn_by_scheme.get(scheme)
|
||||||
|
if not pool_key_constructor:
|
||||||
|
raise URLSchemeUnknown(scheme)
|
||||||
|
pool_key = pool_key_constructor(request_context)
|
||||||
|
|
||||||
|
return self.connection_from_pool_key(pool_key, request_context=request_context)
|
||||||
|
|
||||||
|
def connection_from_pool_key(
|
||||||
|
self, pool_key: PoolKey, request_context: dict[str, typing.Any]
|
||||||
|
) -> HTTPConnectionPool:
|
||||||
|
"""
|
||||||
|
Get a :class:`urllib3.connectionpool.ConnectionPool` based on the provided pool key.
|
||||||
|
|
||||||
|
``pool_key`` should be a namedtuple that only contains immutable
|
||||||
|
objects. At a minimum it must have the ``scheme``, ``host``, and
|
||||||
|
``port`` fields.
|
||||||
|
"""
|
||||||
|
with self.pools.lock:
|
||||||
|
# If the scheme, host, or port doesn't match existing open
|
||||||
|
# connections, open a new ConnectionPool.
|
||||||
|
pool = self.pools.get(pool_key)
|
||||||
|
if pool:
|
||||||
|
return pool
|
||||||
|
|
||||||
|
# Make a fresh ConnectionPool of the desired type
|
||||||
|
scheme = request_context["scheme"]
|
||||||
|
host = request_context["host"]
|
||||||
|
port = request_context["port"]
|
||||||
|
pool = self._new_pool(scheme, host, port, request_context=request_context)
|
||||||
|
self.pools[pool_key] = pool
|
||||||
|
|
||||||
|
return pool
|
||||||
|
|
||||||
|
def connection_from_url(
|
||||||
|
self, url: str, pool_kwargs: dict[str, typing.Any] | None = None
|
||||||
|
) -> HTTPConnectionPool:
|
||||||
|
"""
|
||||||
|
Similar to :func:`urllib3.connectionpool.connection_from_url`.
|
||||||
|
|
||||||
|
If ``pool_kwargs`` is not provided and a new pool needs to be
|
||||||
|
constructed, ``self.connection_pool_kw`` is used to initialize
|
||||||
|
the :class:`urllib3.connectionpool.ConnectionPool`. If ``pool_kwargs``
|
||||||
|
is provided, it is used instead. Note that if a new pool does not
|
||||||
|
need to be created for the request, the provided ``pool_kwargs`` are
|
||||||
|
not used.
|
||||||
|
"""
|
||||||
|
u = parse_url(url)
|
||||||
|
return self.connection_from_host(
|
||||||
|
u.host, port=u.port, scheme=u.scheme, pool_kwargs=pool_kwargs
|
||||||
|
)
|
||||||
|
|
||||||
|
def _merge_pool_kwargs(
|
||||||
|
self, override: dict[str, typing.Any] | None
|
||||||
|
) -> dict[str, typing.Any]:
|
||||||
|
"""
|
||||||
|
Merge a dictionary of override values for self.connection_pool_kw.
|
||||||
|
|
||||||
|
This does not modify self.connection_pool_kw and returns a new dict.
|
||||||
|
Any keys in the override dictionary with a value of ``None`` are
|
||||||
|
removed from the merged dictionary.
|
||||||
|
"""
|
||||||
|
base_pool_kwargs = self.connection_pool_kw.copy()
|
||||||
|
if override:
|
||||||
|
for key, value in override.items():
|
||||||
|
if value is None:
|
||||||
|
try:
|
||||||
|
del base_pool_kwargs[key]
|
||||||
|
except KeyError:
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
base_pool_kwargs[key] = value
|
||||||
|
return base_pool_kwargs
|
||||||
|
|
||||||
|
def _proxy_requires_url_absolute_form(self, parsed_url: Url) -> bool:
|
||||||
|
"""
|
||||||
|
Indicates if the proxy requires the complete destination URL in the
|
||||||
|
request. Normally this is only needed when not using an HTTP CONNECT
|
||||||
|
tunnel.
|
||||||
|
"""
|
||||||
|
if self.proxy is None:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return not connection_requires_http_tunnel(
|
||||||
|
self.proxy, self.proxy_config, parsed_url.scheme
|
||||||
|
)
|
||||||
|
|
||||||
|
def urlopen( # type: ignore[override]
|
||||||
|
self, method: str, url: str, redirect: bool = True, **kw: typing.Any
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"""
|
||||||
|
Same as :meth:`urllib3.HTTPConnectionPool.urlopen`
|
||||||
|
with custom cross-host redirect logic and only sends the request-uri
|
||||||
|
portion of the ``url``.
|
||||||
|
|
||||||
|
The given ``url`` parameter must be absolute, such that an appropriate
|
||||||
|
:class:`urllib3.connectionpool.ConnectionPool` can be chosen for it.
|
||||||
|
"""
|
||||||
|
u = parse_url(url)
|
||||||
|
|
||||||
|
if u.scheme is None:
|
||||||
|
warnings.warn(
|
||||||
|
"URLs without a scheme (ie 'https://') are deprecated and will raise an error "
|
||||||
|
"in a future version of urllib3. To avoid this DeprecationWarning ensure all URLs "
|
||||||
|
"start with 'https://' or 'http://'. Read more in this issue: "
|
||||||
|
"https://github.com/urllib3/urllib3/issues/2920",
|
||||||
|
category=DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
|
||||||
|
conn = self.connection_from_host(u.host, port=u.port, scheme=u.scheme)
|
||||||
|
|
||||||
|
kw["assert_same_host"] = False
|
||||||
|
kw["redirect"] = False
|
||||||
|
|
||||||
|
if "headers" not in kw:
|
||||||
|
kw["headers"] = self.headers
|
||||||
|
|
||||||
|
if self._proxy_requires_url_absolute_form(u):
|
||||||
|
response = conn.urlopen(method, url, **kw)
|
||||||
|
else:
|
||||||
|
response = conn.urlopen(method, u.request_uri, **kw)
|
||||||
|
|
||||||
|
redirect_location = redirect and response.get_redirect_location()
|
||||||
|
if not redirect_location:
|
||||||
|
return response
|
||||||
|
|
||||||
|
# Support relative URLs for redirecting.
|
||||||
|
redirect_location = urljoin(url, redirect_location)
|
||||||
|
|
||||||
|
if response.status == 303:
|
||||||
|
# Change the method according to RFC 9110, Section 15.4.4.
|
||||||
|
method = "GET"
|
||||||
|
# And lose the body not to transfer anything sensitive.
|
||||||
|
kw["body"] = None
|
||||||
|
kw["headers"] = HTTPHeaderDict(kw["headers"])._prepare_for_method_change()
|
||||||
|
|
||||||
|
retries = kw.get("retries", response.retries)
|
||||||
|
if not isinstance(retries, Retry):
|
||||||
|
retries = Retry.from_int(retries, redirect=redirect)
|
||||||
|
|
||||||
|
# Strip headers marked as unsafe to forward to the redirected location.
|
||||||
|
# Check remove_headers_on_redirect to avoid a potential network call within
|
||||||
|
# conn.is_same_host() which may use socket.gethostbyname() in the future.
|
||||||
|
if retries.remove_headers_on_redirect and not conn.is_same_host(
|
||||||
|
redirect_location
|
||||||
|
):
|
||||||
|
new_headers = kw["headers"].copy()
|
||||||
|
for header in kw["headers"]:
|
||||||
|
if header.lower() in retries.remove_headers_on_redirect:
|
||||||
|
new_headers.pop(header, None)
|
||||||
|
kw["headers"] = new_headers
|
||||||
|
|
||||||
|
try:
|
||||||
|
retries = retries.increment(method, url, response=response, _pool=conn)
|
||||||
|
except MaxRetryError:
|
||||||
|
if retries.raise_on_redirect:
|
||||||
|
response.drain_conn()
|
||||||
|
raise
|
||||||
|
return response
|
||||||
|
|
||||||
|
kw["retries"] = retries
|
||||||
|
kw["redirect"] = redirect
|
||||||
|
|
||||||
|
log.info("Redirecting %s -> %s", url, redirect_location)
|
||||||
|
|
||||||
|
response.drain_conn()
|
||||||
|
return self.urlopen(method, redirect_location, **kw)
|
||||||
|
|
||||||
|
|
||||||
|
class ProxyManager(PoolManager):
|
||||||
|
"""
|
||||||
|
Behaves just like :class:`PoolManager`, but sends all requests through
|
||||||
|
the defined proxy, using the CONNECT method for HTTPS URLs.
|
||||||
|
|
||||||
|
:param proxy_url:
|
||||||
|
The URL of the proxy to be used.
|
||||||
|
|
||||||
|
:param proxy_headers:
|
||||||
|
A dictionary containing headers that will be sent to the proxy. In case
|
||||||
|
of HTTP they are being sent with each request, while in the
|
||||||
|
HTTPS/CONNECT case they are sent only once. Could be used for proxy
|
||||||
|
authentication.
|
||||||
|
|
||||||
|
:param proxy_ssl_context:
|
||||||
|
The proxy SSL context is used to establish the TLS connection to the
|
||||||
|
proxy when using HTTPS proxies.
|
||||||
|
|
||||||
|
:param use_forwarding_for_https:
|
||||||
|
(Defaults to False) If set to True will forward requests to the HTTPS
|
||||||
|
proxy to be made on behalf of the client instead of creating a TLS
|
||||||
|
tunnel via the CONNECT method. **Enabling this flag means that request
|
||||||
|
and response headers and content will be visible from the HTTPS proxy**
|
||||||
|
whereas tunneling keeps request and response headers and content
|
||||||
|
private. IP address, target hostname, SNI, and port are always visible
|
||||||
|
to an HTTPS proxy even when this flag is disabled.
|
||||||
|
|
||||||
|
:param proxy_assert_hostname:
|
||||||
|
The hostname of the certificate to verify against.
|
||||||
|
|
||||||
|
:param proxy_assert_fingerprint:
|
||||||
|
The fingerprint of the certificate to verify against.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
proxy = urllib3.ProxyManager("https://localhost:3128/")
|
||||||
|
|
||||||
|
resp1 = proxy.request("GET", "https://google.com/")
|
||||||
|
resp2 = proxy.request("GET", "https://httpbin.org/")
|
||||||
|
|
||||||
|
print(len(proxy.pools))
|
||||||
|
# 1
|
||||||
|
|
||||||
|
resp3 = proxy.request("GET", "https://httpbin.org/")
|
||||||
|
resp4 = proxy.request("GET", "https://twitter.com/")
|
||||||
|
|
||||||
|
print(len(proxy.pools))
|
||||||
|
# 3
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
proxy_url: str,
|
||||||
|
num_pools: int = 10,
|
||||||
|
headers: typing.Mapping[str, str] | None = None,
|
||||||
|
proxy_headers: typing.Mapping[str, str] | None = None,
|
||||||
|
proxy_ssl_context: ssl.SSLContext | None = None,
|
||||||
|
use_forwarding_for_https: bool = False,
|
||||||
|
proxy_assert_hostname: None | str | typing.Literal[False] = None,
|
||||||
|
proxy_assert_fingerprint: str | None = None,
|
||||||
|
**connection_pool_kw: typing.Any,
|
||||||
|
) -> None:
|
||||||
|
if isinstance(proxy_url, HTTPConnectionPool):
|
||||||
|
str_proxy_url = f"{proxy_url.scheme}://{proxy_url.host}:{proxy_url.port}"
|
||||||
|
else:
|
||||||
|
str_proxy_url = proxy_url
|
||||||
|
proxy = parse_url(str_proxy_url)
|
||||||
|
|
||||||
|
if proxy.scheme not in ("http", "https"):
|
||||||
|
raise ProxySchemeUnknown(proxy.scheme)
|
||||||
|
|
||||||
|
if not proxy.port:
|
||||||
|
port = port_by_scheme.get(proxy.scheme, 80)
|
||||||
|
proxy = proxy._replace(port=port)
|
||||||
|
|
||||||
|
self.proxy = proxy
|
||||||
|
self.proxy_headers = proxy_headers or {}
|
||||||
|
self.proxy_ssl_context = proxy_ssl_context
|
||||||
|
self.proxy_config = ProxyConfig(
|
||||||
|
proxy_ssl_context,
|
||||||
|
use_forwarding_for_https,
|
||||||
|
proxy_assert_hostname,
|
||||||
|
proxy_assert_fingerprint,
|
||||||
|
)
|
||||||
|
|
||||||
|
connection_pool_kw["_proxy"] = self.proxy
|
||||||
|
connection_pool_kw["_proxy_headers"] = self.proxy_headers
|
||||||
|
connection_pool_kw["_proxy_config"] = self.proxy_config
|
||||||
|
|
||||||
|
super().__init__(num_pools, headers, **connection_pool_kw)
|
||||||
|
|
||||||
|
def connection_from_host(
|
||||||
|
self,
|
||||||
|
host: str | None,
|
||||||
|
port: int | None = None,
|
||||||
|
scheme: str | None = "http",
|
||||||
|
pool_kwargs: dict[str, typing.Any] | None = None,
|
||||||
|
) -> HTTPConnectionPool:
|
||||||
|
if scheme == "https":
|
||||||
|
return super().connection_from_host(
|
||||||
|
host, port, scheme, pool_kwargs=pool_kwargs
|
||||||
|
)
|
||||||
|
|
||||||
|
return super().connection_from_host(
|
||||||
|
self.proxy.host, self.proxy.port, self.proxy.scheme, pool_kwargs=pool_kwargs # type: ignore[union-attr]
|
||||||
|
)
|
||||||
|
|
||||||
|
def _set_proxy_headers(
|
||||||
|
self, url: str, headers: typing.Mapping[str, str] | None = None
|
||||||
|
) -> typing.Mapping[str, str]:
|
||||||
|
"""
|
||||||
|
Sets headers needed by proxies: specifically, the Accept and Host
|
||||||
|
headers. Only sets headers not provided by the user.
|
||||||
|
"""
|
||||||
|
headers_ = {"Accept": "*/*"}
|
||||||
|
|
||||||
|
netloc = parse_url(url).netloc
|
||||||
|
if netloc:
|
||||||
|
headers_["Host"] = netloc
|
||||||
|
|
||||||
|
if headers:
|
||||||
|
headers_.update(headers)
|
||||||
|
return headers_
|
||||||
|
|
||||||
|
def urlopen( # type: ignore[override]
|
||||||
|
self, method: str, url: str, redirect: bool = True, **kw: typing.Any
|
||||||
|
) -> BaseHTTPResponse:
|
||||||
|
"Same as HTTP(S)ConnectionPool.urlopen, ``url`` must be absolute."
|
||||||
|
u = parse_url(url)
|
||||||
|
if not connection_requires_http_tunnel(self.proxy, self.proxy_config, u.scheme):
|
||||||
|
# For connections using HTTP CONNECT, httplib sets the necessary
|
||||||
|
# headers on the CONNECT to the proxy. If we're not using CONNECT,
|
||||||
|
# we'll definitely need to set 'Host' at the very least.
|
||||||
|
headers = kw.get("headers", self.headers)
|
||||||
|
kw["headers"] = self._set_proxy_headers(url, headers)
|
||||||
|
|
||||||
|
return super().urlopen(method, url, redirect=redirect, **kw)
|
||||||
|
|
||||||
|
|
||||||
|
def proxy_from_url(url: str, **kw: typing.Any) -> ProxyManager:
|
||||||
|
return ProxyManager(proxy_url=url, **kw)
|
||||||
2
venv/lib/python3.12/site-packages/urllib3/py.typed
Normal file
2
venv/lib/python3.12/site-packages/urllib3/py.typed
Normal file
@@ -0,0 +1,2 @@
|
|||||||
|
# Instruct type checkers to look for inline type annotations in this package.
|
||||||
|
# See PEP 561.
|
||||||
1307
venv/lib/python3.12/site-packages/urllib3/response.py
Normal file
1307
venv/lib/python3.12/site-packages/urllib3/response.py
Normal file
File diff suppressed because it is too large
Load Diff
42
venv/lib/python3.12/site-packages/urllib3/util/__init__.py
Normal file
42
venv/lib/python3.12/site-packages/urllib3/util/__init__.py
Normal file
@@ -0,0 +1,42 @@
|
|||||||
|
# For backwards compatibility, provide imports that used to be here.
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
from .connection import is_connection_dropped
|
||||||
|
from .request import SKIP_HEADER, SKIPPABLE_HEADERS, make_headers
|
||||||
|
from .response import is_fp_closed
|
||||||
|
from .retry import Retry
|
||||||
|
from .ssl_ import (
|
||||||
|
ALPN_PROTOCOLS,
|
||||||
|
IS_PYOPENSSL,
|
||||||
|
SSLContext,
|
||||||
|
assert_fingerprint,
|
||||||
|
create_urllib3_context,
|
||||||
|
resolve_cert_reqs,
|
||||||
|
resolve_ssl_version,
|
||||||
|
ssl_wrap_socket,
|
||||||
|
)
|
||||||
|
from .timeout import Timeout
|
||||||
|
from .url import Url, parse_url
|
||||||
|
from .wait import wait_for_read, wait_for_write
|
||||||
|
|
||||||
|
__all__ = (
|
||||||
|
"IS_PYOPENSSL",
|
||||||
|
"SSLContext",
|
||||||
|
"ALPN_PROTOCOLS",
|
||||||
|
"Retry",
|
||||||
|
"Timeout",
|
||||||
|
"Url",
|
||||||
|
"assert_fingerprint",
|
||||||
|
"create_urllib3_context",
|
||||||
|
"is_connection_dropped",
|
||||||
|
"is_fp_closed",
|
||||||
|
"parse_url",
|
||||||
|
"make_headers",
|
||||||
|
"resolve_cert_reqs",
|
||||||
|
"resolve_ssl_version",
|
||||||
|
"ssl_wrap_socket",
|
||||||
|
"wait_for_read",
|
||||||
|
"wait_for_write",
|
||||||
|
"SKIP_HEADER",
|
||||||
|
"SKIPPABLE_HEADERS",
|
||||||
|
)
|
||||||
137
venv/lib/python3.12/site-packages/urllib3/util/connection.py
Normal file
137
venv/lib/python3.12/site-packages/urllib3/util/connection.py
Normal file
@@ -0,0 +1,137 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import socket
|
||||||
|
import typing
|
||||||
|
|
||||||
|
from ..exceptions import LocationParseError
|
||||||
|
from .timeout import _DEFAULT_TIMEOUT, _TYPE_TIMEOUT
|
||||||
|
|
||||||
|
_TYPE_SOCKET_OPTIONS = list[tuple[int, int, typing.Union[int, bytes]]]
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from .._base_connection import BaseHTTPConnection
|
||||||
|
|
||||||
|
|
||||||
|
def is_connection_dropped(conn: BaseHTTPConnection) -> bool: # Platform-specific
|
||||||
|
"""
|
||||||
|
Returns True if the connection is dropped and should be closed.
|
||||||
|
:param conn: :class:`urllib3.connection.HTTPConnection` object.
|
||||||
|
"""
|
||||||
|
return not conn.is_connected
|
||||||
|
|
||||||
|
|
||||||
|
# This function is copied from socket.py in the Python 2.7 standard
|
||||||
|
# library test suite. Added to its signature is only `socket_options`.
|
||||||
|
# One additional modification is that we avoid binding to IPv6 servers
|
||||||
|
# discovered in DNS if the system doesn't have IPv6 functionality.
|
||||||
|
def create_connection(
|
||||||
|
address: tuple[str, int],
|
||||||
|
timeout: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
source_address: tuple[str, int] | None = None,
|
||||||
|
socket_options: _TYPE_SOCKET_OPTIONS | None = None,
|
||||||
|
) -> socket.socket:
|
||||||
|
"""Connect to *address* and return the socket object.
|
||||||
|
|
||||||
|
Convenience function. Connect to *address* (a 2-tuple ``(host,
|
||||||
|
port)``) and return the socket object. Passing the optional
|
||||||
|
*timeout* parameter will set the timeout on the socket instance
|
||||||
|
before attempting to connect. If no *timeout* is supplied, the
|
||||||
|
global default timeout setting returned by :func:`socket.getdefaulttimeout`
|
||||||
|
is used. If *source_address* is set it must be a tuple of (host, port)
|
||||||
|
for the socket to bind as a source address before making the connection.
|
||||||
|
An host of '' or port 0 tells the OS to use the default.
|
||||||
|
"""
|
||||||
|
|
||||||
|
host, port = address
|
||||||
|
if host.startswith("["):
|
||||||
|
host = host.strip("[]")
|
||||||
|
err = None
|
||||||
|
|
||||||
|
# Using the value from allowed_gai_family() in the context of getaddrinfo lets
|
||||||
|
# us select whether to work with IPv4 DNS records, IPv6 records, or both.
|
||||||
|
# The original create_connection function always returns all records.
|
||||||
|
family = allowed_gai_family()
|
||||||
|
|
||||||
|
try:
|
||||||
|
host.encode("idna")
|
||||||
|
except UnicodeError:
|
||||||
|
raise LocationParseError(f"'{host}', label empty or too long") from None
|
||||||
|
|
||||||
|
for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
|
||||||
|
af, socktype, proto, canonname, sa = res
|
||||||
|
sock = None
|
||||||
|
try:
|
||||||
|
sock = socket.socket(af, socktype, proto)
|
||||||
|
|
||||||
|
# If provided, set socket level options before connecting.
|
||||||
|
_set_socket_options(sock, socket_options)
|
||||||
|
|
||||||
|
if timeout is not _DEFAULT_TIMEOUT:
|
||||||
|
sock.settimeout(timeout)
|
||||||
|
if source_address:
|
||||||
|
sock.bind(source_address)
|
||||||
|
sock.connect(sa)
|
||||||
|
# Break explicitly a reference cycle
|
||||||
|
err = None
|
||||||
|
return sock
|
||||||
|
|
||||||
|
except OSError as _:
|
||||||
|
err = _
|
||||||
|
if sock is not None:
|
||||||
|
sock.close()
|
||||||
|
|
||||||
|
if err is not None:
|
||||||
|
try:
|
||||||
|
raise err
|
||||||
|
finally:
|
||||||
|
# Break explicitly a reference cycle
|
||||||
|
err = None
|
||||||
|
else:
|
||||||
|
raise OSError("getaddrinfo returns an empty list")
|
||||||
|
|
||||||
|
|
||||||
|
def _set_socket_options(
|
||||||
|
sock: socket.socket, options: _TYPE_SOCKET_OPTIONS | None
|
||||||
|
) -> None:
|
||||||
|
if options is None:
|
||||||
|
return
|
||||||
|
|
||||||
|
for opt in options:
|
||||||
|
sock.setsockopt(*opt)
|
||||||
|
|
||||||
|
|
||||||
|
def allowed_gai_family() -> socket.AddressFamily:
|
||||||
|
"""This function is designed to work in the context of
|
||||||
|
getaddrinfo, where family=socket.AF_UNSPEC is the default and
|
||||||
|
will perform a DNS search for both IPv6 and IPv4 records."""
|
||||||
|
|
||||||
|
family = socket.AF_INET
|
||||||
|
if HAS_IPV6:
|
||||||
|
family = socket.AF_UNSPEC
|
||||||
|
return family
|
||||||
|
|
||||||
|
|
||||||
|
def _has_ipv6(host: str) -> bool:
|
||||||
|
"""Returns True if the system can bind an IPv6 address."""
|
||||||
|
sock = None
|
||||||
|
has_ipv6 = False
|
||||||
|
|
||||||
|
if socket.has_ipv6:
|
||||||
|
# has_ipv6 returns true if cPython was compiled with IPv6 support.
|
||||||
|
# It does not tell us if the system has IPv6 support enabled. To
|
||||||
|
# determine that we must bind to an IPv6 address.
|
||||||
|
# https://github.com/urllib3/urllib3/pull/611
|
||||||
|
# https://bugs.python.org/issue658327
|
||||||
|
try:
|
||||||
|
sock = socket.socket(socket.AF_INET6)
|
||||||
|
sock.bind((host, 0))
|
||||||
|
has_ipv6 = True
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
if sock:
|
||||||
|
sock.close()
|
||||||
|
return has_ipv6
|
||||||
|
|
||||||
|
|
||||||
|
HAS_IPV6 = _has_ipv6("::1")
|
||||||
43
venv/lib/python3.12/site-packages/urllib3/util/proxy.py
Normal file
43
venv/lib/python3.12/site-packages/urllib3/util/proxy.py
Normal file
@@ -0,0 +1,43 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import typing
|
||||||
|
|
||||||
|
from .url import Url
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from ..connection import ProxyConfig
|
||||||
|
|
||||||
|
|
||||||
|
def connection_requires_http_tunnel(
|
||||||
|
proxy_url: Url | None = None,
|
||||||
|
proxy_config: ProxyConfig | None = None,
|
||||||
|
destination_scheme: str | None = None,
|
||||||
|
) -> bool:
|
||||||
|
"""
|
||||||
|
Returns True if the connection requires an HTTP CONNECT through the proxy.
|
||||||
|
|
||||||
|
:param URL proxy_url:
|
||||||
|
URL of the proxy.
|
||||||
|
:param ProxyConfig proxy_config:
|
||||||
|
Proxy configuration from poolmanager.py
|
||||||
|
:param str destination_scheme:
|
||||||
|
The scheme of the destination. (i.e https, http, etc)
|
||||||
|
"""
|
||||||
|
# If we're not using a proxy, no way to use a tunnel.
|
||||||
|
if proxy_url is None:
|
||||||
|
return False
|
||||||
|
|
||||||
|
# HTTP destinations never require tunneling, we always forward.
|
||||||
|
if destination_scheme == "http":
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Support for forwarding with HTTPS proxies and HTTPS destinations.
|
||||||
|
if (
|
||||||
|
proxy_url.scheme == "https"
|
||||||
|
and proxy_config
|
||||||
|
and proxy_config.use_forwarding_for_https
|
||||||
|
):
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Otherwise always use a tunnel.
|
||||||
|
return True
|
||||||
266
venv/lib/python3.12/site-packages/urllib3/util/request.py
Normal file
266
venv/lib/python3.12/site-packages/urllib3/util/request.py
Normal file
@@ -0,0 +1,266 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import io
|
||||||
|
import typing
|
||||||
|
from base64 import b64encode
|
||||||
|
from enum import Enum
|
||||||
|
|
||||||
|
from ..exceptions import UnrewindableBodyError
|
||||||
|
from .util import to_bytes
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from typing import Final
|
||||||
|
|
||||||
|
# Pass as a value within ``headers`` to skip
|
||||||
|
# emitting some HTTP headers that are added automatically.
|
||||||
|
# The only headers that are supported are ``Accept-Encoding``,
|
||||||
|
# ``Host``, and ``User-Agent``.
|
||||||
|
SKIP_HEADER = "@@@SKIP_HEADER@@@"
|
||||||
|
SKIPPABLE_HEADERS = frozenset(["accept-encoding", "host", "user-agent"])
|
||||||
|
|
||||||
|
ACCEPT_ENCODING = "gzip,deflate"
|
||||||
|
try:
|
||||||
|
try:
|
||||||
|
import brotlicffi as _unused_module_brotli # type: ignore[import-not-found] # noqa: F401
|
||||||
|
except ImportError:
|
||||||
|
import brotli as _unused_module_brotli # type: ignore[import-not-found] # noqa: F401
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
else:
|
||||||
|
ACCEPT_ENCODING += ",br"
|
||||||
|
|
||||||
|
try:
|
||||||
|
from compression import ( # type: ignore[import-not-found] # noqa: F401
|
||||||
|
zstd as _unused_module_zstd,
|
||||||
|
)
|
||||||
|
|
||||||
|
ACCEPT_ENCODING += ",zstd"
|
||||||
|
except ImportError:
|
||||||
|
try:
|
||||||
|
import zstandard as _unused_module_zstd # noqa: F401
|
||||||
|
|
||||||
|
ACCEPT_ENCODING += ",zstd"
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
class _TYPE_FAILEDTELL(Enum):
|
||||||
|
token = 0
|
||||||
|
|
||||||
|
|
||||||
|
_FAILEDTELL: Final[_TYPE_FAILEDTELL] = _TYPE_FAILEDTELL.token
|
||||||
|
|
||||||
|
_TYPE_BODY_POSITION = typing.Union[int, _TYPE_FAILEDTELL]
|
||||||
|
|
||||||
|
# When sending a request with these methods we aren't expecting
|
||||||
|
# a body so don't need to set an explicit 'Content-Length: 0'
|
||||||
|
# The reason we do this in the negative instead of tracking methods
|
||||||
|
# which 'should' have a body is because unknown methods should be
|
||||||
|
# treated as if they were 'POST' which *does* expect a body.
|
||||||
|
_METHODS_NOT_EXPECTING_BODY = {"GET", "HEAD", "DELETE", "TRACE", "OPTIONS", "CONNECT"}
|
||||||
|
|
||||||
|
|
||||||
|
def make_headers(
|
||||||
|
keep_alive: bool | None = None,
|
||||||
|
accept_encoding: bool | list[str] | str | None = None,
|
||||||
|
user_agent: str | None = None,
|
||||||
|
basic_auth: str | None = None,
|
||||||
|
proxy_basic_auth: str | None = None,
|
||||||
|
disable_cache: bool | None = None,
|
||||||
|
) -> dict[str, str]:
|
||||||
|
"""
|
||||||
|
Shortcuts for generating request headers.
|
||||||
|
|
||||||
|
:param keep_alive:
|
||||||
|
If ``True``, adds 'connection: keep-alive' header.
|
||||||
|
|
||||||
|
:param accept_encoding:
|
||||||
|
Can be a boolean, list, or string.
|
||||||
|
``True`` translates to 'gzip,deflate'. If the dependencies for
|
||||||
|
Brotli (either the ``brotli`` or ``brotlicffi`` package) and/or Zstandard
|
||||||
|
(the ``zstandard`` package) algorithms are installed, then their encodings are
|
||||||
|
included in the string ('br' and 'zstd', respectively).
|
||||||
|
List will get joined by comma.
|
||||||
|
String will be used as provided.
|
||||||
|
|
||||||
|
:param user_agent:
|
||||||
|
String representing the user-agent you want, such as
|
||||||
|
"python-urllib3/0.6"
|
||||||
|
|
||||||
|
:param basic_auth:
|
||||||
|
Colon-separated username:password string for 'authorization: basic ...'
|
||||||
|
auth header.
|
||||||
|
|
||||||
|
:param proxy_basic_auth:
|
||||||
|
Colon-separated username:password string for 'proxy-authorization: basic ...'
|
||||||
|
auth header.
|
||||||
|
|
||||||
|
:param disable_cache:
|
||||||
|
If ``True``, adds 'cache-control: no-cache' header.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
print(urllib3.util.make_headers(keep_alive=True, user_agent="Batman/1.0"))
|
||||||
|
# {'connection': 'keep-alive', 'user-agent': 'Batman/1.0'}
|
||||||
|
print(urllib3.util.make_headers(accept_encoding=True))
|
||||||
|
# {'accept-encoding': 'gzip,deflate'}
|
||||||
|
"""
|
||||||
|
headers: dict[str, str] = {}
|
||||||
|
if accept_encoding:
|
||||||
|
if isinstance(accept_encoding, str):
|
||||||
|
pass
|
||||||
|
elif isinstance(accept_encoding, list):
|
||||||
|
accept_encoding = ",".join(accept_encoding)
|
||||||
|
else:
|
||||||
|
accept_encoding = ACCEPT_ENCODING
|
||||||
|
headers["accept-encoding"] = accept_encoding
|
||||||
|
|
||||||
|
if user_agent:
|
||||||
|
headers["user-agent"] = user_agent
|
||||||
|
|
||||||
|
if keep_alive:
|
||||||
|
headers["connection"] = "keep-alive"
|
||||||
|
|
||||||
|
if basic_auth:
|
||||||
|
headers["authorization"] = (
|
||||||
|
f"Basic {b64encode(basic_auth.encode('latin-1')).decode()}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if proxy_basic_auth:
|
||||||
|
headers["proxy-authorization"] = (
|
||||||
|
f"Basic {b64encode(proxy_basic_auth.encode('latin-1')).decode()}"
|
||||||
|
)
|
||||||
|
|
||||||
|
if disable_cache:
|
||||||
|
headers["cache-control"] = "no-cache"
|
||||||
|
|
||||||
|
return headers
|
||||||
|
|
||||||
|
|
||||||
|
def set_file_position(
|
||||||
|
body: typing.Any, pos: _TYPE_BODY_POSITION | None
|
||||||
|
) -> _TYPE_BODY_POSITION | None:
|
||||||
|
"""
|
||||||
|
If a position is provided, move file to that point.
|
||||||
|
Otherwise, we'll attempt to record a position for future use.
|
||||||
|
"""
|
||||||
|
if pos is not None:
|
||||||
|
rewind_body(body, pos)
|
||||||
|
elif getattr(body, "tell", None) is not None:
|
||||||
|
try:
|
||||||
|
pos = body.tell()
|
||||||
|
except OSError:
|
||||||
|
# This differentiates from None, allowing us to catch
|
||||||
|
# a failed `tell()` later when trying to rewind the body.
|
||||||
|
pos = _FAILEDTELL
|
||||||
|
|
||||||
|
return pos
|
||||||
|
|
||||||
|
|
||||||
|
def rewind_body(body: typing.IO[typing.AnyStr], body_pos: _TYPE_BODY_POSITION) -> None:
|
||||||
|
"""
|
||||||
|
Attempt to rewind body to a certain position.
|
||||||
|
Primarily used for request redirects and retries.
|
||||||
|
|
||||||
|
:param body:
|
||||||
|
File-like object that supports seek.
|
||||||
|
|
||||||
|
:param int pos:
|
||||||
|
Position to seek to in file.
|
||||||
|
"""
|
||||||
|
body_seek = getattr(body, "seek", None)
|
||||||
|
if body_seek is not None and isinstance(body_pos, int):
|
||||||
|
try:
|
||||||
|
body_seek(body_pos)
|
||||||
|
except OSError as e:
|
||||||
|
raise UnrewindableBodyError(
|
||||||
|
"An error occurred when rewinding request body for redirect/retry."
|
||||||
|
) from e
|
||||||
|
elif body_pos is _FAILEDTELL:
|
||||||
|
raise UnrewindableBodyError(
|
||||||
|
"Unable to record file position for rewinding "
|
||||||
|
"request body during a redirect/retry."
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
f"body_pos must be of type integer, instead it was {type(body_pos)}."
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class ChunksAndContentLength(typing.NamedTuple):
|
||||||
|
chunks: typing.Iterable[bytes] | None
|
||||||
|
content_length: int | None
|
||||||
|
|
||||||
|
|
||||||
|
def body_to_chunks(
|
||||||
|
body: typing.Any | None, method: str, blocksize: int
|
||||||
|
) -> ChunksAndContentLength:
|
||||||
|
"""Takes the HTTP request method, body, and blocksize and
|
||||||
|
transforms them into an iterable of chunks to pass to
|
||||||
|
socket.sendall() and an optional 'Content-Length' header.
|
||||||
|
|
||||||
|
A 'Content-Length' of 'None' indicates the length of the body
|
||||||
|
can't be determined so should use 'Transfer-Encoding: chunked'
|
||||||
|
for framing instead.
|
||||||
|
"""
|
||||||
|
|
||||||
|
chunks: typing.Iterable[bytes] | None
|
||||||
|
content_length: int | None
|
||||||
|
|
||||||
|
# No body, we need to make a recommendation on 'Content-Length'
|
||||||
|
# based on whether that request method is expected to have
|
||||||
|
# a body or not.
|
||||||
|
if body is None:
|
||||||
|
chunks = None
|
||||||
|
if method.upper() not in _METHODS_NOT_EXPECTING_BODY:
|
||||||
|
content_length = 0
|
||||||
|
else:
|
||||||
|
content_length = None
|
||||||
|
|
||||||
|
# Bytes or strings become bytes
|
||||||
|
elif isinstance(body, (str, bytes)):
|
||||||
|
chunks = (to_bytes(body),)
|
||||||
|
content_length = len(chunks[0])
|
||||||
|
|
||||||
|
# File-like object, TODO: use seek() and tell() for length?
|
||||||
|
elif hasattr(body, "read"):
|
||||||
|
|
||||||
|
def chunk_readable() -> typing.Iterable[bytes]:
|
||||||
|
nonlocal body, blocksize
|
||||||
|
encode = isinstance(body, io.TextIOBase)
|
||||||
|
while True:
|
||||||
|
datablock = body.read(blocksize)
|
||||||
|
if not datablock:
|
||||||
|
break
|
||||||
|
if encode:
|
||||||
|
datablock = datablock.encode("utf-8")
|
||||||
|
yield datablock
|
||||||
|
|
||||||
|
chunks = chunk_readable()
|
||||||
|
content_length = None
|
||||||
|
|
||||||
|
# Otherwise we need to start checking via duck-typing.
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
# Check if the body implements the buffer API.
|
||||||
|
mv = memoryview(body)
|
||||||
|
except TypeError:
|
||||||
|
try:
|
||||||
|
# Check if the body is an iterable
|
||||||
|
chunks = iter(body)
|
||||||
|
content_length = None
|
||||||
|
except TypeError:
|
||||||
|
raise TypeError(
|
||||||
|
f"'body' must be a bytes-like object, file-like "
|
||||||
|
f"object, or iterable. Instead was {body!r}"
|
||||||
|
) from None
|
||||||
|
else:
|
||||||
|
# Since it implements the buffer API can be passed directly to socket.sendall()
|
||||||
|
chunks = (body,)
|
||||||
|
content_length = mv.nbytes
|
||||||
|
|
||||||
|
return ChunksAndContentLength(chunks=chunks, content_length=content_length)
|
||||||
101
venv/lib/python3.12/site-packages/urllib3/util/response.py
Normal file
101
venv/lib/python3.12/site-packages/urllib3/util/response.py
Normal file
@@ -0,0 +1,101 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import http.client as httplib
|
||||||
|
from email.errors import MultipartInvariantViolationDefect, StartBoundaryNotFoundDefect
|
||||||
|
|
||||||
|
from ..exceptions import HeaderParsingError
|
||||||
|
|
||||||
|
|
||||||
|
def is_fp_closed(obj: object) -> bool:
|
||||||
|
"""
|
||||||
|
Checks whether a given file-like object is closed.
|
||||||
|
|
||||||
|
:param obj:
|
||||||
|
The file-like object to check.
|
||||||
|
"""
|
||||||
|
|
||||||
|
try:
|
||||||
|
# Check `isclosed()` first, in case Python3 doesn't set `closed`.
|
||||||
|
# GH Issue #928
|
||||||
|
return obj.isclosed() # type: ignore[no-any-return, attr-defined]
|
||||||
|
except AttributeError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
try:
|
||||||
|
# Check via the official file-like-object way.
|
||||||
|
return obj.closed # type: ignore[no-any-return, attr-defined]
|
||||||
|
except AttributeError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
try:
|
||||||
|
# Check if the object is a container for another file-like object that
|
||||||
|
# gets released on exhaustion (e.g. HTTPResponse).
|
||||||
|
return obj.fp is None # type: ignore[attr-defined]
|
||||||
|
except AttributeError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
raise ValueError("Unable to determine whether fp is closed.")
|
||||||
|
|
||||||
|
|
||||||
|
def assert_header_parsing(headers: httplib.HTTPMessage) -> None:
|
||||||
|
"""
|
||||||
|
Asserts whether all headers have been successfully parsed.
|
||||||
|
Extracts encountered errors from the result of parsing headers.
|
||||||
|
|
||||||
|
Only works on Python 3.
|
||||||
|
|
||||||
|
:param http.client.HTTPMessage headers: Headers to verify.
|
||||||
|
|
||||||
|
:raises urllib3.exceptions.HeaderParsingError:
|
||||||
|
If parsing errors are found.
|
||||||
|
"""
|
||||||
|
|
||||||
|
# This will fail silently if we pass in the wrong kind of parameter.
|
||||||
|
# To make debugging easier add an explicit check.
|
||||||
|
if not isinstance(headers, httplib.HTTPMessage):
|
||||||
|
raise TypeError(f"expected httplib.Message, got {type(headers)}.")
|
||||||
|
|
||||||
|
unparsed_data = None
|
||||||
|
|
||||||
|
# get_payload is actually email.message.Message.get_payload;
|
||||||
|
# we're only interested in the result if it's not a multipart message
|
||||||
|
if not headers.is_multipart():
|
||||||
|
payload = headers.get_payload()
|
||||||
|
|
||||||
|
if isinstance(payload, (bytes, str)):
|
||||||
|
unparsed_data = payload
|
||||||
|
|
||||||
|
# httplib is assuming a response body is available
|
||||||
|
# when parsing headers even when httplib only sends
|
||||||
|
# header data to parse_headers() This results in
|
||||||
|
# defects on multipart responses in particular.
|
||||||
|
# See: https://github.com/urllib3/urllib3/issues/800
|
||||||
|
|
||||||
|
# So we ignore the following defects:
|
||||||
|
# - StartBoundaryNotFoundDefect:
|
||||||
|
# The claimed start boundary was never found.
|
||||||
|
# - MultipartInvariantViolationDefect:
|
||||||
|
# A message claimed to be a multipart but no subparts were found.
|
||||||
|
defects = [
|
||||||
|
defect
|
||||||
|
for defect in headers.defects
|
||||||
|
if not isinstance(
|
||||||
|
defect, (StartBoundaryNotFoundDefect, MultipartInvariantViolationDefect)
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
if defects or unparsed_data:
|
||||||
|
raise HeaderParsingError(defects=defects, unparsed_data=unparsed_data)
|
||||||
|
|
||||||
|
|
||||||
|
def is_response_to_head(response: httplib.HTTPResponse) -> bool:
|
||||||
|
"""
|
||||||
|
Checks whether the request of a response has been a HEAD-request.
|
||||||
|
|
||||||
|
:param http.client.HTTPResponse response:
|
||||||
|
Response to check if the originating request
|
||||||
|
used 'HEAD' as a method.
|
||||||
|
"""
|
||||||
|
# FIXME: Can we do this somehow without accessing private httplib _method?
|
||||||
|
method_str = response._method # type: str # type: ignore[attr-defined]
|
||||||
|
return method_str.upper() == "HEAD"
|
||||||
533
venv/lib/python3.12/site-packages/urllib3/util/retry.py
Normal file
533
venv/lib/python3.12/site-packages/urllib3/util/retry.py
Normal file
@@ -0,0 +1,533 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import email
|
||||||
|
import logging
|
||||||
|
import random
|
||||||
|
import re
|
||||||
|
import time
|
||||||
|
import typing
|
||||||
|
from itertools import takewhile
|
||||||
|
from types import TracebackType
|
||||||
|
|
||||||
|
from ..exceptions import (
|
||||||
|
ConnectTimeoutError,
|
||||||
|
InvalidHeader,
|
||||||
|
MaxRetryError,
|
||||||
|
ProtocolError,
|
||||||
|
ProxyError,
|
||||||
|
ReadTimeoutError,
|
||||||
|
ResponseError,
|
||||||
|
)
|
||||||
|
from .util import reraise
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from typing_extensions import Self
|
||||||
|
|
||||||
|
from ..connectionpool import ConnectionPool
|
||||||
|
from ..response import BaseHTTPResponse
|
||||||
|
|
||||||
|
log = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
# Data structure for representing the metadata of requests that result in a retry.
|
||||||
|
class RequestHistory(typing.NamedTuple):
|
||||||
|
method: str | None
|
||||||
|
url: str | None
|
||||||
|
error: Exception | None
|
||||||
|
status: int | None
|
||||||
|
redirect_location: str | None
|
||||||
|
|
||||||
|
|
||||||
|
class Retry:
|
||||||
|
"""Retry configuration.
|
||||||
|
|
||||||
|
Each retry attempt will create a new Retry object with updated values, so
|
||||||
|
they can be safely reused.
|
||||||
|
|
||||||
|
Retries can be defined as a default for a pool:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
retries = Retry(connect=5, read=2, redirect=5)
|
||||||
|
http = PoolManager(retries=retries)
|
||||||
|
response = http.request("GET", "https://example.com/")
|
||||||
|
|
||||||
|
Or per-request (which overrides the default for the pool):
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
response = http.request("GET", "https://example.com/", retries=Retry(10))
|
||||||
|
|
||||||
|
Retries can be disabled by passing ``False``:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
response = http.request("GET", "https://example.com/", retries=False)
|
||||||
|
|
||||||
|
Errors will be wrapped in :class:`~urllib3.exceptions.MaxRetryError` unless
|
||||||
|
retries are disabled, in which case the causing exception will be raised.
|
||||||
|
|
||||||
|
:param int total:
|
||||||
|
Total number of retries to allow. Takes precedence over other counts.
|
||||||
|
|
||||||
|
Set to ``None`` to remove this constraint and fall back on other
|
||||||
|
counts.
|
||||||
|
|
||||||
|
Set to ``0`` to fail on the first retry.
|
||||||
|
|
||||||
|
Set to ``False`` to disable and imply ``raise_on_redirect=False``.
|
||||||
|
|
||||||
|
:param int connect:
|
||||||
|
How many connection-related errors to retry on.
|
||||||
|
|
||||||
|
These are errors raised before the request is sent to the remote server,
|
||||||
|
which we assume has not triggered the server to process the request.
|
||||||
|
|
||||||
|
Set to ``0`` to fail on the first retry of this type.
|
||||||
|
|
||||||
|
:param int read:
|
||||||
|
How many times to retry on read errors.
|
||||||
|
|
||||||
|
These errors are raised after the request was sent to the server, so the
|
||||||
|
request may have side-effects.
|
||||||
|
|
||||||
|
Set to ``0`` to fail on the first retry of this type.
|
||||||
|
|
||||||
|
:param int redirect:
|
||||||
|
How many redirects to perform. Limit this to avoid infinite redirect
|
||||||
|
loops.
|
||||||
|
|
||||||
|
A redirect is a HTTP response with a status code 301, 302, 303, 307 or
|
||||||
|
308.
|
||||||
|
|
||||||
|
Set to ``0`` to fail on the first retry of this type.
|
||||||
|
|
||||||
|
Set to ``False`` to disable and imply ``raise_on_redirect=False``.
|
||||||
|
|
||||||
|
:param int status:
|
||||||
|
How many times to retry on bad status codes.
|
||||||
|
|
||||||
|
These are retries made on responses, where status code matches
|
||||||
|
``status_forcelist``.
|
||||||
|
|
||||||
|
Set to ``0`` to fail on the first retry of this type.
|
||||||
|
|
||||||
|
:param int other:
|
||||||
|
How many times to retry on other errors.
|
||||||
|
|
||||||
|
Other errors are errors that are not connect, read, redirect or status errors.
|
||||||
|
These errors might be raised after the request was sent to the server, so the
|
||||||
|
request might have side-effects.
|
||||||
|
|
||||||
|
Set to ``0`` to fail on the first retry of this type.
|
||||||
|
|
||||||
|
If ``total`` is not set, it's a good idea to set this to 0 to account
|
||||||
|
for unexpected edge cases and avoid infinite retry loops.
|
||||||
|
|
||||||
|
:param Collection allowed_methods:
|
||||||
|
Set of uppercased HTTP method verbs that we should retry on.
|
||||||
|
|
||||||
|
By default, we only retry on methods which are considered to be
|
||||||
|
idempotent (multiple requests with the same parameters end with the
|
||||||
|
same state). See :attr:`Retry.DEFAULT_ALLOWED_METHODS`.
|
||||||
|
|
||||||
|
Set to a ``None`` value to retry on any verb.
|
||||||
|
|
||||||
|
:param Collection status_forcelist:
|
||||||
|
A set of integer HTTP status codes that we should force a retry on.
|
||||||
|
A retry is initiated if the request method is in ``allowed_methods``
|
||||||
|
and the response status code is in ``status_forcelist``.
|
||||||
|
|
||||||
|
By default, this is disabled with ``None``.
|
||||||
|
|
||||||
|
:param float backoff_factor:
|
||||||
|
A backoff factor to apply between attempts after the second try
|
||||||
|
(most errors are resolved immediately by a second try without a
|
||||||
|
delay). urllib3 will sleep for::
|
||||||
|
|
||||||
|
{backoff factor} * (2 ** ({number of previous retries}))
|
||||||
|
|
||||||
|
seconds. If `backoff_jitter` is non-zero, this sleep is extended by::
|
||||||
|
|
||||||
|
random.uniform(0, {backoff jitter})
|
||||||
|
|
||||||
|
seconds. For example, if the backoff_factor is 0.1, then :func:`Retry.sleep` will
|
||||||
|
sleep for [0.0s, 0.2s, 0.4s, 0.8s, ...] between retries. No backoff will ever
|
||||||
|
be longer than `backoff_max`.
|
||||||
|
|
||||||
|
By default, backoff is disabled (factor set to 0).
|
||||||
|
|
||||||
|
:param bool raise_on_redirect: Whether, if the number of redirects is
|
||||||
|
exhausted, to raise a MaxRetryError, or to return a response with a
|
||||||
|
response code in the 3xx range.
|
||||||
|
|
||||||
|
:param bool raise_on_status: Similar meaning to ``raise_on_redirect``:
|
||||||
|
whether we should raise an exception, or return a response,
|
||||||
|
if status falls in ``status_forcelist`` range and retries have
|
||||||
|
been exhausted.
|
||||||
|
|
||||||
|
:param tuple history: The history of the request encountered during
|
||||||
|
each call to :meth:`~Retry.increment`. The list is in the order
|
||||||
|
the requests occurred. Each list item is of class :class:`RequestHistory`.
|
||||||
|
|
||||||
|
:param bool respect_retry_after_header:
|
||||||
|
Whether to respect Retry-After header on status codes defined as
|
||||||
|
:attr:`Retry.RETRY_AFTER_STATUS_CODES` or not.
|
||||||
|
|
||||||
|
:param Collection remove_headers_on_redirect:
|
||||||
|
Sequence of headers to remove from the request when a response
|
||||||
|
indicating a redirect is returned before firing off the redirected
|
||||||
|
request.
|
||||||
|
"""
|
||||||
|
|
||||||
|
#: Default methods to be used for ``allowed_methods``
|
||||||
|
DEFAULT_ALLOWED_METHODS = frozenset(
|
||||||
|
["HEAD", "GET", "PUT", "DELETE", "OPTIONS", "TRACE"]
|
||||||
|
)
|
||||||
|
|
||||||
|
#: Default status codes to be used for ``status_forcelist``
|
||||||
|
RETRY_AFTER_STATUS_CODES = frozenset([413, 429, 503])
|
||||||
|
|
||||||
|
#: Default headers to be used for ``remove_headers_on_redirect``
|
||||||
|
DEFAULT_REMOVE_HEADERS_ON_REDIRECT = frozenset(
|
||||||
|
["Cookie", "Authorization", "Proxy-Authorization"]
|
||||||
|
)
|
||||||
|
|
||||||
|
#: Default maximum backoff time.
|
||||||
|
DEFAULT_BACKOFF_MAX = 120
|
||||||
|
|
||||||
|
# Backward compatibility; assigned outside of the class.
|
||||||
|
DEFAULT: typing.ClassVar[Retry]
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
total: bool | int | None = 10,
|
||||||
|
connect: int | None = None,
|
||||||
|
read: int | None = None,
|
||||||
|
redirect: bool | int | None = None,
|
||||||
|
status: int | None = None,
|
||||||
|
other: int | None = None,
|
||||||
|
allowed_methods: typing.Collection[str] | None = DEFAULT_ALLOWED_METHODS,
|
||||||
|
status_forcelist: typing.Collection[int] | None = None,
|
||||||
|
backoff_factor: float = 0,
|
||||||
|
backoff_max: float = DEFAULT_BACKOFF_MAX,
|
||||||
|
raise_on_redirect: bool = True,
|
||||||
|
raise_on_status: bool = True,
|
||||||
|
history: tuple[RequestHistory, ...] | None = None,
|
||||||
|
respect_retry_after_header: bool = True,
|
||||||
|
remove_headers_on_redirect: typing.Collection[
|
||||||
|
str
|
||||||
|
] = DEFAULT_REMOVE_HEADERS_ON_REDIRECT,
|
||||||
|
backoff_jitter: float = 0.0,
|
||||||
|
) -> None:
|
||||||
|
self.total = total
|
||||||
|
self.connect = connect
|
||||||
|
self.read = read
|
||||||
|
self.status = status
|
||||||
|
self.other = other
|
||||||
|
|
||||||
|
if redirect is False or total is False:
|
||||||
|
redirect = 0
|
||||||
|
raise_on_redirect = False
|
||||||
|
|
||||||
|
self.redirect = redirect
|
||||||
|
self.status_forcelist = status_forcelist or set()
|
||||||
|
self.allowed_methods = allowed_methods
|
||||||
|
self.backoff_factor = backoff_factor
|
||||||
|
self.backoff_max = backoff_max
|
||||||
|
self.raise_on_redirect = raise_on_redirect
|
||||||
|
self.raise_on_status = raise_on_status
|
||||||
|
self.history = history or ()
|
||||||
|
self.respect_retry_after_header = respect_retry_after_header
|
||||||
|
self.remove_headers_on_redirect = frozenset(
|
||||||
|
h.lower() for h in remove_headers_on_redirect
|
||||||
|
)
|
||||||
|
self.backoff_jitter = backoff_jitter
|
||||||
|
|
||||||
|
def new(self, **kw: typing.Any) -> Self:
|
||||||
|
params = dict(
|
||||||
|
total=self.total,
|
||||||
|
connect=self.connect,
|
||||||
|
read=self.read,
|
||||||
|
redirect=self.redirect,
|
||||||
|
status=self.status,
|
||||||
|
other=self.other,
|
||||||
|
allowed_methods=self.allowed_methods,
|
||||||
|
status_forcelist=self.status_forcelist,
|
||||||
|
backoff_factor=self.backoff_factor,
|
||||||
|
backoff_max=self.backoff_max,
|
||||||
|
raise_on_redirect=self.raise_on_redirect,
|
||||||
|
raise_on_status=self.raise_on_status,
|
||||||
|
history=self.history,
|
||||||
|
remove_headers_on_redirect=self.remove_headers_on_redirect,
|
||||||
|
respect_retry_after_header=self.respect_retry_after_header,
|
||||||
|
backoff_jitter=self.backoff_jitter,
|
||||||
|
)
|
||||||
|
|
||||||
|
params.update(kw)
|
||||||
|
return type(self)(**params) # type: ignore[arg-type]
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_int(
|
||||||
|
cls,
|
||||||
|
retries: Retry | bool | int | None,
|
||||||
|
redirect: bool | int | None = True,
|
||||||
|
default: Retry | bool | int | None = None,
|
||||||
|
) -> Retry:
|
||||||
|
"""Backwards-compatibility for the old retries format."""
|
||||||
|
if retries is None:
|
||||||
|
retries = default if default is not None else cls.DEFAULT
|
||||||
|
|
||||||
|
if isinstance(retries, Retry):
|
||||||
|
return retries
|
||||||
|
|
||||||
|
redirect = bool(redirect) and None
|
||||||
|
new_retries = cls(retries, redirect=redirect)
|
||||||
|
log.debug("Converted retries value: %r -> %r", retries, new_retries)
|
||||||
|
return new_retries
|
||||||
|
|
||||||
|
def get_backoff_time(self) -> float:
|
||||||
|
"""Formula for computing the current backoff
|
||||||
|
|
||||||
|
:rtype: float
|
||||||
|
"""
|
||||||
|
# We want to consider only the last consecutive errors sequence (Ignore redirects).
|
||||||
|
consecutive_errors_len = len(
|
||||||
|
list(
|
||||||
|
takewhile(lambda x: x.redirect_location is None, reversed(self.history))
|
||||||
|
)
|
||||||
|
)
|
||||||
|
if consecutive_errors_len <= 1:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
backoff_value = self.backoff_factor * (2 ** (consecutive_errors_len - 1))
|
||||||
|
if self.backoff_jitter != 0.0:
|
||||||
|
backoff_value += random.random() * self.backoff_jitter
|
||||||
|
return float(max(0, min(self.backoff_max, backoff_value)))
|
||||||
|
|
||||||
|
def parse_retry_after(self, retry_after: str) -> float:
|
||||||
|
seconds: float
|
||||||
|
# Whitespace: https://tools.ietf.org/html/rfc7230#section-3.2.4
|
||||||
|
if re.match(r"^\s*[0-9]+\s*$", retry_after):
|
||||||
|
seconds = int(retry_after)
|
||||||
|
else:
|
||||||
|
retry_date_tuple = email.utils.parsedate_tz(retry_after)
|
||||||
|
if retry_date_tuple is None:
|
||||||
|
raise InvalidHeader(f"Invalid Retry-After header: {retry_after}")
|
||||||
|
|
||||||
|
retry_date = email.utils.mktime_tz(retry_date_tuple)
|
||||||
|
seconds = retry_date - time.time()
|
||||||
|
|
||||||
|
seconds = max(seconds, 0)
|
||||||
|
|
||||||
|
return seconds
|
||||||
|
|
||||||
|
def get_retry_after(self, response: BaseHTTPResponse) -> float | None:
|
||||||
|
"""Get the value of Retry-After in seconds."""
|
||||||
|
|
||||||
|
retry_after = response.headers.get("Retry-After")
|
||||||
|
|
||||||
|
if retry_after is None:
|
||||||
|
return None
|
||||||
|
|
||||||
|
return self.parse_retry_after(retry_after)
|
||||||
|
|
||||||
|
def sleep_for_retry(self, response: BaseHTTPResponse) -> bool:
|
||||||
|
retry_after = self.get_retry_after(response)
|
||||||
|
if retry_after:
|
||||||
|
time.sleep(retry_after)
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
def _sleep_backoff(self) -> None:
|
||||||
|
backoff = self.get_backoff_time()
|
||||||
|
if backoff <= 0:
|
||||||
|
return
|
||||||
|
time.sleep(backoff)
|
||||||
|
|
||||||
|
def sleep(self, response: BaseHTTPResponse | None = None) -> None:
|
||||||
|
"""Sleep between retry attempts.
|
||||||
|
|
||||||
|
This method will respect a server's ``Retry-After`` response header
|
||||||
|
and sleep the duration of the time requested. If that is not present, it
|
||||||
|
will use an exponential backoff. By default, the backoff factor is 0 and
|
||||||
|
this method will return immediately.
|
||||||
|
"""
|
||||||
|
|
||||||
|
if self.respect_retry_after_header and response:
|
||||||
|
slept = self.sleep_for_retry(response)
|
||||||
|
if slept:
|
||||||
|
return
|
||||||
|
|
||||||
|
self._sleep_backoff()
|
||||||
|
|
||||||
|
def _is_connection_error(self, err: Exception) -> bool:
|
||||||
|
"""Errors when we're fairly sure that the server did not receive the
|
||||||
|
request, so it should be safe to retry.
|
||||||
|
"""
|
||||||
|
if isinstance(err, ProxyError):
|
||||||
|
err = err.original_error
|
||||||
|
return isinstance(err, ConnectTimeoutError)
|
||||||
|
|
||||||
|
def _is_read_error(self, err: Exception) -> bool:
|
||||||
|
"""Errors that occur after the request has been started, so we should
|
||||||
|
assume that the server began processing it.
|
||||||
|
"""
|
||||||
|
return isinstance(err, (ReadTimeoutError, ProtocolError))
|
||||||
|
|
||||||
|
def _is_method_retryable(self, method: str) -> bool:
|
||||||
|
"""Checks if a given HTTP method should be retried upon, depending if
|
||||||
|
it is included in the allowed_methods
|
||||||
|
"""
|
||||||
|
if self.allowed_methods and method.upper() not in self.allowed_methods:
|
||||||
|
return False
|
||||||
|
return True
|
||||||
|
|
||||||
|
def is_retry(
|
||||||
|
self, method: str, status_code: int, has_retry_after: bool = False
|
||||||
|
) -> bool:
|
||||||
|
"""Is this method/status code retryable? (Based on allowlists and control
|
||||||
|
variables such as the number of total retries to allow, whether to
|
||||||
|
respect the Retry-After header, whether this header is present, and
|
||||||
|
whether the returned status code is on the list of status codes to
|
||||||
|
be retried upon on the presence of the aforementioned header)
|
||||||
|
"""
|
||||||
|
if not self._is_method_retryable(method):
|
||||||
|
return False
|
||||||
|
|
||||||
|
if self.status_forcelist and status_code in self.status_forcelist:
|
||||||
|
return True
|
||||||
|
|
||||||
|
return bool(
|
||||||
|
self.total
|
||||||
|
and self.respect_retry_after_header
|
||||||
|
and has_retry_after
|
||||||
|
and (status_code in self.RETRY_AFTER_STATUS_CODES)
|
||||||
|
)
|
||||||
|
|
||||||
|
def is_exhausted(self) -> bool:
|
||||||
|
"""Are we out of retries?"""
|
||||||
|
retry_counts = [
|
||||||
|
x
|
||||||
|
for x in (
|
||||||
|
self.total,
|
||||||
|
self.connect,
|
||||||
|
self.read,
|
||||||
|
self.redirect,
|
||||||
|
self.status,
|
||||||
|
self.other,
|
||||||
|
)
|
||||||
|
if x
|
||||||
|
]
|
||||||
|
if not retry_counts:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return min(retry_counts) < 0
|
||||||
|
|
||||||
|
def increment(
|
||||||
|
self,
|
||||||
|
method: str | None = None,
|
||||||
|
url: str | None = None,
|
||||||
|
response: BaseHTTPResponse | None = None,
|
||||||
|
error: Exception | None = None,
|
||||||
|
_pool: ConnectionPool | None = None,
|
||||||
|
_stacktrace: TracebackType | None = None,
|
||||||
|
) -> Self:
|
||||||
|
"""Return a new Retry object with incremented retry counters.
|
||||||
|
|
||||||
|
:param response: A response object, or None, if the server did not
|
||||||
|
return a response.
|
||||||
|
:type response: :class:`~urllib3.response.BaseHTTPResponse`
|
||||||
|
:param Exception error: An error encountered during the request, or
|
||||||
|
None if the response was received successfully.
|
||||||
|
|
||||||
|
:return: A new ``Retry`` object.
|
||||||
|
"""
|
||||||
|
if self.total is False and error:
|
||||||
|
# Disabled, indicate to re-raise the error.
|
||||||
|
raise reraise(type(error), error, _stacktrace)
|
||||||
|
|
||||||
|
total = self.total
|
||||||
|
if total is not None:
|
||||||
|
total -= 1
|
||||||
|
|
||||||
|
connect = self.connect
|
||||||
|
read = self.read
|
||||||
|
redirect = self.redirect
|
||||||
|
status_count = self.status
|
||||||
|
other = self.other
|
||||||
|
cause = "unknown"
|
||||||
|
status = None
|
||||||
|
redirect_location = None
|
||||||
|
|
||||||
|
if error and self._is_connection_error(error):
|
||||||
|
# Connect retry?
|
||||||
|
if connect is False:
|
||||||
|
raise reraise(type(error), error, _stacktrace)
|
||||||
|
elif connect is not None:
|
||||||
|
connect -= 1
|
||||||
|
|
||||||
|
elif error and self._is_read_error(error):
|
||||||
|
# Read retry?
|
||||||
|
if read is False or method is None or not self._is_method_retryable(method):
|
||||||
|
raise reraise(type(error), error, _stacktrace)
|
||||||
|
elif read is not None:
|
||||||
|
read -= 1
|
||||||
|
|
||||||
|
elif error:
|
||||||
|
# Other retry?
|
||||||
|
if other is not None:
|
||||||
|
other -= 1
|
||||||
|
|
||||||
|
elif response and response.get_redirect_location():
|
||||||
|
# Redirect retry?
|
||||||
|
if redirect is not None:
|
||||||
|
redirect -= 1
|
||||||
|
cause = "too many redirects"
|
||||||
|
response_redirect_location = response.get_redirect_location()
|
||||||
|
if response_redirect_location:
|
||||||
|
redirect_location = response_redirect_location
|
||||||
|
status = response.status
|
||||||
|
|
||||||
|
else:
|
||||||
|
# Incrementing because of a server error like a 500 in
|
||||||
|
# status_forcelist and the given method is in the allowed_methods
|
||||||
|
cause = ResponseError.GENERIC_ERROR
|
||||||
|
if response and response.status:
|
||||||
|
if status_count is not None:
|
||||||
|
status_count -= 1
|
||||||
|
cause = ResponseError.SPECIFIC_ERROR.format(status_code=response.status)
|
||||||
|
status = response.status
|
||||||
|
|
||||||
|
history = self.history + (
|
||||||
|
RequestHistory(method, url, error, status, redirect_location),
|
||||||
|
)
|
||||||
|
|
||||||
|
new_retry = self.new(
|
||||||
|
total=total,
|
||||||
|
connect=connect,
|
||||||
|
read=read,
|
||||||
|
redirect=redirect,
|
||||||
|
status=status_count,
|
||||||
|
other=other,
|
||||||
|
history=history,
|
||||||
|
)
|
||||||
|
|
||||||
|
if new_retry.is_exhausted():
|
||||||
|
reason = error or ResponseError(cause)
|
||||||
|
raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type]
|
||||||
|
|
||||||
|
log.debug("Incremented Retry for (url='%s'): %r", url, new_retry)
|
||||||
|
|
||||||
|
return new_retry
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
return (
|
||||||
|
f"{type(self).__name__}(total={self.total}, connect={self.connect}, "
|
||||||
|
f"read={self.read}, redirect={self.redirect}, status={self.status})"
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
# For backwards compatibility (equivalent to pre-v1.9):
|
||||||
|
Retry.DEFAULT = Retry(3)
|
||||||
524
venv/lib/python3.12/site-packages/urllib3/util/ssl_.py
Normal file
524
venv/lib/python3.12/site-packages/urllib3/util/ssl_.py
Normal file
@@ -0,0 +1,524 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import hashlib
|
||||||
|
import hmac
|
||||||
|
import os
|
||||||
|
import socket
|
||||||
|
import sys
|
||||||
|
import typing
|
||||||
|
import warnings
|
||||||
|
from binascii import unhexlify
|
||||||
|
|
||||||
|
from ..exceptions import ProxySchemeUnsupported, SSLError
|
||||||
|
from .url import _BRACELESS_IPV6_ADDRZ_RE, _IPV4_RE
|
||||||
|
|
||||||
|
SSLContext = None
|
||||||
|
SSLTransport = None
|
||||||
|
HAS_NEVER_CHECK_COMMON_NAME = False
|
||||||
|
IS_PYOPENSSL = False
|
||||||
|
ALPN_PROTOCOLS = ["http/1.1"]
|
||||||
|
|
||||||
|
_TYPE_VERSION_INFO = tuple[int, int, int, str, int]
|
||||||
|
|
||||||
|
# Maps the length of a digest to a possible hash function producing this digest
|
||||||
|
HASHFUNC_MAP = {
|
||||||
|
length: getattr(hashlib, algorithm, None)
|
||||||
|
for length, algorithm in ((32, "md5"), (40, "sha1"), (64, "sha256"))
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def _is_bpo_43522_fixed(
|
||||||
|
implementation_name: str,
|
||||||
|
version_info: _TYPE_VERSION_INFO,
|
||||||
|
pypy_version_info: _TYPE_VERSION_INFO | None,
|
||||||
|
) -> bool:
|
||||||
|
"""Return True for CPython 3.9.3+ or 3.10+ and PyPy 7.3.8+ where
|
||||||
|
setting SSLContext.hostname_checks_common_name to False works.
|
||||||
|
|
||||||
|
Outside of CPython and PyPy we don't know which implementations work
|
||||||
|
or not so we conservatively use our hostname matching as we know that works
|
||||||
|
on all implementations.
|
||||||
|
|
||||||
|
https://github.com/urllib3/urllib3/issues/2192#issuecomment-821832963
|
||||||
|
https://foss.heptapod.net/pypy/pypy/-/issues/3539
|
||||||
|
"""
|
||||||
|
if implementation_name == "pypy":
|
||||||
|
# https://foss.heptapod.net/pypy/pypy/-/issues/3129
|
||||||
|
return pypy_version_info >= (7, 3, 8) # type: ignore[operator]
|
||||||
|
elif implementation_name == "cpython":
|
||||||
|
major_minor = version_info[:2]
|
||||||
|
micro = version_info[2]
|
||||||
|
return (major_minor == (3, 9) and micro >= 3) or major_minor >= (3, 10)
|
||||||
|
else: # Defensive:
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def _is_has_never_check_common_name_reliable(
|
||||||
|
openssl_version: str,
|
||||||
|
openssl_version_number: int,
|
||||||
|
implementation_name: str,
|
||||||
|
version_info: _TYPE_VERSION_INFO,
|
||||||
|
pypy_version_info: _TYPE_VERSION_INFO | None,
|
||||||
|
) -> bool:
|
||||||
|
# As of May 2023, all released versions of LibreSSL fail to reject certificates with
|
||||||
|
# only common names, see https://github.com/urllib3/urllib3/pull/3024
|
||||||
|
is_openssl = openssl_version.startswith("OpenSSL ")
|
||||||
|
# Before fixing OpenSSL issue #14579, the SSL_new() API was not copying hostflags
|
||||||
|
# like X509_CHECK_FLAG_NEVER_CHECK_SUBJECT, which tripped up CPython.
|
||||||
|
# https://github.com/openssl/openssl/issues/14579
|
||||||
|
# This was released in OpenSSL 1.1.1l+ (>=0x101010cf)
|
||||||
|
is_openssl_issue_14579_fixed = openssl_version_number >= 0x101010CF
|
||||||
|
|
||||||
|
return is_openssl and (
|
||||||
|
is_openssl_issue_14579_fixed
|
||||||
|
or _is_bpo_43522_fixed(implementation_name, version_info, pypy_version_info)
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from ssl import VerifyMode
|
||||||
|
from typing import TypedDict
|
||||||
|
|
||||||
|
from .ssltransport import SSLTransport as SSLTransportType
|
||||||
|
|
||||||
|
class _TYPE_PEER_CERT_RET_DICT(TypedDict, total=False):
|
||||||
|
subjectAltName: tuple[tuple[str, str], ...]
|
||||||
|
subject: tuple[tuple[tuple[str, str], ...], ...]
|
||||||
|
serialNumber: str
|
||||||
|
|
||||||
|
|
||||||
|
# Mapping from 'ssl.PROTOCOL_TLSX' to 'TLSVersion.X'
|
||||||
|
_SSL_VERSION_TO_TLS_VERSION: dict[int, int] = {}
|
||||||
|
|
||||||
|
try: # Do we have ssl at all?
|
||||||
|
import ssl
|
||||||
|
from ssl import ( # type: ignore[assignment]
|
||||||
|
CERT_REQUIRED,
|
||||||
|
HAS_NEVER_CHECK_COMMON_NAME,
|
||||||
|
OP_NO_COMPRESSION,
|
||||||
|
OP_NO_TICKET,
|
||||||
|
OPENSSL_VERSION,
|
||||||
|
OPENSSL_VERSION_NUMBER,
|
||||||
|
PROTOCOL_TLS,
|
||||||
|
PROTOCOL_TLS_CLIENT,
|
||||||
|
VERIFY_X509_STRICT,
|
||||||
|
OP_NO_SSLv2,
|
||||||
|
OP_NO_SSLv3,
|
||||||
|
SSLContext,
|
||||||
|
TLSVersion,
|
||||||
|
)
|
||||||
|
|
||||||
|
PROTOCOL_SSLv23 = PROTOCOL_TLS
|
||||||
|
|
||||||
|
# Needed for Python 3.9 which does not define this
|
||||||
|
VERIFY_X509_PARTIAL_CHAIN = getattr(ssl, "VERIFY_X509_PARTIAL_CHAIN", 0x80000)
|
||||||
|
|
||||||
|
# Setting SSLContext.hostname_checks_common_name = False didn't work before CPython
|
||||||
|
# 3.9.3, and 3.10 (but OK on PyPy) or OpenSSL 1.1.1l+
|
||||||
|
if HAS_NEVER_CHECK_COMMON_NAME and not _is_has_never_check_common_name_reliable(
|
||||||
|
OPENSSL_VERSION,
|
||||||
|
OPENSSL_VERSION_NUMBER,
|
||||||
|
sys.implementation.name,
|
||||||
|
sys.version_info,
|
||||||
|
sys.pypy_version_info if sys.implementation.name == "pypy" else None, # type: ignore[attr-defined]
|
||||||
|
): # Defensive: for Python < 3.9.3
|
||||||
|
HAS_NEVER_CHECK_COMMON_NAME = False
|
||||||
|
|
||||||
|
# Need to be careful here in case old TLS versions get
|
||||||
|
# removed in future 'ssl' module implementations.
|
||||||
|
for attr in ("TLSv1", "TLSv1_1", "TLSv1_2"):
|
||||||
|
try:
|
||||||
|
_SSL_VERSION_TO_TLS_VERSION[getattr(ssl, f"PROTOCOL_{attr}")] = getattr(
|
||||||
|
TLSVersion, attr
|
||||||
|
)
|
||||||
|
except AttributeError: # Defensive:
|
||||||
|
continue
|
||||||
|
|
||||||
|
from .ssltransport import SSLTransport # type: ignore[assignment]
|
||||||
|
except ImportError:
|
||||||
|
OP_NO_COMPRESSION = 0x20000 # type: ignore[assignment]
|
||||||
|
OP_NO_TICKET = 0x4000 # type: ignore[assignment]
|
||||||
|
OP_NO_SSLv2 = 0x1000000 # type: ignore[assignment]
|
||||||
|
OP_NO_SSLv3 = 0x2000000 # type: ignore[assignment]
|
||||||
|
PROTOCOL_SSLv23 = PROTOCOL_TLS = 2 # type: ignore[assignment]
|
||||||
|
PROTOCOL_TLS_CLIENT = 16 # type: ignore[assignment]
|
||||||
|
VERIFY_X509_PARTIAL_CHAIN = 0x80000
|
||||||
|
VERIFY_X509_STRICT = 0x20 # type: ignore[assignment]
|
||||||
|
|
||||||
|
|
||||||
|
_TYPE_PEER_CERT_RET = typing.Union["_TYPE_PEER_CERT_RET_DICT", bytes, None]
|
||||||
|
|
||||||
|
|
||||||
|
def assert_fingerprint(cert: bytes | None, fingerprint: str) -> None:
|
||||||
|
"""
|
||||||
|
Checks if given fingerprint matches the supplied certificate.
|
||||||
|
|
||||||
|
:param cert:
|
||||||
|
Certificate as bytes object.
|
||||||
|
:param fingerprint:
|
||||||
|
Fingerprint as string of hexdigits, can be interspersed by colons.
|
||||||
|
"""
|
||||||
|
|
||||||
|
if cert is None:
|
||||||
|
raise SSLError("No certificate for the peer.")
|
||||||
|
|
||||||
|
fingerprint = fingerprint.replace(":", "").lower()
|
||||||
|
digest_length = len(fingerprint)
|
||||||
|
if digest_length not in HASHFUNC_MAP:
|
||||||
|
raise SSLError(f"Fingerprint of invalid length: {fingerprint}")
|
||||||
|
hashfunc = HASHFUNC_MAP.get(digest_length)
|
||||||
|
if hashfunc is None:
|
||||||
|
raise SSLError(
|
||||||
|
f"Hash function implementation unavailable for fingerprint length: {digest_length}"
|
||||||
|
)
|
||||||
|
|
||||||
|
# We need encode() here for py32; works on py2 and p33.
|
||||||
|
fingerprint_bytes = unhexlify(fingerprint.encode())
|
||||||
|
|
||||||
|
cert_digest = hashfunc(cert).digest()
|
||||||
|
|
||||||
|
if not hmac.compare_digest(cert_digest, fingerprint_bytes):
|
||||||
|
raise SSLError(
|
||||||
|
f'Fingerprints did not match. Expected "{fingerprint}", got "{cert_digest.hex()}"'
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def resolve_cert_reqs(candidate: None | int | str) -> VerifyMode:
|
||||||
|
"""
|
||||||
|
Resolves the argument to a numeric constant, which can be passed to
|
||||||
|
the wrap_socket function/method from the ssl module.
|
||||||
|
Defaults to :data:`ssl.CERT_REQUIRED`.
|
||||||
|
If given a string it is assumed to be the name of the constant in the
|
||||||
|
:mod:`ssl` module or its abbreviation.
|
||||||
|
(So you can specify `REQUIRED` instead of `CERT_REQUIRED`.
|
||||||
|
If it's neither `None` nor a string we assume it is already the numeric
|
||||||
|
constant which can directly be passed to wrap_socket.
|
||||||
|
"""
|
||||||
|
if candidate is None:
|
||||||
|
return CERT_REQUIRED
|
||||||
|
|
||||||
|
if isinstance(candidate, str):
|
||||||
|
res = getattr(ssl, candidate, None)
|
||||||
|
if res is None:
|
||||||
|
res = getattr(ssl, "CERT_" + candidate)
|
||||||
|
return res # type: ignore[no-any-return]
|
||||||
|
|
||||||
|
return candidate # type: ignore[return-value]
|
||||||
|
|
||||||
|
|
||||||
|
def resolve_ssl_version(candidate: None | int | str) -> int:
|
||||||
|
"""
|
||||||
|
like resolve_cert_reqs
|
||||||
|
"""
|
||||||
|
if candidate is None:
|
||||||
|
return PROTOCOL_TLS
|
||||||
|
|
||||||
|
if isinstance(candidate, str):
|
||||||
|
res = getattr(ssl, candidate, None)
|
||||||
|
if res is None:
|
||||||
|
res = getattr(ssl, "PROTOCOL_" + candidate)
|
||||||
|
return typing.cast(int, res)
|
||||||
|
|
||||||
|
return candidate
|
||||||
|
|
||||||
|
|
||||||
|
def create_urllib3_context(
|
||||||
|
ssl_version: int | None = None,
|
||||||
|
cert_reqs: int | None = None,
|
||||||
|
options: int | None = None,
|
||||||
|
ciphers: str | None = None,
|
||||||
|
ssl_minimum_version: int | None = None,
|
||||||
|
ssl_maximum_version: int | None = None,
|
||||||
|
verify_flags: int | None = None,
|
||||||
|
) -> ssl.SSLContext:
|
||||||
|
"""Creates and configures an :class:`ssl.SSLContext` instance for use with urllib3.
|
||||||
|
|
||||||
|
:param ssl_version:
|
||||||
|
The desired protocol version to use. This will default to
|
||||||
|
PROTOCOL_SSLv23 which will negotiate the highest protocol that both
|
||||||
|
the server and your installation of OpenSSL support.
|
||||||
|
|
||||||
|
This parameter is deprecated instead use 'ssl_minimum_version'.
|
||||||
|
:param ssl_minimum_version:
|
||||||
|
The minimum version of TLS to be used. Use the 'ssl.TLSVersion' enum for specifying the value.
|
||||||
|
:param ssl_maximum_version:
|
||||||
|
The maximum version of TLS to be used. Use the 'ssl.TLSVersion' enum for specifying the value.
|
||||||
|
Not recommended to set to anything other than 'ssl.TLSVersion.MAXIMUM_SUPPORTED' which is the
|
||||||
|
default value.
|
||||||
|
:param cert_reqs:
|
||||||
|
Whether to require the certificate verification. This defaults to
|
||||||
|
``ssl.CERT_REQUIRED``.
|
||||||
|
:param options:
|
||||||
|
Specific OpenSSL options. These default to ``ssl.OP_NO_SSLv2``,
|
||||||
|
``ssl.OP_NO_SSLv3``, ``ssl.OP_NO_COMPRESSION``, and ``ssl.OP_NO_TICKET``.
|
||||||
|
:param ciphers:
|
||||||
|
Which cipher suites to allow the server to select. Defaults to either system configured
|
||||||
|
ciphers if OpenSSL 1.1.1+, otherwise uses a secure default set of ciphers.
|
||||||
|
:param verify_flags:
|
||||||
|
The flags for certificate verification operations. These default to
|
||||||
|
``ssl.VERIFY_X509_PARTIAL_CHAIN`` and ``ssl.VERIFY_X509_STRICT`` for Python 3.13+.
|
||||||
|
:returns:
|
||||||
|
Constructed SSLContext object with specified options
|
||||||
|
:rtype: SSLContext
|
||||||
|
"""
|
||||||
|
if SSLContext is None:
|
||||||
|
raise TypeError("Can't create an SSLContext object without an ssl module")
|
||||||
|
|
||||||
|
# This means 'ssl_version' was specified as an exact value.
|
||||||
|
if ssl_version not in (None, PROTOCOL_TLS, PROTOCOL_TLS_CLIENT):
|
||||||
|
# Disallow setting 'ssl_version' and 'ssl_minimum|maximum_version'
|
||||||
|
# to avoid conflicts.
|
||||||
|
if ssl_minimum_version is not None or ssl_maximum_version is not None:
|
||||||
|
raise ValueError(
|
||||||
|
"Can't specify both 'ssl_version' and either "
|
||||||
|
"'ssl_minimum_version' or 'ssl_maximum_version'"
|
||||||
|
)
|
||||||
|
|
||||||
|
# 'ssl_version' is deprecated and will be removed in the future.
|
||||||
|
else:
|
||||||
|
# Use 'ssl_minimum_version' and 'ssl_maximum_version' instead.
|
||||||
|
ssl_minimum_version = _SSL_VERSION_TO_TLS_VERSION.get(
|
||||||
|
ssl_version, TLSVersion.MINIMUM_SUPPORTED
|
||||||
|
)
|
||||||
|
ssl_maximum_version = _SSL_VERSION_TO_TLS_VERSION.get(
|
||||||
|
ssl_version, TLSVersion.MAXIMUM_SUPPORTED
|
||||||
|
)
|
||||||
|
|
||||||
|
# This warning message is pushing users to use 'ssl_minimum_version'
|
||||||
|
# instead of both min/max. Best practice is to only set the minimum version and
|
||||||
|
# keep the maximum version to be it's default value: 'TLSVersion.MAXIMUM_SUPPORTED'
|
||||||
|
warnings.warn(
|
||||||
|
"'ssl_version' option is deprecated and will be "
|
||||||
|
"removed in urllib3 v2.6.0. Instead use 'ssl_minimum_version'",
|
||||||
|
category=DeprecationWarning,
|
||||||
|
stacklevel=2,
|
||||||
|
)
|
||||||
|
|
||||||
|
# PROTOCOL_TLS is deprecated in Python 3.10 so we always use PROTOCOL_TLS_CLIENT
|
||||||
|
context = SSLContext(PROTOCOL_TLS_CLIENT)
|
||||||
|
|
||||||
|
if ssl_minimum_version is not None:
|
||||||
|
context.minimum_version = ssl_minimum_version
|
||||||
|
else: # Python <3.10 defaults to 'MINIMUM_SUPPORTED' so explicitly set TLSv1.2 here
|
||||||
|
context.minimum_version = TLSVersion.TLSv1_2
|
||||||
|
|
||||||
|
if ssl_maximum_version is not None:
|
||||||
|
context.maximum_version = ssl_maximum_version
|
||||||
|
|
||||||
|
# Unless we're given ciphers defer to either system ciphers in
|
||||||
|
# the case of OpenSSL 1.1.1+ or use our own secure default ciphers.
|
||||||
|
if ciphers:
|
||||||
|
context.set_ciphers(ciphers)
|
||||||
|
|
||||||
|
# Setting the default here, as we may have no ssl module on import
|
||||||
|
cert_reqs = ssl.CERT_REQUIRED if cert_reqs is None else cert_reqs
|
||||||
|
|
||||||
|
if options is None:
|
||||||
|
options = 0
|
||||||
|
# SSLv2 is easily broken and is considered harmful and dangerous
|
||||||
|
options |= OP_NO_SSLv2
|
||||||
|
# SSLv3 has several problems and is now dangerous
|
||||||
|
options |= OP_NO_SSLv3
|
||||||
|
# Disable compression to prevent CRIME attacks for OpenSSL 1.0+
|
||||||
|
# (issue #309)
|
||||||
|
options |= OP_NO_COMPRESSION
|
||||||
|
# TLSv1.2 only. Unless set explicitly, do not request tickets.
|
||||||
|
# This may save some bandwidth on wire, and although the ticket is encrypted,
|
||||||
|
# there is a risk associated with it being on wire,
|
||||||
|
# if the server is not rotating its ticketing keys properly.
|
||||||
|
options |= OP_NO_TICKET
|
||||||
|
|
||||||
|
context.options |= options
|
||||||
|
|
||||||
|
if verify_flags is None:
|
||||||
|
verify_flags = 0
|
||||||
|
# In Python 3.13+ ssl.create_default_context() sets VERIFY_X509_PARTIAL_CHAIN
|
||||||
|
# and VERIFY_X509_STRICT so we do the same
|
||||||
|
if sys.version_info >= (3, 13):
|
||||||
|
verify_flags |= VERIFY_X509_PARTIAL_CHAIN
|
||||||
|
verify_flags |= VERIFY_X509_STRICT
|
||||||
|
|
||||||
|
context.verify_flags |= verify_flags
|
||||||
|
|
||||||
|
# Enable post-handshake authentication for TLS 1.3, see GH #1634. PHA is
|
||||||
|
# necessary for conditional client cert authentication with TLS 1.3.
|
||||||
|
# The attribute is None for OpenSSL <= 1.1.0 or does not exist when using
|
||||||
|
# an SSLContext created by pyOpenSSL.
|
||||||
|
if getattr(context, "post_handshake_auth", None) is not None:
|
||||||
|
context.post_handshake_auth = True
|
||||||
|
|
||||||
|
# The order of the below lines setting verify_mode and check_hostname
|
||||||
|
# matter due to safe-guards SSLContext has to prevent an SSLContext with
|
||||||
|
# check_hostname=True, verify_mode=NONE/OPTIONAL.
|
||||||
|
# We always set 'check_hostname=False' for pyOpenSSL so we rely on our own
|
||||||
|
# 'ssl.match_hostname()' implementation.
|
||||||
|
if cert_reqs == ssl.CERT_REQUIRED and not IS_PYOPENSSL:
|
||||||
|
context.verify_mode = cert_reqs
|
||||||
|
context.check_hostname = True
|
||||||
|
else:
|
||||||
|
context.check_hostname = False
|
||||||
|
context.verify_mode = cert_reqs
|
||||||
|
|
||||||
|
try:
|
||||||
|
context.hostname_checks_common_name = False
|
||||||
|
except AttributeError: # Defensive: for CPython < 3.9.3; for PyPy < 7.3.8
|
||||||
|
pass
|
||||||
|
|
||||||
|
sslkeylogfile = os.environ.get("SSLKEYLOGFILE")
|
||||||
|
if sslkeylogfile:
|
||||||
|
context.keylog_filename = sslkeylogfile
|
||||||
|
|
||||||
|
return context
|
||||||
|
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def ssl_wrap_socket(
|
||||||
|
sock: socket.socket,
|
||||||
|
keyfile: str | None = ...,
|
||||||
|
certfile: str | None = ...,
|
||||||
|
cert_reqs: int | None = ...,
|
||||||
|
ca_certs: str | None = ...,
|
||||||
|
server_hostname: str | None = ...,
|
||||||
|
ssl_version: int | None = ...,
|
||||||
|
ciphers: str | None = ...,
|
||||||
|
ssl_context: ssl.SSLContext | None = ...,
|
||||||
|
ca_cert_dir: str | None = ...,
|
||||||
|
key_password: str | None = ...,
|
||||||
|
ca_cert_data: None | str | bytes = ...,
|
||||||
|
tls_in_tls: typing.Literal[False] = ...,
|
||||||
|
) -> ssl.SSLSocket: ...
|
||||||
|
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def ssl_wrap_socket(
|
||||||
|
sock: socket.socket,
|
||||||
|
keyfile: str | None = ...,
|
||||||
|
certfile: str | None = ...,
|
||||||
|
cert_reqs: int | None = ...,
|
||||||
|
ca_certs: str | None = ...,
|
||||||
|
server_hostname: str | None = ...,
|
||||||
|
ssl_version: int | None = ...,
|
||||||
|
ciphers: str | None = ...,
|
||||||
|
ssl_context: ssl.SSLContext | None = ...,
|
||||||
|
ca_cert_dir: str | None = ...,
|
||||||
|
key_password: str | None = ...,
|
||||||
|
ca_cert_data: None | str | bytes = ...,
|
||||||
|
tls_in_tls: bool = ...,
|
||||||
|
) -> ssl.SSLSocket | SSLTransportType: ...
|
||||||
|
|
||||||
|
|
||||||
|
def ssl_wrap_socket(
|
||||||
|
sock: socket.socket,
|
||||||
|
keyfile: str | None = None,
|
||||||
|
certfile: str | None = None,
|
||||||
|
cert_reqs: int | None = None,
|
||||||
|
ca_certs: str | None = None,
|
||||||
|
server_hostname: str | None = None,
|
||||||
|
ssl_version: int | None = None,
|
||||||
|
ciphers: str | None = None,
|
||||||
|
ssl_context: ssl.SSLContext | None = None,
|
||||||
|
ca_cert_dir: str | None = None,
|
||||||
|
key_password: str | None = None,
|
||||||
|
ca_cert_data: None | str | bytes = None,
|
||||||
|
tls_in_tls: bool = False,
|
||||||
|
) -> ssl.SSLSocket | SSLTransportType:
|
||||||
|
"""
|
||||||
|
All arguments except for server_hostname, ssl_context, tls_in_tls, ca_cert_data and
|
||||||
|
ca_cert_dir have the same meaning as they do when using
|
||||||
|
:func:`ssl.create_default_context`, :meth:`ssl.SSLContext.load_cert_chain`,
|
||||||
|
:meth:`ssl.SSLContext.set_ciphers` and :meth:`ssl.SSLContext.wrap_socket`.
|
||||||
|
|
||||||
|
:param server_hostname:
|
||||||
|
When SNI is supported, the expected hostname of the certificate
|
||||||
|
:param ssl_context:
|
||||||
|
A pre-made :class:`SSLContext` object. If none is provided, one will
|
||||||
|
be created using :func:`create_urllib3_context`.
|
||||||
|
:param ciphers:
|
||||||
|
A string of ciphers we wish the client to support.
|
||||||
|
:param ca_cert_dir:
|
||||||
|
A directory containing CA certificates in multiple separate files, as
|
||||||
|
supported by OpenSSL's -CApath flag or the capath argument to
|
||||||
|
SSLContext.load_verify_locations().
|
||||||
|
:param key_password:
|
||||||
|
Optional password if the keyfile is encrypted.
|
||||||
|
:param ca_cert_data:
|
||||||
|
Optional string containing CA certificates in PEM format suitable for
|
||||||
|
passing as the cadata parameter to SSLContext.load_verify_locations()
|
||||||
|
:param tls_in_tls:
|
||||||
|
Use SSLTransport to wrap the existing socket.
|
||||||
|
"""
|
||||||
|
context = ssl_context
|
||||||
|
if context is None:
|
||||||
|
# Note: This branch of code and all the variables in it are only used in tests.
|
||||||
|
# We should consider deprecating and removing this code.
|
||||||
|
context = create_urllib3_context(ssl_version, cert_reqs, ciphers=ciphers)
|
||||||
|
|
||||||
|
if ca_certs or ca_cert_dir or ca_cert_data:
|
||||||
|
try:
|
||||||
|
context.load_verify_locations(ca_certs, ca_cert_dir, ca_cert_data)
|
||||||
|
except OSError as e:
|
||||||
|
raise SSLError(e) from e
|
||||||
|
|
||||||
|
elif ssl_context is None and hasattr(context, "load_default_certs"):
|
||||||
|
# try to load OS default certs; works well on Windows.
|
||||||
|
context.load_default_certs()
|
||||||
|
|
||||||
|
# Attempt to detect if we get the goofy behavior of the
|
||||||
|
# keyfile being encrypted and OpenSSL asking for the
|
||||||
|
# passphrase via the terminal and instead error out.
|
||||||
|
if keyfile and key_password is None and _is_key_file_encrypted(keyfile):
|
||||||
|
raise SSLError("Client private key is encrypted, password is required")
|
||||||
|
|
||||||
|
if certfile:
|
||||||
|
if key_password is None:
|
||||||
|
context.load_cert_chain(certfile, keyfile)
|
||||||
|
else:
|
||||||
|
context.load_cert_chain(certfile, keyfile, key_password)
|
||||||
|
|
||||||
|
context.set_alpn_protocols(ALPN_PROTOCOLS)
|
||||||
|
|
||||||
|
ssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls, server_hostname)
|
||||||
|
return ssl_sock
|
||||||
|
|
||||||
|
|
||||||
|
def is_ipaddress(hostname: str | bytes) -> bool:
|
||||||
|
"""Detects whether the hostname given is an IPv4 or IPv6 address.
|
||||||
|
Also detects IPv6 addresses with Zone IDs.
|
||||||
|
|
||||||
|
:param str hostname: Hostname to examine.
|
||||||
|
:return: True if the hostname is an IP address, False otherwise.
|
||||||
|
"""
|
||||||
|
if isinstance(hostname, bytes):
|
||||||
|
# IDN A-label bytes are ASCII compatible.
|
||||||
|
hostname = hostname.decode("ascii")
|
||||||
|
return bool(_IPV4_RE.match(hostname) or _BRACELESS_IPV6_ADDRZ_RE.match(hostname))
|
||||||
|
|
||||||
|
|
||||||
|
def _is_key_file_encrypted(key_file: str) -> bool:
|
||||||
|
"""Detects if a key file is encrypted or not."""
|
||||||
|
with open(key_file) as f:
|
||||||
|
for line in f:
|
||||||
|
# Look for Proc-Type: 4,ENCRYPTED
|
||||||
|
if "ENCRYPTED" in line:
|
||||||
|
return True
|
||||||
|
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def _ssl_wrap_socket_impl(
|
||||||
|
sock: socket.socket,
|
||||||
|
ssl_context: ssl.SSLContext,
|
||||||
|
tls_in_tls: bool,
|
||||||
|
server_hostname: str | None = None,
|
||||||
|
) -> ssl.SSLSocket | SSLTransportType:
|
||||||
|
if tls_in_tls:
|
||||||
|
if not SSLTransport:
|
||||||
|
# Import error, ssl is not available.
|
||||||
|
raise ProxySchemeUnsupported(
|
||||||
|
"TLS in TLS requires support for the 'ssl' module"
|
||||||
|
)
|
||||||
|
|
||||||
|
SSLTransport._validate_ssl_context_for_tls_in_tls(ssl_context)
|
||||||
|
return SSLTransport(sock, ssl_context, server_hostname)
|
||||||
|
|
||||||
|
return ssl_context.wrap_socket(sock, server_hostname=server_hostname)
|
||||||
@@ -0,0 +1,159 @@
|
|||||||
|
"""The match_hostname() function from Python 3.5, essential when using SSL."""
|
||||||
|
|
||||||
|
# Note: This file is under the PSF license as the code comes from the python
|
||||||
|
# stdlib. http://docs.python.org/3/license.html
|
||||||
|
# It is modified to remove commonName support.
|
||||||
|
|
||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import ipaddress
|
||||||
|
import re
|
||||||
|
import typing
|
||||||
|
from ipaddress import IPv4Address, IPv6Address
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from .ssl_ import _TYPE_PEER_CERT_RET_DICT
|
||||||
|
|
||||||
|
__version__ = "3.5.0.1"
|
||||||
|
|
||||||
|
|
||||||
|
class CertificateError(ValueError):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
def _dnsname_match(
|
||||||
|
dn: typing.Any, hostname: str, max_wildcards: int = 1
|
||||||
|
) -> typing.Match[str] | None | bool:
|
||||||
|
"""Matching according to RFC 6125, section 6.4.3
|
||||||
|
|
||||||
|
http://tools.ietf.org/html/rfc6125#section-6.4.3
|
||||||
|
"""
|
||||||
|
pats = []
|
||||||
|
if not dn:
|
||||||
|
return False
|
||||||
|
|
||||||
|
# Ported from python3-syntax:
|
||||||
|
# leftmost, *remainder = dn.split(r'.')
|
||||||
|
parts = dn.split(r".")
|
||||||
|
leftmost = parts[0]
|
||||||
|
remainder = parts[1:]
|
||||||
|
|
||||||
|
wildcards = leftmost.count("*")
|
||||||
|
if wildcards > max_wildcards:
|
||||||
|
# Issue #17980: avoid denials of service by refusing more
|
||||||
|
# than one wildcard per fragment. A survey of established
|
||||||
|
# policy among SSL implementations showed it to be a
|
||||||
|
# reasonable choice.
|
||||||
|
raise CertificateError(
|
||||||
|
"too many wildcards in certificate DNS name: " + repr(dn)
|
||||||
|
)
|
||||||
|
|
||||||
|
# speed up common case w/o wildcards
|
||||||
|
if not wildcards:
|
||||||
|
return bool(dn.lower() == hostname.lower())
|
||||||
|
|
||||||
|
# RFC 6125, section 6.4.3, subitem 1.
|
||||||
|
# The client SHOULD NOT attempt to match a presented identifier in which
|
||||||
|
# the wildcard character comprises a label other than the left-most label.
|
||||||
|
if leftmost == "*":
|
||||||
|
# When '*' is a fragment by itself, it matches a non-empty dotless
|
||||||
|
# fragment.
|
||||||
|
pats.append("[^.]+")
|
||||||
|
elif leftmost.startswith("xn--") or hostname.startswith("xn--"):
|
||||||
|
# RFC 6125, section 6.4.3, subitem 3.
|
||||||
|
# The client SHOULD NOT attempt to match a presented identifier
|
||||||
|
# where the wildcard character is embedded within an A-label or
|
||||||
|
# U-label of an internationalized domain name.
|
||||||
|
pats.append(re.escape(leftmost))
|
||||||
|
else:
|
||||||
|
# Otherwise, '*' matches any dotless string, e.g. www*
|
||||||
|
pats.append(re.escape(leftmost).replace(r"\*", "[^.]*"))
|
||||||
|
|
||||||
|
# add the remaining fragments, ignore any wildcards
|
||||||
|
for frag in remainder:
|
||||||
|
pats.append(re.escape(frag))
|
||||||
|
|
||||||
|
pat = re.compile(r"\A" + r"\.".join(pats) + r"\Z", re.IGNORECASE)
|
||||||
|
return pat.match(hostname)
|
||||||
|
|
||||||
|
|
||||||
|
def _ipaddress_match(ipname: str, host_ip: IPv4Address | IPv6Address) -> bool:
|
||||||
|
"""Exact matching of IP addresses.
|
||||||
|
|
||||||
|
RFC 9110 section 4.3.5: "A reference identity of IP-ID contains the decoded
|
||||||
|
bytes of the IP address. An IP version 4 address is 4 octets, and an IP
|
||||||
|
version 6 address is 16 octets. [...] A reference identity of type IP-ID
|
||||||
|
matches if the address is identical to an iPAddress value of the
|
||||||
|
subjectAltName extension of the certificate."
|
||||||
|
"""
|
||||||
|
# OpenSSL may add a trailing newline to a subjectAltName's IP address
|
||||||
|
# Divergence from upstream: ipaddress can't handle byte str
|
||||||
|
ip = ipaddress.ip_address(ipname.rstrip())
|
||||||
|
return bool(ip.packed == host_ip.packed)
|
||||||
|
|
||||||
|
|
||||||
|
def match_hostname(
|
||||||
|
cert: _TYPE_PEER_CERT_RET_DICT | None,
|
||||||
|
hostname: str,
|
||||||
|
hostname_checks_common_name: bool = False,
|
||||||
|
) -> None:
|
||||||
|
"""Verify that *cert* (in decoded format as returned by
|
||||||
|
SSLSocket.getpeercert()) matches the *hostname*. RFC 2818 and RFC 6125
|
||||||
|
rules are followed, but IP addresses are not accepted for *hostname*.
|
||||||
|
|
||||||
|
CertificateError is raised on failure. On success, the function
|
||||||
|
returns nothing.
|
||||||
|
"""
|
||||||
|
if not cert:
|
||||||
|
raise ValueError(
|
||||||
|
"empty or no certificate, match_hostname needs a "
|
||||||
|
"SSL socket or SSL context with either "
|
||||||
|
"CERT_OPTIONAL or CERT_REQUIRED"
|
||||||
|
)
|
||||||
|
try:
|
||||||
|
# Divergence from upstream: ipaddress can't handle byte str
|
||||||
|
#
|
||||||
|
# The ipaddress module shipped with Python < 3.9 does not support
|
||||||
|
# scoped IPv6 addresses so we unconditionally strip the Zone IDs for
|
||||||
|
# now. Once we drop support for Python 3.9 we can remove this branch.
|
||||||
|
if "%" in hostname:
|
||||||
|
host_ip = ipaddress.ip_address(hostname[: hostname.rfind("%")])
|
||||||
|
else:
|
||||||
|
host_ip = ipaddress.ip_address(hostname)
|
||||||
|
|
||||||
|
except ValueError:
|
||||||
|
# Not an IP address (common case)
|
||||||
|
host_ip = None
|
||||||
|
dnsnames = []
|
||||||
|
san: tuple[tuple[str, str], ...] = cert.get("subjectAltName", ())
|
||||||
|
key: str
|
||||||
|
value: str
|
||||||
|
for key, value in san:
|
||||||
|
if key == "DNS":
|
||||||
|
if host_ip is None and _dnsname_match(value, hostname):
|
||||||
|
return
|
||||||
|
dnsnames.append(value)
|
||||||
|
elif key == "IP Address":
|
||||||
|
if host_ip is not None and _ipaddress_match(value, host_ip):
|
||||||
|
return
|
||||||
|
dnsnames.append(value)
|
||||||
|
|
||||||
|
# We only check 'commonName' if it's enabled and we're not verifying
|
||||||
|
# an IP address. IP addresses aren't valid within 'commonName'.
|
||||||
|
if hostname_checks_common_name and host_ip is None and not dnsnames:
|
||||||
|
for sub in cert.get("subject", ()):
|
||||||
|
for key, value in sub:
|
||||||
|
if key == "commonName":
|
||||||
|
if _dnsname_match(value, hostname):
|
||||||
|
return
|
||||||
|
dnsnames.append(value) # Defensive: for Python < 3.9.3
|
||||||
|
|
||||||
|
if len(dnsnames) > 1:
|
||||||
|
raise CertificateError(
|
||||||
|
"hostname %r "
|
||||||
|
"doesn't match either of %s" % (hostname, ", ".join(map(repr, dnsnames)))
|
||||||
|
)
|
||||||
|
elif len(dnsnames) == 1:
|
||||||
|
raise CertificateError(f"hostname {hostname!r} doesn't match {dnsnames[0]!r}")
|
||||||
|
else:
|
||||||
|
raise CertificateError("no appropriate subjectAltName fields were found")
|
||||||
271
venv/lib/python3.12/site-packages/urllib3/util/ssltransport.py
Normal file
271
venv/lib/python3.12/site-packages/urllib3/util/ssltransport.py
Normal file
@@ -0,0 +1,271 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import io
|
||||||
|
import socket
|
||||||
|
import ssl
|
||||||
|
import typing
|
||||||
|
|
||||||
|
from ..exceptions import ProxySchemeUnsupported
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from typing_extensions import Self
|
||||||
|
|
||||||
|
from .ssl_ import _TYPE_PEER_CERT_RET, _TYPE_PEER_CERT_RET_DICT
|
||||||
|
|
||||||
|
|
||||||
|
_WriteBuffer = typing.Union[bytearray, memoryview]
|
||||||
|
_ReturnValue = typing.TypeVar("_ReturnValue")
|
||||||
|
|
||||||
|
SSL_BLOCKSIZE = 16384
|
||||||
|
|
||||||
|
|
||||||
|
class SSLTransport:
|
||||||
|
"""
|
||||||
|
The SSLTransport wraps an existing socket and establishes an SSL connection.
|
||||||
|
|
||||||
|
Contrary to Python's implementation of SSLSocket, it allows you to chain
|
||||||
|
multiple TLS connections together. It's particularly useful if you need to
|
||||||
|
implement TLS within TLS.
|
||||||
|
|
||||||
|
The class supports most of the socket API operations.
|
||||||
|
"""
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _validate_ssl_context_for_tls_in_tls(ssl_context: ssl.SSLContext) -> None:
|
||||||
|
"""
|
||||||
|
Raises a ProxySchemeUnsupported if the provided ssl_context can't be used
|
||||||
|
for TLS in TLS.
|
||||||
|
|
||||||
|
The only requirement is that the ssl_context provides the 'wrap_bio'
|
||||||
|
methods.
|
||||||
|
"""
|
||||||
|
|
||||||
|
if not hasattr(ssl_context, "wrap_bio"):
|
||||||
|
raise ProxySchemeUnsupported(
|
||||||
|
"TLS in TLS requires SSLContext.wrap_bio() which isn't "
|
||||||
|
"available on non-native SSLContext"
|
||||||
|
)
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
socket: socket.socket,
|
||||||
|
ssl_context: ssl.SSLContext,
|
||||||
|
server_hostname: str | None = None,
|
||||||
|
suppress_ragged_eofs: bool = True,
|
||||||
|
) -> None:
|
||||||
|
"""
|
||||||
|
Create an SSLTransport around socket using the provided ssl_context.
|
||||||
|
"""
|
||||||
|
self.incoming = ssl.MemoryBIO()
|
||||||
|
self.outgoing = ssl.MemoryBIO()
|
||||||
|
|
||||||
|
self.suppress_ragged_eofs = suppress_ragged_eofs
|
||||||
|
self.socket = socket
|
||||||
|
|
||||||
|
self.sslobj = ssl_context.wrap_bio(
|
||||||
|
self.incoming, self.outgoing, server_hostname=server_hostname
|
||||||
|
)
|
||||||
|
|
||||||
|
# Perform initial handshake.
|
||||||
|
self._ssl_io_loop(self.sslobj.do_handshake)
|
||||||
|
|
||||||
|
def __enter__(self) -> Self:
|
||||||
|
return self
|
||||||
|
|
||||||
|
def __exit__(self, *_: typing.Any) -> None:
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
def fileno(self) -> int:
|
||||||
|
return self.socket.fileno()
|
||||||
|
|
||||||
|
def read(self, len: int = 1024, buffer: typing.Any | None = None) -> int | bytes:
|
||||||
|
return self._wrap_ssl_read(len, buffer)
|
||||||
|
|
||||||
|
def recv(self, buflen: int = 1024, flags: int = 0) -> int | bytes:
|
||||||
|
if flags != 0:
|
||||||
|
raise ValueError("non-zero flags not allowed in calls to recv")
|
||||||
|
return self._wrap_ssl_read(buflen)
|
||||||
|
|
||||||
|
def recv_into(
|
||||||
|
self,
|
||||||
|
buffer: _WriteBuffer,
|
||||||
|
nbytes: int | None = None,
|
||||||
|
flags: int = 0,
|
||||||
|
) -> None | int | bytes:
|
||||||
|
if flags != 0:
|
||||||
|
raise ValueError("non-zero flags not allowed in calls to recv_into")
|
||||||
|
if nbytes is None:
|
||||||
|
nbytes = len(buffer)
|
||||||
|
return self.read(nbytes, buffer)
|
||||||
|
|
||||||
|
def sendall(self, data: bytes, flags: int = 0) -> None:
|
||||||
|
if flags != 0:
|
||||||
|
raise ValueError("non-zero flags not allowed in calls to sendall")
|
||||||
|
count = 0
|
||||||
|
with memoryview(data) as view, view.cast("B") as byte_view:
|
||||||
|
amount = len(byte_view)
|
||||||
|
while count < amount:
|
||||||
|
v = self.send(byte_view[count:])
|
||||||
|
count += v
|
||||||
|
|
||||||
|
def send(self, data: bytes, flags: int = 0) -> int:
|
||||||
|
if flags != 0:
|
||||||
|
raise ValueError("non-zero flags not allowed in calls to send")
|
||||||
|
return self._ssl_io_loop(self.sslobj.write, data)
|
||||||
|
|
||||||
|
def makefile(
|
||||||
|
self,
|
||||||
|
mode: str,
|
||||||
|
buffering: int | None = None,
|
||||||
|
*,
|
||||||
|
encoding: str | None = None,
|
||||||
|
errors: str | None = None,
|
||||||
|
newline: str | None = None,
|
||||||
|
) -> typing.BinaryIO | typing.TextIO | socket.SocketIO:
|
||||||
|
"""
|
||||||
|
Python's httpclient uses makefile and buffered io when reading HTTP
|
||||||
|
messages and we need to support it.
|
||||||
|
|
||||||
|
This is unfortunately a copy and paste of socket.py makefile with small
|
||||||
|
changes to point to the socket directly.
|
||||||
|
"""
|
||||||
|
if not set(mode) <= {"r", "w", "b"}:
|
||||||
|
raise ValueError(f"invalid mode {mode!r} (only r, w, b allowed)")
|
||||||
|
|
||||||
|
writing = "w" in mode
|
||||||
|
reading = "r" in mode or not writing
|
||||||
|
assert reading or writing
|
||||||
|
binary = "b" in mode
|
||||||
|
rawmode = ""
|
||||||
|
if reading:
|
||||||
|
rawmode += "r"
|
||||||
|
if writing:
|
||||||
|
rawmode += "w"
|
||||||
|
raw = socket.SocketIO(self, rawmode) # type: ignore[arg-type]
|
||||||
|
self.socket._io_refs += 1 # type: ignore[attr-defined]
|
||||||
|
if buffering is None:
|
||||||
|
buffering = -1
|
||||||
|
if buffering < 0:
|
||||||
|
buffering = io.DEFAULT_BUFFER_SIZE
|
||||||
|
if buffering == 0:
|
||||||
|
if not binary:
|
||||||
|
raise ValueError("unbuffered streams must be binary")
|
||||||
|
return raw
|
||||||
|
buffer: typing.BinaryIO
|
||||||
|
if reading and writing:
|
||||||
|
buffer = io.BufferedRWPair(raw, raw, buffering) # type: ignore[assignment]
|
||||||
|
elif reading:
|
||||||
|
buffer = io.BufferedReader(raw, buffering)
|
||||||
|
else:
|
||||||
|
assert writing
|
||||||
|
buffer = io.BufferedWriter(raw, buffering)
|
||||||
|
if binary:
|
||||||
|
return buffer
|
||||||
|
text = io.TextIOWrapper(buffer, encoding, errors, newline)
|
||||||
|
text.mode = mode # type: ignore[misc]
|
||||||
|
return text
|
||||||
|
|
||||||
|
def unwrap(self) -> None:
|
||||||
|
self._ssl_io_loop(self.sslobj.unwrap)
|
||||||
|
|
||||||
|
def close(self) -> None:
|
||||||
|
self.socket.close()
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def getpeercert(
|
||||||
|
self, binary_form: typing.Literal[False] = ...
|
||||||
|
) -> _TYPE_PEER_CERT_RET_DICT | None: ...
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def getpeercert(self, binary_form: typing.Literal[True]) -> bytes | None: ...
|
||||||
|
|
||||||
|
def getpeercert(self, binary_form: bool = False) -> _TYPE_PEER_CERT_RET:
|
||||||
|
return self.sslobj.getpeercert(binary_form) # type: ignore[return-value]
|
||||||
|
|
||||||
|
def version(self) -> str | None:
|
||||||
|
return self.sslobj.version()
|
||||||
|
|
||||||
|
def cipher(self) -> tuple[str, str, int] | None:
|
||||||
|
return self.sslobj.cipher()
|
||||||
|
|
||||||
|
def selected_alpn_protocol(self) -> str | None:
|
||||||
|
return self.sslobj.selected_alpn_protocol()
|
||||||
|
|
||||||
|
def shared_ciphers(self) -> list[tuple[str, str, int]] | None:
|
||||||
|
return self.sslobj.shared_ciphers()
|
||||||
|
|
||||||
|
def compression(self) -> str | None:
|
||||||
|
return self.sslobj.compression()
|
||||||
|
|
||||||
|
def settimeout(self, value: float | None) -> None:
|
||||||
|
self.socket.settimeout(value)
|
||||||
|
|
||||||
|
def gettimeout(self) -> float | None:
|
||||||
|
return self.socket.gettimeout()
|
||||||
|
|
||||||
|
def _decref_socketios(self) -> None:
|
||||||
|
self.socket._decref_socketios() # type: ignore[attr-defined]
|
||||||
|
|
||||||
|
def _wrap_ssl_read(self, len: int, buffer: bytearray | None = None) -> int | bytes:
|
||||||
|
try:
|
||||||
|
return self._ssl_io_loop(self.sslobj.read, len, buffer)
|
||||||
|
except ssl.SSLError as e:
|
||||||
|
if e.errno == ssl.SSL_ERROR_EOF and self.suppress_ragged_eofs:
|
||||||
|
return 0 # eof, return 0.
|
||||||
|
else:
|
||||||
|
raise
|
||||||
|
|
||||||
|
# func is sslobj.do_handshake or sslobj.unwrap
|
||||||
|
@typing.overload
|
||||||
|
def _ssl_io_loop(self, func: typing.Callable[[], None]) -> None: ...
|
||||||
|
|
||||||
|
# func is sslobj.write, arg1 is data
|
||||||
|
@typing.overload
|
||||||
|
def _ssl_io_loop(self, func: typing.Callable[[bytes], int], arg1: bytes) -> int: ...
|
||||||
|
|
||||||
|
# func is sslobj.read, arg1 is len, arg2 is buffer
|
||||||
|
@typing.overload
|
||||||
|
def _ssl_io_loop(
|
||||||
|
self,
|
||||||
|
func: typing.Callable[[int, bytearray | None], bytes],
|
||||||
|
arg1: int,
|
||||||
|
arg2: bytearray | None,
|
||||||
|
) -> bytes: ...
|
||||||
|
|
||||||
|
def _ssl_io_loop(
|
||||||
|
self,
|
||||||
|
func: typing.Callable[..., _ReturnValue],
|
||||||
|
arg1: None | bytes | int = None,
|
||||||
|
arg2: bytearray | None = None,
|
||||||
|
) -> _ReturnValue:
|
||||||
|
"""Performs an I/O loop between incoming/outgoing and the socket."""
|
||||||
|
should_loop = True
|
||||||
|
ret = None
|
||||||
|
|
||||||
|
while should_loop:
|
||||||
|
errno = None
|
||||||
|
try:
|
||||||
|
if arg1 is None and arg2 is None:
|
||||||
|
ret = func()
|
||||||
|
elif arg2 is None:
|
||||||
|
ret = func(arg1)
|
||||||
|
else:
|
||||||
|
ret = func(arg1, arg2)
|
||||||
|
except ssl.SSLError as e:
|
||||||
|
if e.errno not in (ssl.SSL_ERROR_WANT_READ, ssl.SSL_ERROR_WANT_WRITE):
|
||||||
|
# WANT_READ, and WANT_WRITE are expected, others are not.
|
||||||
|
raise e
|
||||||
|
errno = e.errno
|
||||||
|
|
||||||
|
buf = self.outgoing.read()
|
||||||
|
self.socket.sendall(buf)
|
||||||
|
|
||||||
|
if errno is None:
|
||||||
|
should_loop = False
|
||||||
|
elif errno == ssl.SSL_ERROR_WANT_READ:
|
||||||
|
buf = self.socket.recv(SSL_BLOCKSIZE)
|
||||||
|
if buf:
|
||||||
|
self.incoming.write(buf)
|
||||||
|
else:
|
||||||
|
self.incoming.write_eof()
|
||||||
|
return typing.cast(_ReturnValue, ret)
|
||||||
275
venv/lib/python3.12/site-packages/urllib3/util/timeout.py
Normal file
275
venv/lib/python3.12/site-packages/urllib3/util/timeout.py
Normal file
@@ -0,0 +1,275 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import time
|
||||||
|
import typing
|
||||||
|
from enum import Enum
|
||||||
|
from socket import getdefaulttimeout
|
||||||
|
|
||||||
|
from ..exceptions import TimeoutStateError
|
||||||
|
|
||||||
|
if typing.TYPE_CHECKING:
|
||||||
|
from typing import Final
|
||||||
|
|
||||||
|
|
||||||
|
class _TYPE_DEFAULT(Enum):
|
||||||
|
# This value should never be passed to socket.settimeout() so for safety we use a -1.
|
||||||
|
# socket.settimout() raises a ValueError for negative values.
|
||||||
|
token = -1
|
||||||
|
|
||||||
|
|
||||||
|
_DEFAULT_TIMEOUT: Final[_TYPE_DEFAULT] = _TYPE_DEFAULT.token
|
||||||
|
|
||||||
|
_TYPE_TIMEOUT = typing.Optional[typing.Union[float, _TYPE_DEFAULT]]
|
||||||
|
|
||||||
|
|
||||||
|
class Timeout:
|
||||||
|
"""Timeout configuration.
|
||||||
|
|
||||||
|
Timeouts can be defined as a default for a pool:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
timeout = urllib3.util.Timeout(connect=2.0, read=7.0)
|
||||||
|
|
||||||
|
http = urllib3.PoolManager(timeout=timeout)
|
||||||
|
|
||||||
|
resp = http.request("GET", "https://example.com/")
|
||||||
|
|
||||||
|
print(resp.status)
|
||||||
|
|
||||||
|
Or per-request (which overrides the default for the pool):
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
response = http.request("GET", "https://example.com/", timeout=Timeout(10))
|
||||||
|
|
||||||
|
Timeouts can be disabled by setting all the parameters to ``None``:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
no_timeout = Timeout(connect=None, read=None)
|
||||||
|
response = http.request("GET", "https://example.com/", timeout=no_timeout)
|
||||||
|
|
||||||
|
|
||||||
|
:param total:
|
||||||
|
This combines the connect and read timeouts into one; the read timeout
|
||||||
|
will be set to the time leftover from the connect attempt. In the
|
||||||
|
event that both a connect timeout and a total are specified, or a read
|
||||||
|
timeout and a total are specified, the shorter timeout will be applied.
|
||||||
|
|
||||||
|
Defaults to None.
|
||||||
|
|
||||||
|
:type total: int, float, or None
|
||||||
|
|
||||||
|
:param connect:
|
||||||
|
The maximum amount of time (in seconds) to wait for a connection
|
||||||
|
attempt to a server to succeed. Omitting the parameter will default the
|
||||||
|
connect timeout to the system default, probably `the global default
|
||||||
|
timeout in socket.py
|
||||||
|
<http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.
|
||||||
|
None will set an infinite timeout for connection attempts.
|
||||||
|
|
||||||
|
:type connect: int, float, or None
|
||||||
|
|
||||||
|
:param read:
|
||||||
|
The maximum amount of time (in seconds) to wait between consecutive
|
||||||
|
read operations for a response from the server. Omitting the parameter
|
||||||
|
will default the read timeout to the system default, probably `the
|
||||||
|
global default timeout in socket.py
|
||||||
|
<http://hg.python.org/cpython/file/603b4d593758/Lib/socket.py#l535>`_.
|
||||||
|
None will set an infinite timeout.
|
||||||
|
|
||||||
|
:type read: int, float, or None
|
||||||
|
|
||||||
|
.. note::
|
||||||
|
|
||||||
|
Many factors can affect the total amount of time for urllib3 to return
|
||||||
|
an HTTP response.
|
||||||
|
|
||||||
|
For example, Python's DNS resolver does not obey the timeout specified
|
||||||
|
on the socket. Other factors that can affect total request time include
|
||||||
|
high CPU load, high swap, the program running at a low priority level,
|
||||||
|
or other behaviors.
|
||||||
|
|
||||||
|
In addition, the read and total timeouts only measure the time between
|
||||||
|
read operations on the socket connecting the client and the server,
|
||||||
|
not the total amount of time for the request to return a complete
|
||||||
|
response. For most requests, the timeout is raised because the server
|
||||||
|
has not sent the first byte in the specified time. This is not always
|
||||||
|
the case; if a server streams one byte every fifteen seconds, a timeout
|
||||||
|
of 20 seconds will not trigger, even though the request will take
|
||||||
|
several minutes to complete.
|
||||||
|
"""
|
||||||
|
|
||||||
|
#: A sentinel object representing the default timeout value
|
||||||
|
DEFAULT_TIMEOUT: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
total: _TYPE_TIMEOUT = None,
|
||||||
|
connect: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
read: _TYPE_TIMEOUT = _DEFAULT_TIMEOUT,
|
||||||
|
) -> None:
|
||||||
|
self._connect = self._validate_timeout(connect, "connect")
|
||||||
|
self._read = self._validate_timeout(read, "read")
|
||||||
|
self.total = self._validate_timeout(total, "total")
|
||||||
|
self._start_connect: float | None = None
|
||||||
|
|
||||||
|
def __repr__(self) -> str:
|
||||||
|
return f"{type(self).__name__}(connect={self._connect!r}, read={self._read!r}, total={self.total!r})"
|
||||||
|
|
||||||
|
# __str__ provided for backwards compatibility
|
||||||
|
__str__ = __repr__
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def resolve_default_timeout(timeout: _TYPE_TIMEOUT) -> float | None:
|
||||||
|
return getdefaulttimeout() if timeout is _DEFAULT_TIMEOUT else timeout
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def _validate_timeout(cls, value: _TYPE_TIMEOUT, name: str) -> _TYPE_TIMEOUT:
|
||||||
|
"""Check that a timeout attribute is valid.
|
||||||
|
|
||||||
|
:param value: The timeout value to validate
|
||||||
|
:param name: The name of the timeout attribute to validate. This is
|
||||||
|
used to specify in error messages.
|
||||||
|
:return: The validated and casted version of the given value.
|
||||||
|
:raises ValueError: If it is a numeric value less than or equal to
|
||||||
|
zero, or the type is not an integer, float, or None.
|
||||||
|
"""
|
||||||
|
if value is None or value is _DEFAULT_TIMEOUT:
|
||||||
|
return value
|
||||||
|
|
||||||
|
if isinstance(value, bool):
|
||||||
|
raise ValueError(
|
||||||
|
"Timeout cannot be a boolean value. It must "
|
||||||
|
"be an int, float or None."
|
||||||
|
)
|
||||||
|
try:
|
||||||
|
float(value)
|
||||||
|
except (TypeError, ValueError):
|
||||||
|
raise ValueError(
|
||||||
|
"Timeout value %s was %s, but it must be an "
|
||||||
|
"int, float or None." % (name, value)
|
||||||
|
) from None
|
||||||
|
|
||||||
|
try:
|
||||||
|
if value <= 0:
|
||||||
|
raise ValueError(
|
||||||
|
"Attempted to set %s timeout to %s, but the "
|
||||||
|
"timeout cannot be set to a value less "
|
||||||
|
"than or equal to 0." % (name, value)
|
||||||
|
)
|
||||||
|
except TypeError:
|
||||||
|
raise ValueError(
|
||||||
|
"Timeout value %s was %s, but it must be an "
|
||||||
|
"int, float or None." % (name, value)
|
||||||
|
) from None
|
||||||
|
|
||||||
|
return value
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def from_float(cls, timeout: _TYPE_TIMEOUT) -> Timeout:
|
||||||
|
"""Create a new Timeout from a legacy timeout value.
|
||||||
|
|
||||||
|
The timeout value used by httplib.py sets the same timeout on the
|
||||||
|
connect(), and recv() socket requests. This creates a :class:`Timeout`
|
||||||
|
object that sets the individual timeouts to the ``timeout`` value
|
||||||
|
passed to this function.
|
||||||
|
|
||||||
|
:param timeout: The legacy timeout value.
|
||||||
|
:type timeout: integer, float, :attr:`urllib3.util.Timeout.DEFAULT_TIMEOUT`, or None
|
||||||
|
:return: Timeout object
|
||||||
|
:rtype: :class:`Timeout`
|
||||||
|
"""
|
||||||
|
return Timeout(read=timeout, connect=timeout)
|
||||||
|
|
||||||
|
def clone(self) -> Timeout:
|
||||||
|
"""Create a copy of the timeout object
|
||||||
|
|
||||||
|
Timeout properties are stored per-pool but each request needs a fresh
|
||||||
|
Timeout object to ensure each one has its own start/stop configured.
|
||||||
|
|
||||||
|
:return: a copy of the timeout object
|
||||||
|
:rtype: :class:`Timeout`
|
||||||
|
"""
|
||||||
|
# We can't use copy.deepcopy because that will also create a new object
|
||||||
|
# for _GLOBAL_DEFAULT_TIMEOUT, which socket.py uses as a sentinel to
|
||||||
|
# detect the user default.
|
||||||
|
return Timeout(connect=self._connect, read=self._read, total=self.total)
|
||||||
|
|
||||||
|
def start_connect(self) -> float:
|
||||||
|
"""Start the timeout clock, used during a connect() attempt
|
||||||
|
|
||||||
|
:raises urllib3.exceptions.TimeoutStateError: if you attempt
|
||||||
|
to start a timer that has been started already.
|
||||||
|
"""
|
||||||
|
if self._start_connect is not None:
|
||||||
|
raise TimeoutStateError("Timeout timer has already been started.")
|
||||||
|
self._start_connect = time.monotonic()
|
||||||
|
return self._start_connect
|
||||||
|
|
||||||
|
def get_connect_duration(self) -> float:
|
||||||
|
"""Gets the time elapsed since the call to :meth:`start_connect`.
|
||||||
|
|
||||||
|
:return: Elapsed time in seconds.
|
||||||
|
:rtype: float
|
||||||
|
:raises urllib3.exceptions.TimeoutStateError: if you attempt
|
||||||
|
to get duration for a timer that hasn't been started.
|
||||||
|
"""
|
||||||
|
if self._start_connect is None:
|
||||||
|
raise TimeoutStateError(
|
||||||
|
"Can't get connect duration for timer that has not started."
|
||||||
|
)
|
||||||
|
return time.monotonic() - self._start_connect
|
||||||
|
|
||||||
|
@property
|
||||||
|
def connect_timeout(self) -> _TYPE_TIMEOUT:
|
||||||
|
"""Get the value to use when setting a connection timeout.
|
||||||
|
|
||||||
|
This will be a positive float or integer, the value None
|
||||||
|
(never timeout), or the default system timeout.
|
||||||
|
|
||||||
|
:return: Connect timeout.
|
||||||
|
:rtype: int, float, :attr:`Timeout.DEFAULT_TIMEOUT` or None
|
||||||
|
"""
|
||||||
|
if self.total is None:
|
||||||
|
return self._connect
|
||||||
|
|
||||||
|
if self._connect is None or self._connect is _DEFAULT_TIMEOUT:
|
||||||
|
return self.total
|
||||||
|
|
||||||
|
return min(self._connect, self.total) # type: ignore[type-var]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def read_timeout(self) -> float | None:
|
||||||
|
"""Get the value for the read timeout.
|
||||||
|
|
||||||
|
This assumes some time has elapsed in the connection timeout and
|
||||||
|
computes the read timeout appropriately.
|
||||||
|
|
||||||
|
If self.total is set, the read timeout is dependent on the amount of
|
||||||
|
time taken by the connect timeout. If the connection time has not been
|
||||||
|
established, a :exc:`~urllib3.exceptions.TimeoutStateError` will be
|
||||||
|
raised.
|
||||||
|
|
||||||
|
:return: Value to use for the read timeout.
|
||||||
|
:rtype: int, float or None
|
||||||
|
:raises urllib3.exceptions.TimeoutStateError: If :meth:`start_connect`
|
||||||
|
has not yet been called on this object.
|
||||||
|
"""
|
||||||
|
if (
|
||||||
|
self.total is not None
|
||||||
|
and self.total is not _DEFAULT_TIMEOUT
|
||||||
|
and self._read is not None
|
||||||
|
and self._read is not _DEFAULT_TIMEOUT
|
||||||
|
):
|
||||||
|
# In case the connect timeout has not yet been established.
|
||||||
|
if self._start_connect is None:
|
||||||
|
return self._read
|
||||||
|
return max(0, min(self.total - self.get_connect_duration(), self._read))
|
||||||
|
elif self.total is not None and self.total is not _DEFAULT_TIMEOUT:
|
||||||
|
return max(0, self.total - self.get_connect_duration())
|
||||||
|
else:
|
||||||
|
return self.resolve_default_timeout(self._read)
|
||||||
469
venv/lib/python3.12/site-packages/urllib3/util/url.py
Normal file
469
venv/lib/python3.12/site-packages/urllib3/util/url.py
Normal file
@@ -0,0 +1,469 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import re
|
||||||
|
import typing
|
||||||
|
|
||||||
|
from ..exceptions import LocationParseError
|
||||||
|
from .util import to_str
|
||||||
|
|
||||||
|
# We only want to normalize urls with an HTTP(S) scheme.
|
||||||
|
# urllib3 infers URLs without a scheme (None) to be http.
|
||||||
|
_NORMALIZABLE_SCHEMES = ("http", "https", None)
|
||||||
|
|
||||||
|
# Almost all of these patterns were derived from the
|
||||||
|
# 'rfc3986' module: https://github.com/python-hyper/rfc3986
|
||||||
|
_PERCENT_RE = re.compile(r"%[a-fA-F0-9]{2}")
|
||||||
|
_SCHEME_RE = re.compile(r"^(?:[a-zA-Z][a-zA-Z0-9+-]*:|/)")
|
||||||
|
_URI_RE = re.compile(
|
||||||
|
r"^(?:([a-zA-Z][a-zA-Z0-9+.-]*):)?"
|
||||||
|
r"(?://([^\\/?#]*))?"
|
||||||
|
r"([^?#]*)"
|
||||||
|
r"(?:\?([^#]*))?"
|
||||||
|
r"(?:#(.*))?$",
|
||||||
|
re.UNICODE | re.DOTALL,
|
||||||
|
)
|
||||||
|
|
||||||
|
_IPV4_PAT = r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}"
|
||||||
|
_HEX_PAT = "[0-9A-Fa-f]{1,4}"
|
||||||
|
_LS32_PAT = "(?:{hex}:{hex}|{ipv4})".format(hex=_HEX_PAT, ipv4=_IPV4_PAT)
|
||||||
|
_subs = {"hex": _HEX_PAT, "ls32": _LS32_PAT}
|
||||||
|
_variations = [
|
||||||
|
# 6( h16 ":" ) ls32
|
||||||
|
"(?:%(hex)s:){6}%(ls32)s",
|
||||||
|
# "::" 5( h16 ":" ) ls32
|
||||||
|
"::(?:%(hex)s:){5}%(ls32)s",
|
||||||
|
# [ h16 ] "::" 4( h16 ":" ) ls32
|
||||||
|
"(?:%(hex)s)?::(?:%(hex)s:){4}%(ls32)s",
|
||||||
|
# [ *1( h16 ":" ) h16 ] "::" 3( h16 ":" ) ls32
|
||||||
|
"(?:(?:%(hex)s:)?%(hex)s)?::(?:%(hex)s:){3}%(ls32)s",
|
||||||
|
# [ *2( h16 ":" ) h16 ] "::" 2( h16 ":" ) ls32
|
||||||
|
"(?:(?:%(hex)s:){0,2}%(hex)s)?::(?:%(hex)s:){2}%(ls32)s",
|
||||||
|
# [ *3( h16 ":" ) h16 ] "::" h16 ":" ls32
|
||||||
|
"(?:(?:%(hex)s:){0,3}%(hex)s)?::%(hex)s:%(ls32)s",
|
||||||
|
# [ *4( h16 ":" ) h16 ] "::" ls32
|
||||||
|
"(?:(?:%(hex)s:){0,4}%(hex)s)?::%(ls32)s",
|
||||||
|
# [ *5( h16 ":" ) h16 ] "::" h16
|
||||||
|
"(?:(?:%(hex)s:){0,5}%(hex)s)?::%(hex)s",
|
||||||
|
# [ *6( h16 ":" ) h16 ] "::"
|
||||||
|
"(?:(?:%(hex)s:){0,6}%(hex)s)?::",
|
||||||
|
]
|
||||||
|
|
||||||
|
_UNRESERVED_PAT = r"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789._\-~"
|
||||||
|
_IPV6_PAT = "(?:" + "|".join([x % _subs for x in _variations]) + ")"
|
||||||
|
_ZONE_ID_PAT = "(?:%25|%)(?:[" + _UNRESERVED_PAT + "]|%[a-fA-F0-9]{2})+"
|
||||||
|
_IPV6_ADDRZ_PAT = r"\[" + _IPV6_PAT + r"(?:" + _ZONE_ID_PAT + r")?\]"
|
||||||
|
_REG_NAME_PAT = r"(?:[^\[\]%:/?#]|%[a-fA-F0-9]{2})*"
|
||||||
|
_TARGET_RE = re.compile(r"^(/[^?#]*)(?:\?([^#]*))?(?:#.*)?$")
|
||||||
|
|
||||||
|
_IPV4_RE = re.compile("^" + _IPV4_PAT + "$")
|
||||||
|
_IPV6_RE = re.compile("^" + _IPV6_PAT + "$")
|
||||||
|
_IPV6_ADDRZ_RE = re.compile("^" + _IPV6_ADDRZ_PAT + "$")
|
||||||
|
_BRACELESS_IPV6_ADDRZ_RE = re.compile("^" + _IPV6_ADDRZ_PAT[2:-2] + "$")
|
||||||
|
_ZONE_ID_RE = re.compile("(" + _ZONE_ID_PAT + r")\]$")
|
||||||
|
|
||||||
|
_HOST_PORT_PAT = ("^(%s|%s|%s)(?::0*?(|0|[1-9][0-9]{0,4}))?$") % (
|
||||||
|
_REG_NAME_PAT,
|
||||||
|
_IPV4_PAT,
|
||||||
|
_IPV6_ADDRZ_PAT,
|
||||||
|
)
|
||||||
|
_HOST_PORT_RE = re.compile(_HOST_PORT_PAT, re.UNICODE | re.DOTALL)
|
||||||
|
|
||||||
|
_UNRESERVED_CHARS = set(
|
||||||
|
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789._-~"
|
||||||
|
)
|
||||||
|
_SUB_DELIM_CHARS = set("!$&'()*+,;=")
|
||||||
|
_USERINFO_CHARS = _UNRESERVED_CHARS | _SUB_DELIM_CHARS | {":"}
|
||||||
|
_PATH_CHARS = _USERINFO_CHARS | {"@", "/"}
|
||||||
|
_QUERY_CHARS = _FRAGMENT_CHARS = _PATH_CHARS | {"?"}
|
||||||
|
|
||||||
|
|
||||||
|
class Url(
|
||||||
|
typing.NamedTuple(
|
||||||
|
"Url",
|
||||||
|
[
|
||||||
|
("scheme", typing.Optional[str]),
|
||||||
|
("auth", typing.Optional[str]),
|
||||||
|
("host", typing.Optional[str]),
|
||||||
|
("port", typing.Optional[int]),
|
||||||
|
("path", typing.Optional[str]),
|
||||||
|
("query", typing.Optional[str]),
|
||||||
|
("fragment", typing.Optional[str]),
|
||||||
|
],
|
||||||
|
)
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Data structure for representing an HTTP URL. Used as a return value for
|
||||||
|
:func:`parse_url`. Both the scheme and host are normalized as they are
|
||||||
|
both case-insensitive according to RFC 3986.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __new__( # type: ignore[no-untyped-def]
|
||||||
|
cls,
|
||||||
|
scheme: str | None = None,
|
||||||
|
auth: str | None = None,
|
||||||
|
host: str | None = None,
|
||||||
|
port: int | None = None,
|
||||||
|
path: str | None = None,
|
||||||
|
query: str | None = None,
|
||||||
|
fragment: str | None = None,
|
||||||
|
):
|
||||||
|
if path and not path.startswith("/"):
|
||||||
|
path = "/" + path
|
||||||
|
if scheme is not None:
|
||||||
|
scheme = scheme.lower()
|
||||||
|
return super().__new__(cls, scheme, auth, host, port, path, query, fragment)
|
||||||
|
|
||||||
|
@property
|
||||||
|
def hostname(self) -> str | None:
|
||||||
|
"""For backwards-compatibility with urlparse. We're nice like that."""
|
||||||
|
return self.host
|
||||||
|
|
||||||
|
@property
|
||||||
|
def request_uri(self) -> str:
|
||||||
|
"""Absolute path including the query string."""
|
||||||
|
uri = self.path or "/"
|
||||||
|
|
||||||
|
if self.query is not None:
|
||||||
|
uri += "?" + self.query
|
||||||
|
|
||||||
|
return uri
|
||||||
|
|
||||||
|
@property
|
||||||
|
def authority(self) -> str | None:
|
||||||
|
"""
|
||||||
|
Authority component as defined in RFC 3986 3.2.
|
||||||
|
This includes userinfo (auth), host and port.
|
||||||
|
|
||||||
|
i.e.
|
||||||
|
userinfo@host:port
|
||||||
|
"""
|
||||||
|
userinfo = self.auth
|
||||||
|
netloc = self.netloc
|
||||||
|
if netloc is None or userinfo is None:
|
||||||
|
return netloc
|
||||||
|
else:
|
||||||
|
return f"{userinfo}@{netloc}"
|
||||||
|
|
||||||
|
@property
|
||||||
|
def netloc(self) -> str | None:
|
||||||
|
"""
|
||||||
|
Network location including host and port.
|
||||||
|
|
||||||
|
If you need the equivalent of urllib.parse's ``netloc``,
|
||||||
|
use the ``authority`` property instead.
|
||||||
|
"""
|
||||||
|
if self.host is None:
|
||||||
|
return None
|
||||||
|
if self.port:
|
||||||
|
return f"{self.host}:{self.port}"
|
||||||
|
return self.host
|
||||||
|
|
||||||
|
@property
|
||||||
|
def url(self) -> str:
|
||||||
|
"""
|
||||||
|
Convert self into a url
|
||||||
|
|
||||||
|
This function should more or less round-trip with :func:`.parse_url`. The
|
||||||
|
returned url may not be exactly the same as the url inputted to
|
||||||
|
:func:`.parse_url`, but it should be equivalent by the RFC (e.g., urls
|
||||||
|
with a blank port will have : removed).
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
U = urllib3.util.parse_url("https://google.com/mail/")
|
||||||
|
|
||||||
|
print(U.url)
|
||||||
|
# "https://google.com/mail/"
|
||||||
|
|
||||||
|
print( urllib3.util.Url("https", "username:password",
|
||||||
|
"host.com", 80, "/path", "query", "fragment"
|
||||||
|
).url
|
||||||
|
)
|
||||||
|
# "https://username:password@host.com:80/path?query#fragment"
|
||||||
|
"""
|
||||||
|
scheme, auth, host, port, path, query, fragment = self
|
||||||
|
url = ""
|
||||||
|
|
||||||
|
# We use "is not None" we want things to happen with empty strings (or 0 port)
|
||||||
|
if scheme is not None:
|
||||||
|
url += scheme + "://"
|
||||||
|
if auth is not None:
|
||||||
|
url += auth + "@"
|
||||||
|
if host is not None:
|
||||||
|
url += host
|
||||||
|
if port is not None:
|
||||||
|
url += ":" + str(port)
|
||||||
|
if path is not None:
|
||||||
|
url += path
|
||||||
|
if query is not None:
|
||||||
|
url += "?" + query
|
||||||
|
if fragment is not None:
|
||||||
|
url += "#" + fragment
|
||||||
|
|
||||||
|
return url
|
||||||
|
|
||||||
|
def __str__(self) -> str:
|
||||||
|
return self.url
|
||||||
|
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def _encode_invalid_chars(
|
||||||
|
component: str, allowed_chars: typing.Container[str]
|
||||||
|
) -> str: # Abstract
|
||||||
|
...
|
||||||
|
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def _encode_invalid_chars(
|
||||||
|
component: None, allowed_chars: typing.Container[str]
|
||||||
|
) -> None: # Abstract
|
||||||
|
...
|
||||||
|
|
||||||
|
|
||||||
|
def _encode_invalid_chars(
|
||||||
|
component: str | None, allowed_chars: typing.Container[str]
|
||||||
|
) -> str | None:
|
||||||
|
"""Percent-encodes a URI component without reapplying
|
||||||
|
onto an already percent-encoded component.
|
||||||
|
"""
|
||||||
|
if component is None:
|
||||||
|
return component
|
||||||
|
|
||||||
|
component = to_str(component)
|
||||||
|
|
||||||
|
# Normalize existing percent-encoded bytes.
|
||||||
|
# Try to see if the component we're encoding is already percent-encoded
|
||||||
|
# so we can skip all '%' characters but still encode all others.
|
||||||
|
component, percent_encodings = _PERCENT_RE.subn(
|
||||||
|
lambda match: match.group(0).upper(), component
|
||||||
|
)
|
||||||
|
|
||||||
|
uri_bytes = component.encode("utf-8", "surrogatepass")
|
||||||
|
is_percent_encoded = percent_encodings == uri_bytes.count(b"%")
|
||||||
|
encoded_component = bytearray()
|
||||||
|
|
||||||
|
for i in range(0, len(uri_bytes)):
|
||||||
|
# Will return a single character bytestring
|
||||||
|
byte = uri_bytes[i : i + 1]
|
||||||
|
byte_ord = ord(byte)
|
||||||
|
if (is_percent_encoded and byte == b"%") or (
|
||||||
|
byte_ord < 128 and byte.decode() in allowed_chars
|
||||||
|
):
|
||||||
|
encoded_component += byte
|
||||||
|
continue
|
||||||
|
encoded_component.extend(b"%" + (hex(byte_ord)[2:].encode().zfill(2).upper()))
|
||||||
|
|
||||||
|
return encoded_component.decode()
|
||||||
|
|
||||||
|
|
||||||
|
def _remove_path_dot_segments(path: str) -> str:
|
||||||
|
# See http://tools.ietf.org/html/rfc3986#section-5.2.4 for pseudo-code
|
||||||
|
segments = path.split("/") # Turn the path into a list of segments
|
||||||
|
output = [] # Initialize the variable to use to store output
|
||||||
|
|
||||||
|
for segment in segments:
|
||||||
|
# '.' is the current directory, so ignore it, it is superfluous
|
||||||
|
if segment == ".":
|
||||||
|
continue
|
||||||
|
# Anything other than '..', should be appended to the output
|
||||||
|
if segment != "..":
|
||||||
|
output.append(segment)
|
||||||
|
# In this case segment == '..', if we can, we should pop the last
|
||||||
|
# element
|
||||||
|
elif output:
|
||||||
|
output.pop()
|
||||||
|
|
||||||
|
# If the path starts with '/' and the output is empty or the first string
|
||||||
|
# is non-empty
|
||||||
|
if path.startswith("/") and (not output or output[0]):
|
||||||
|
output.insert(0, "")
|
||||||
|
|
||||||
|
# If the path starts with '/.' or '/..' ensure we add one more empty
|
||||||
|
# string to add a trailing '/'
|
||||||
|
if path.endswith(("/.", "/..")):
|
||||||
|
output.append("")
|
||||||
|
|
||||||
|
return "/".join(output)
|
||||||
|
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def _normalize_host(host: None, scheme: str | None) -> None: ...
|
||||||
|
|
||||||
|
|
||||||
|
@typing.overload
|
||||||
|
def _normalize_host(host: str, scheme: str | None) -> str: ...
|
||||||
|
|
||||||
|
|
||||||
|
def _normalize_host(host: str | None, scheme: str | None) -> str | None:
|
||||||
|
if host:
|
||||||
|
if scheme in _NORMALIZABLE_SCHEMES:
|
||||||
|
is_ipv6 = _IPV6_ADDRZ_RE.match(host)
|
||||||
|
if is_ipv6:
|
||||||
|
# IPv6 hosts of the form 'a::b%zone' are encoded in a URL as
|
||||||
|
# such per RFC 6874: 'a::b%25zone'. Unquote the ZoneID
|
||||||
|
# separator as necessary to return a valid RFC 4007 scoped IP.
|
||||||
|
match = _ZONE_ID_RE.search(host)
|
||||||
|
if match:
|
||||||
|
start, end = match.span(1)
|
||||||
|
zone_id = host[start:end]
|
||||||
|
|
||||||
|
if zone_id.startswith("%25") and zone_id != "%25":
|
||||||
|
zone_id = zone_id[3:]
|
||||||
|
else:
|
||||||
|
zone_id = zone_id[1:]
|
||||||
|
zone_id = _encode_invalid_chars(zone_id, _UNRESERVED_CHARS)
|
||||||
|
return f"{host[:start].lower()}%{zone_id}{host[end:]}"
|
||||||
|
else:
|
||||||
|
return host.lower()
|
||||||
|
elif not _IPV4_RE.match(host):
|
||||||
|
return to_str(
|
||||||
|
b".".join([_idna_encode(label) for label in host.split(".")]),
|
||||||
|
"ascii",
|
||||||
|
)
|
||||||
|
return host
|
||||||
|
|
||||||
|
|
||||||
|
def _idna_encode(name: str) -> bytes:
|
||||||
|
if not name.isascii():
|
||||||
|
try:
|
||||||
|
import idna
|
||||||
|
except ImportError:
|
||||||
|
raise LocationParseError(
|
||||||
|
"Unable to parse URL without the 'idna' module"
|
||||||
|
) from None
|
||||||
|
|
||||||
|
try:
|
||||||
|
return idna.encode(name.lower(), strict=True, std3_rules=True)
|
||||||
|
except idna.IDNAError:
|
||||||
|
raise LocationParseError(
|
||||||
|
f"Name '{name}' is not a valid IDNA label"
|
||||||
|
) from None
|
||||||
|
|
||||||
|
return name.lower().encode("ascii")
|
||||||
|
|
||||||
|
|
||||||
|
def _encode_target(target: str) -> str:
|
||||||
|
"""Percent-encodes a request target so that there are no invalid characters
|
||||||
|
|
||||||
|
Pre-condition for this function is that 'target' must start with '/'.
|
||||||
|
If that is the case then _TARGET_RE will always produce a match.
|
||||||
|
"""
|
||||||
|
match = _TARGET_RE.match(target)
|
||||||
|
if not match: # Defensive:
|
||||||
|
raise LocationParseError(f"{target!r} is not a valid request URI")
|
||||||
|
|
||||||
|
path, query = match.groups()
|
||||||
|
encoded_target = _encode_invalid_chars(path, _PATH_CHARS)
|
||||||
|
if query is not None:
|
||||||
|
query = _encode_invalid_chars(query, _QUERY_CHARS)
|
||||||
|
encoded_target += "?" + query
|
||||||
|
return encoded_target
|
||||||
|
|
||||||
|
|
||||||
|
def parse_url(url: str) -> Url:
|
||||||
|
"""
|
||||||
|
Given a url, return a parsed :class:`.Url` namedtuple. Best-effort is
|
||||||
|
performed to parse incomplete urls. Fields not provided will be None.
|
||||||
|
This parser is RFC 3986 and RFC 6874 compliant.
|
||||||
|
|
||||||
|
The parser logic and helper functions are based heavily on
|
||||||
|
work done in the ``rfc3986`` module.
|
||||||
|
|
||||||
|
:param str url: URL to parse into a :class:`.Url` namedtuple.
|
||||||
|
|
||||||
|
Partly backwards-compatible with :mod:`urllib.parse`.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
.. code-block:: python
|
||||||
|
|
||||||
|
import urllib3
|
||||||
|
|
||||||
|
print( urllib3.util.parse_url('http://google.com/mail/'))
|
||||||
|
# Url(scheme='http', host='google.com', port=None, path='/mail/', ...)
|
||||||
|
|
||||||
|
print( urllib3.util.parse_url('google.com:80'))
|
||||||
|
# Url(scheme=None, host='google.com', port=80, path=None, ...)
|
||||||
|
|
||||||
|
print( urllib3.util.parse_url('/foo?bar'))
|
||||||
|
# Url(scheme=None, host=None, port=None, path='/foo', query='bar', ...)
|
||||||
|
"""
|
||||||
|
if not url:
|
||||||
|
# Empty
|
||||||
|
return Url()
|
||||||
|
|
||||||
|
source_url = url
|
||||||
|
if not _SCHEME_RE.search(url):
|
||||||
|
url = "//" + url
|
||||||
|
|
||||||
|
scheme: str | None
|
||||||
|
authority: str | None
|
||||||
|
auth: str | None
|
||||||
|
host: str | None
|
||||||
|
port: str | None
|
||||||
|
port_int: int | None
|
||||||
|
path: str | None
|
||||||
|
query: str | None
|
||||||
|
fragment: str | None
|
||||||
|
|
||||||
|
try:
|
||||||
|
scheme, authority, path, query, fragment = _URI_RE.match(url).groups() # type: ignore[union-attr]
|
||||||
|
normalize_uri = scheme is None or scheme.lower() in _NORMALIZABLE_SCHEMES
|
||||||
|
|
||||||
|
if scheme:
|
||||||
|
scheme = scheme.lower()
|
||||||
|
|
||||||
|
if authority:
|
||||||
|
auth, _, host_port = authority.rpartition("@")
|
||||||
|
auth = auth or None
|
||||||
|
host, port = _HOST_PORT_RE.match(host_port).groups() # type: ignore[union-attr]
|
||||||
|
if auth and normalize_uri:
|
||||||
|
auth = _encode_invalid_chars(auth, _USERINFO_CHARS)
|
||||||
|
if port == "":
|
||||||
|
port = None
|
||||||
|
else:
|
||||||
|
auth, host, port = None, None, None
|
||||||
|
|
||||||
|
if port is not None:
|
||||||
|
port_int = int(port)
|
||||||
|
if not (0 <= port_int <= 65535):
|
||||||
|
raise LocationParseError(url)
|
||||||
|
else:
|
||||||
|
port_int = None
|
||||||
|
|
||||||
|
host = _normalize_host(host, scheme)
|
||||||
|
|
||||||
|
if normalize_uri and path:
|
||||||
|
path = _remove_path_dot_segments(path)
|
||||||
|
path = _encode_invalid_chars(path, _PATH_CHARS)
|
||||||
|
if normalize_uri and query:
|
||||||
|
query = _encode_invalid_chars(query, _QUERY_CHARS)
|
||||||
|
if normalize_uri and fragment:
|
||||||
|
fragment = _encode_invalid_chars(fragment, _FRAGMENT_CHARS)
|
||||||
|
|
||||||
|
except (ValueError, AttributeError) as e:
|
||||||
|
raise LocationParseError(source_url) from e
|
||||||
|
|
||||||
|
# For the sake of backwards compatibility we put empty
|
||||||
|
# string values for path if there are any defined values
|
||||||
|
# beyond the path in the URL.
|
||||||
|
# TODO: Remove this when we break backwards compatibility.
|
||||||
|
if not path:
|
||||||
|
if query is not None or fragment is not None:
|
||||||
|
path = ""
|
||||||
|
else:
|
||||||
|
path = None
|
||||||
|
|
||||||
|
return Url(
|
||||||
|
scheme=scheme,
|
||||||
|
auth=auth,
|
||||||
|
host=host,
|
||||||
|
port=port_int,
|
||||||
|
path=path,
|
||||||
|
query=query,
|
||||||
|
fragment=fragment,
|
||||||
|
)
|
||||||
42
venv/lib/python3.12/site-packages/urllib3/util/util.py
Normal file
42
venv/lib/python3.12/site-packages/urllib3/util/util.py
Normal file
@@ -0,0 +1,42 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import typing
|
||||||
|
from types import TracebackType
|
||||||
|
|
||||||
|
|
||||||
|
def to_bytes(
|
||||||
|
x: str | bytes, encoding: str | None = None, errors: str | None = None
|
||||||
|
) -> bytes:
|
||||||
|
if isinstance(x, bytes):
|
||||||
|
return x
|
||||||
|
elif not isinstance(x, str):
|
||||||
|
raise TypeError(f"not expecting type {type(x).__name__}")
|
||||||
|
if encoding or errors:
|
||||||
|
return x.encode(encoding or "utf-8", errors=errors or "strict")
|
||||||
|
return x.encode()
|
||||||
|
|
||||||
|
|
||||||
|
def to_str(
|
||||||
|
x: str | bytes, encoding: str | None = None, errors: str | None = None
|
||||||
|
) -> str:
|
||||||
|
if isinstance(x, str):
|
||||||
|
return x
|
||||||
|
elif not isinstance(x, bytes):
|
||||||
|
raise TypeError(f"not expecting type {type(x).__name__}")
|
||||||
|
if encoding or errors:
|
||||||
|
return x.decode(encoding or "utf-8", errors=errors or "strict")
|
||||||
|
return x.decode()
|
||||||
|
|
||||||
|
|
||||||
|
def reraise(
|
||||||
|
tp: type[BaseException] | None,
|
||||||
|
value: BaseException,
|
||||||
|
tb: TracebackType | None = None,
|
||||||
|
) -> typing.NoReturn:
|
||||||
|
try:
|
||||||
|
if value.__traceback__ is not tb:
|
||||||
|
raise value.with_traceback(tb)
|
||||||
|
raise value
|
||||||
|
finally:
|
||||||
|
value = None # type: ignore[assignment]
|
||||||
|
tb = None
|
||||||
124
venv/lib/python3.12/site-packages/urllib3/util/wait.py
Normal file
124
venv/lib/python3.12/site-packages/urllib3/util/wait.py
Normal file
@@ -0,0 +1,124 @@
|
|||||||
|
from __future__ import annotations
|
||||||
|
|
||||||
|
import select
|
||||||
|
import socket
|
||||||
|
from functools import partial
|
||||||
|
|
||||||
|
__all__ = ["wait_for_read", "wait_for_write"]
|
||||||
|
|
||||||
|
|
||||||
|
# How should we wait on sockets?
|
||||||
|
#
|
||||||
|
# There are two types of APIs you can use for waiting on sockets: the fancy
|
||||||
|
# modern stateful APIs like epoll/kqueue, and the older stateless APIs like
|
||||||
|
# select/poll. The stateful APIs are more efficient when you have a lots of
|
||||||
|
# sockets to keep track of, because you can set them up once and then use them
|
||||||
|
# lots of times. But we only ever want to wait on a single socket at a time
|
||||||
|
# and don't want to keep track of state, so the stateless APIs are actually
|
||||||
|
# more efficient. So we want to use select() or poll().
|
||||||
|
#
|
||||||
|
# Now, how do we choose between select() and poll()? On traditional Unixes,
|
||||||
|
# select() has a strange calling convention that makes it slow, or fail
|
||||||
|
# altogether, for high-numbered file descriptors. The point of poll() is to fix
|
||||||
|
# that, so on Unixes, we prefer poll().
|
||||||
|
#
|
||||||
|
# On Windows, there is no poll() (or at least Python doesn't provide a wrapper
|
||||||
|
# for it), but that's OK, because on Windows, select() doesn't have this
|
||||||
|
# strange calling convention; plain select() works fine.
|
||||||
|
#
|
||||||
|
# So: on Windows we use select(), and everywhere else we use poll(). We also
|
||||||
|
# fall back to select() in case poll() is somehow broken or missing.
|
||||||
|
|
||||||
|
|
||||||
|
def select_wait_for_socket(
|
||||||
|
sock: socket.socket,
|
||||||
|
read: bool = False,
|
||||||
|
write: bool = False,
|
||||||
|
timeout: float | None = None,
|
||||||
|
) -> bool:
|
||||||
|
if not read and not write:
|
||||||
|
raise RuntimeError("must specify at least one of read=True, write=True")
|
||||||
|
rcheck = []
|
||||||
|
wcheck = []
|
||||||
|
if read:
|
||||||
|
rcheck.append(sock)
|
||||||
|
if write:
|
||||||
|
wcheck.append(sock)
|
||||||
|
# When doing a non-blocking connect, most systems signal success by
|
||||||
|
# marking the socket writable. Windows, though, signals success by marked
|
||||||
|
# it as "exceptional". We paper over the difference by checking the write
|
||||||
|
# sockets for both conditions. (The stdlib selectors module does the same
|
||||||
|
# thing.)
|
||||||
|
fn = partial(select.select, rcheck, wcheck, wcheck)
|
||||||
|
rready, wready, xready = fn(timeout)
|
||||||
|
return bool(rready or wready or xready)
|
||||||
|
|
||||||
|
|
||||||
|
def poll_wait_for_socket(
|
||||||
|
sock: socket.socket,
|
||||||
|
read: bool = False,
|
||||||
|
write: bool = False,
|
||||||
|
timeout: float | None = None,
|
||||||
|
) -> bool:
|
||||||
|
if not read and not write:
|
||||||
|
raise RuntimeError("must specify at least one of read=True, write=True")
|
||||||
|
mask = 0
|
||||||
|
if read:
|
||||||
|
mask |= select.POLLIN
|
||||||
|
if write:
|
||||||
|
mask |= select.POLLOUT
|
||||||
|
poll_obj = select.poll()
|
||||||
|
poll_obj.register(sock, mask)
|
||||||
|
|
||||||
|
# For some reason, poll() takes timeout in milliseconds
|
||||||
|
def do_poll(t: float | None) -> list[tuple[int, int]]:
|
||||||
|
if t is not None:
|
||||||
|
t *= 1000
|
||||||
|
return poll_obj.poll(t)
|
||||||
|
|
||||||
|
return bool(do_poll(timeout))
|
||||||
|
|
||||||
|
|
||||||
|
def _have_working_poll() -> bool:
|
||||||
|
# Apparently some systems have a select.poll that fails as soon as you try
|
||||||
|
# to use it, either due to strange configuration or broken monkeypatching
|
||||||
|
# from libraries like eventlet/greenlet.
|
||||||
|
try:
|
||||||
|
poll_obj = select.poll()
|
||||||
|
poll_obj.poll(0)
|
||||||
|
except (AttributeError, OSError):
|
||||||
|
return False
|
||||||
|
else:
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def wait_for_socket(
|
||||||
|
sock: socket.socket,
|
||||||
|
read: bool = False,
|
||||||
|
write: bool = False,
|
||||||
|
timeout: float | None = None,
|
||||||
|
) -> bool:
|
||||||
|
# We delay choosing which implementation to use until the first time we're
|
||||||
|
# called. We could do it at import time, but then we might make the wrong
|
||||||
|
# decision if someone goes wild with monkeypatching select.poll after
|
||||||
|
# we're imported.
|
||||||
|
global wait_for_socket
|
||||||
|
if _have_working_poll():
|
||||||
|
wait_for_socket = poll_wait_for_socket
|
||||||
|
elif hasattr(select, "select"):
|
||||||
|
wait_for_socket = select_wait_for_socket
|
||||||
|
return wait_for_socket(sock, read, write, timeout)
|
||||||
|
|
||||||
|
|
||||||
|
def wait_for_read(sock: socket.socket, timeout: float | None = None) -> bool:
|
||||||
|
"""Waits for reading to be available on a given socket.
|
||||||
|
Returns True if the socket is readable, or False if the timeout expired.
|
||||||
|
"""
|
||||||
|
return wait_for_socket(sock, read=True, timeout=timeout)
|
||||||
|
|
||||||
|
|
||||||
|
def wait_for_write(sock: socket.socket, timeout: float | None = None) -> bool:
|
||||||
|
"""Waits for writing to be available on a given socket.
|
||||||
|
Returns True if the socket is readable, or False if the timeout expired.
|
||||||
|
"""
|
||||||
|
return wait_for_socket(sock, write=True, timeout=timeout)
|
||||||
Reference in New Issue
Block a user